ГЛАВА 8
Дополнительные возможности файловых систем
Особая роль файловой системы, связанная с долговременным хранением информации, в том числе критически важных программ и данных пользователей и самой ОС, порождает повышенные требования к ее надежности и отказоустойчивости. Эти важные свойства обеспечиваются за счет применения восстанавливаемых файловых систем и отказоустойчивых дисковых массивов.
Модели файла и файловых операций, применяемые первоначально к хранимым на дисках данным, оказались удобным средством работы с данными любой природы, поэтому со временем они нашли применение и в других областях, таких как управление устройствами ввода-вывода и обмен данными между процессами. С другой стороны, и на классическую файловую систему оказало влияние развитие других подсистем ОС, в частности подсистемы управления памятью, за счет средств которой стало возможным отображение файлов в оперативную память и работа с дисковыми данными как с обычными переменными.
Специальные файлы и аппаратные драйверы
Специальные файлы как универсальный интерфейс
Понятие «специальный файл» появилось в операционной системе UNIX. Специальный файл, называемый также виртуальным файлом, связан с некоторым устройством ввода-вывода и представляет его для остальной части операционной системы и прикладных процессов в виде неструктурированного набора байт, то есть в виде обычного файла. Однако в отличие от обычного файла специальный файл не хранит статичные данные, а является интерфейсом к одному из аппаратных драйверов ОС.
Использование специальных файлов во многих случаях существенно упрощает программирование операций с внешними устройствами. Со специальным файлом можно работать так же, как и с обычным, то есть открывать, считывать из него или же записывать в него определенное количество байт, а после завершения операции закрывать. Для этого используются привычные многим программистам системные вызовы для работы с обычными файлами: open, create, read, write и close. Кроме того, имеется несколько системных вызовов, используемых только при работе со специальными файлами, например вызов loctl, с помощью которого можно передать команду контроллеру устройства. Для того чтобы вывести на алфавитно-цифровой терминал, с которым связан специальный файл /dev/tty3, сообщение «Hello, friendsl», достаточно открыть этот файл с помощью системного вызова open:
fd =open (7dev/tty3", 2)
Затем можно вывести сообщение с помощью системного вызова write:
write (fd, "Hello, friends! ", 15)
Для устройств прямого доступа имеет смысл также указатель текущего положения в файле, которым можно управлять с помощью системного вызова lseek.
Очевидно, что представление устройства в виде файла и использование для управления устройством файловых системных вызовов позволяет выполнять только простые операции управления, которые сводятся к передаче в устройство последовательности байт. Для некоторых устройств такие операции вполне адекватны—в основном это устройства, отображающие строки символов (алфавитно-цифровые терминалы, алфавитно-цифровые принтеры) или принимающие от пользователя строки символов (клавиатура). Форматирование ввода-вывода в устройствах этого класса осуществляется с помощью служебных символов начала кодовой таблицы и их последовательностей, например для перевода строки и возврата каретки принтера или терминала достаточно к последовательности символов текста добавить восьмеричные коды <12> <15>.
Для устройств с более сложной организацией информации, например графических дисплеев, от управляющего интерфейса требуется поддержка более сложных операций, таких как заполнение цветом области или вывод на экран основных графических примитивов, и аппаратные драйверы таких устройств их действительно выполняют. Тем не менее файловый интерфейс, оперирующий только с неструктурированным потоком байт, оказывается полезным и для устройств со сложной организацией информации. Такой интерфейс в силу своей простоты и универсальности дает возможность строить над ним другой, более сложный интерфейс с произвольной организацией.
Файловый интерфейс доступен пользователю, поэтому прикладной программист может воспользоваться им для создания собственного интерфейса к какому-либо устройству, обходя лежащие над аппаратным драйвером данного устройства слои высокоуровневых драйверов. Например, если прикладного программиста по какой-то причине не устраивают файловые системы, поддерживаемые некоторой операционной системой, то он может обратиться к диску как к устройству с помощью интерфейса специального файла, который будет вызывать аппаратный драйвер диска, поддерживающий модель диска в виде последовательности байт (рис. 8.1). С помощью такого аппаратного драйвера прикладной программист может организовать данные в каком-либо разделе диска оригинальным способом, соответствующим его потребностям. При этом ему не нужно разрабатывать высокоуровневый драйвер для собственной файловой системы, что является более сложной задачей по сравнению с разработкой прикладной программы.

Рис. 8.1. Работа с диском как со специальным файлом
В UNIX специальные файлы традиционно помещаются в каталог /dev, хотя ничто не мешает созданию их в любом каталоге файловой системы. При появлении нового устройства и соответственно нового драйвера администратор системы может создать новую запись с помощью команды mknod. Например, следующая команда создает блок-ориентированный специальный файл для представления третьего раздела на втором диске четвертого SCSI-контроллера:
mknod /dev/dsk/scs1 b 32 33
Связь специального файла с драйвером устанавливается за счет информации, находящейся в индексном дескрипторе специального файла.
Во-первых, в индексном дескрипторе хранится признак того, что файл является специальным, причем этот признак позволяет различить класс соответствующего устройству драйвера, то есть он определяет, является ли драйвер байт-ориентированным или блок-ориентированным.
Во-вторых, в индексном дескрипторе хранится адресная информация, позволяющая выбрать нужный драйвер и нужное устройство. Эта информация заменяет стандартную адресную информацию обычного файла, состоящую из номеров блоков файла на диске.
Адресная информация специального файла состоит из двух элементов:
Значение major (номер драйвера) определяет выбор драйвера, обслуживающего данный специальный файл, а значение minor (номер устройства) передается драйверу в качестве параметра вызова и указывает ему на одно из нескольких однотипных устройств, которыми драйвер может управлять. Например, для дисковых драйверов номер устройства задает не только диск, но и раздел на диске.
В приведенном выше примере команды создания специального файла /dev/dsk/scsi аргумент b определяет создание специального файла для блок-ориентированного драйвера, аргумент 32 определяет номер драйвера, который будет вызываться при открытии устройства /dev/dsk/scsi, а аргумент 33 декодируется самим драйвером (в нем закодированы данные о том, что нужно управлять третьим разделом на втором диске четвертого SCSI-контроллера).
ОС UNIX использует для хранения информации об установленных аппаратных драйверах две системные таблицы:
Номер драйвера (major) является индексом соответствующей таблицы. При открытии специального файла операционная система обнаруживает, что она имеет дело со специальным файлом только после того, как прочитает с диска или найдет в системном буфере его индексный дескриптор. При этом она узнает, является ли вызываемый драйвер блок- или байт-ориентированным, после чего использует номер драйвера для обращения к определенной строке одной из двух таблиц: bdevsw или cdevsw (рис. 8.2).
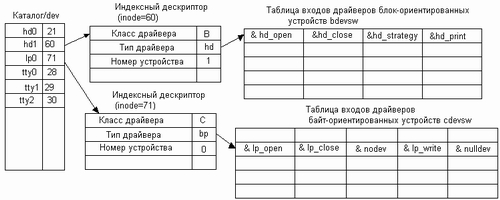
Рис. 8.2. Организация связи ядра UNIX с драйверами
Таблицы bdevsw и cdevsw содержат адреса программных секций драйверов, причем одна строка таблицы описывает один драйвер. Такая организация логической связи между ядром UNIX и драйверами позволяет легко настраивать систему на новую конфигурацию внешних устройств путем модификации таблиц bdevsw и cdevsw.
Концепция специальных файлов ОС UNIX была реализована во многих операционных системах, хотя для связи с драйверами в них часто используются механйзмы, отличные от описанного выше. Так, в OG Windows NT для связи виртуальных устройств (аналогов специальных файлов) с драйверами используется механизм объектов. При этом в объектах-устройствах имеются ссылки на объекты-драйверы, за счет чего при открытии виртуального устройства система находит нужный драйвер.
Структурирование аппаратных драйверов
Аппаратные драйверы можно назвать «истинными» драйверами, так как в отличие от высокоуровневых драйверов, они выполняют все традиционные функции по управлению устройствами, включая обработку прерываний и непосредственное взаимодействие с устройствами ввода-вывода.
Более точно, аппаратный драйвер имеет дело не с устройством, а с его контроллером. Контроллер, как правило, выполняет достаточно простые функции, например преобразует поток бит в блоки данных и осуществляют контроль и исправление возникающих в процессе обмена данными ошибок. Каждый контроллер имеет несколько регистров, которые используются для взаимодействия с центральным процессором. Обычно у контроллера имеются регистры данных, через которые осуществляется обмен данными между драйвером и устройством, и управляющие регистры, в которые драйвер помещает команды. В некоторых типах компьютеров регистры являются частью физического адресного пространства, при этом в таких компьютерах отсутствуют специальные инструкции ввода-вывода — их функции выполняют инструкции обмена с памятью. В других компьютерах адреса регистров ввода-вывода, называемых часто портами, образуют собственное адресное пространство за счет введения специальных операций ввода-вывода (например, команд IN и OUT в процессорах Intel Pentium).
Внешнее устройство в общем случае состоит из механических и электронных компонентов. Обычно электронная часть устройства сосредоточивается в его контроллере, хотя это и не обязательно. Некоторые контроллеры могут управлять несколькими устройствами. Если интерфейс между контроллером и устройством стандартизован, то независимые производители могут выпускать как совместимые со стандартом контроллеры, так и совместимые устройства.
Аппаратный драйвер выполняет ввод-вывод данных, записывая команды в регистры контроллера. Например, контроллер диска персонального компьютера принимает такие команды, как READ, WRITE, SEEK, FORMAT и т. д. Когда команда принята, процессор оставляет контроллер и занимается другой работой. По завершении команды контроллер генерирует запрос прерывания для того, чтобы передать управление процессором операционной системе, которая должна проверить результаты операции. Процессор получает результаты и данные о статусе устройства, читая информацию из регистров контроллера.
Аппаратные драйверы могут в своей работе опираться на микропрограммные драйверы (firmware drivers), поставляемые производителем компьютера и находящиеся в постоянной памяти компьютера (в персональных компьютерах это программное обеспечение получило название BIOS — Basic Input-Output System). Микропрограммное обеспечение представляет собой самый нижний слой программного обеспечения компьютера, управляющий устройствами. Модули этого слоя выполняют функции транслирующих драйверов и конверторов, экранирующих специфические интерфейсы аппаратуры дайной компьютерной системы от операционной системы и ее драйверов.
Драйвер выполняет операцию ввода-вывода, которая представляет собой обмен с устройством заданным количеством байт по заданному адресу оперативной памяти (и адресу устройства ввода-вывода в том случае, когда оно является адресуемым). Примерами операций ввода-вывода могут служить чтение нескольких смежных секторов диска или печать на принтере нескольких строк документа. Операция задается одним системным вызовом ввода-вывода, например read или write.
Операция отрабатывается драйвером в общем случае за несколько действий. Так, при выводе документа на принтер драйвер сначала выполняет некоторые начальные действия, приводящие принтер в состояние готовности к печати, затем выводит в буфер принтера первую порцию данных и ждет сигнала прерывания, который свидетельствует об окончании контроллером принтера печати этой порции данных. После этого в буфер выводится вторая порция данных и т. д.
Так как большинство действий драйвер выполняет асинхронно по отношению к вызвавшему драйвер процессу, то драйверу запрещается изменять контекст текущего процесса (который в общем случае отличается от вызвавшего). Кроме того, драйвер не может запрашивать у ОС выделения дополнительных ресурсов или отказываться от уже имеющихся у текущего процесса — драйвер должен пользоваться теми системными ресурсами, которые выделяются непосредственно ему (а не процессу) на этапе загрузки в систему или старта очередной операции ввода-вывода. Соблюдение этих условий необходимо для корректного распределения ресурсов между процессами — каждый получает то, что запрашивал и что непосредственно ему выделила операционная система.
В подсистеме ввода-вывода каждой современной операционной системы существует стандарт на структуру драйверов. Несмотря на специфику управляемых устройств, в любом драйвере можно выделить некоторые общие части, выполняющие определенный набор действий, такие как запуск операции ввода-вывода, обработка прерывания от контроллера устройства и т. п. Рассмотрим принципы структуризации драйверов на примере операционных систем Windows NT и
UNIX.
Особенностью Windows NT является общая структура драйверов любого уровня и расширенное толкование самого понятия «драйвер». В Windows NT и аппаратный драйвер диска, и высокоуровневый драйвер файловой системы построены единообразно, поэтому другие модули ОС взаимодействуют с драйверами одним и тем же способом.
Драйвер Windows NT состоит из следующих (не обязательно всех) процедур:
Адреса всех перечисленных процедур представляют собой точки входа в драйвер, известные менеджеру ввода-вывода. Эти адреса хранятся в объекте, создаваемом для каждого драйвера Windows NT, и менеджер использует такие объекты для вызова той или иной функции драйвера. Процедура диспетчеризации используется как общая точка входа для нескольких процедур обмена данными (чтение, запись, управление и т. п.), набор которых изменяется от драйвера к драйверу и, следовательно, не может быть стандартизован.
Большое количество стандартизованных функций драйвера Windows NT обусловлено желанием разработчиков этой ОС использовать единую модель для драйверов всех типов, от сравнительно простого аппаратного драйвера СОМ-порта до весьма сложного драйвера файловой системы NTFS. В результате некоторые функции для некоторого драйвера могут оказаться невостребованными. Например, для высокоуровневых драйверов не нужна секция обработки прерываний ISR, так как прерывания от устройства обрабатывает соответствующий низкоуровневый драйвер, который затем вызывает высокоуровневый драйвер с помощью менеджера ввода-вывода, не используя механизм прерываний.
Рассмотрим особенности вызова функций аппаратного драйвера Windows NT на примере выполнения операции чтения с -диска (рис. 8.3). Диск рассматривается в этой операции как виртуальное устройство, следовательно, слой драйверов файловых систем в выполнении операции не участвует.
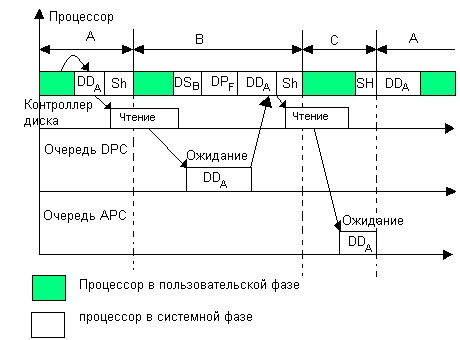
Рис. 8.3. Работа аппаратного драйвера Windows NT
Пусть в некоторый момент времени выполнения в пользовательской фазе процесс А запрашивает с помощью соответствующего системного вызова чтение некоторого количества блоков диска, начиная с блока определенного номера. Процесс А при этом переходит в состояние ожидания завершения запрошенной операции, а планировщик/диспетчер Sh активизирует ожидавший выполнения процесс В.
При выполнении системного вызова управление с помощью менеджера ввода-вывода передается стартовой функции драйвера диска DD, которая проверяет, открыт ли виртуальный файл диска и готов ли контроллер диска к выполнению операции обмена данными. После возврата управления от стартовой процедуры менеджер вызывает функцию диспетчеризации драйвера, которой передается пакет запроса ввода-вывода IRP, содержащий параметры операции — начальный адрес и количество блоков диска. В результате функция диспетчеризации драйвера вызывает внутреннюю функцию чтения данных с диска, которая передает контроллеру диска запрос на чтение первой порции запрошенных данных. На рисунке работа всех перечисленных функций показана как один этап работы драйвера DD. Тот факт, что драйвер DD выполняет работу для процесса А, отмечен на рисунке нижним индексом, то есть как DDA.
После завершения чтения порции данных контроллер генерирует аппаратный запрос прерывания, который вызывает процедуру обработки прерываний драйвера диска ISR, имеющую высокий уровень IRQL. После короткого периода выполнения самых необходимых действий с регистрами контроллера (этот период для упрощения рисунка не показан) эта процедура делает запрос на выполнение менее срочной DPC-процедуры драйвера, которая должна выполнить передачу имеющейся у контроллера порции данных в системную область. Запрос на выполнение DPC-процедуры драйвера DDA некоторое время стоит в очереди уровня DPC, так как в это время в процессоре выполняются более приоритетные ISR-процедуры DSB (драйвера стриммера для процесса В) и DPF (драйвера принтера для процесса F). После завершения этих процедур начинается выполнение DPC-процедуры драйвера DDA, при этом текущим для ОС процессом является процесс В, сменивший процесс А и прерванный на время ISR-процедурами. Однако на выполнение DPC-процедуры драйвера диска это обстоятельство не оказывает никакого влияния, так как данные перемещаются в системную область, общую для всех процессов.
Кроме перемещения данных DPC-процедура драйвера выдает контроллеру диска указание о чтении второй и последней для операции порции данных (если контроллер использует режим прямого доступа к памяти и самостоятельно перемещает данные из своего буфера в системный буфер, то запуск нового действия будет единственной обязанностью DPC-процедуры). Контроллер выполняет чтение и выдает новый запрос прерывания, который снова вызывает процедуру обработки прерываний драйвера диска. Данная процедура ставит в IRQL-очереди две процедуры: DPC-процедуру, которая, как и в предыдущем цикле чтения, должна переписать данные из буфера контроллера в системный буфер, и АРС- процедуру, которая должна переписать все полученные данные из системного буфера в заданную пользовательскую область памяти процесса А.
DPC-процедура вызывается раньше, так как имеет более высокий приоритет в очереди диспетчера прерываний. АРС-
процедура ждет дольше, так как она имеет более низкий приоритет и, кроме того, она обязана ждать до тех пор, пока текущим процессом не станет процесс А. DPC-процедура после выполнения своей работы фиксирует в операционной системе событие — завершение операции ввода-вывода. По наступлении события вызывается планировщик потоков, который переводит процесс А в состояние готовности (но не ставит его на выполнение, так как текущий процесс С еще не исчерпал своего кванта времени). И только после того, как планировщик снимает процесс С с выполнения и делает текущим процесс А, вызывается АРС-
процедура, которая вытесняет пользовательский код процесса А, имеющий низший приоритет IRQL. АРС-
процедура переписывает считанные с диска данные из системного буфера в область данных процесса А. Для доступа к системному буферу АРС-
процедура должна иметь нужный уровень привилегий. После завершения работы АРС-
процедуры управление возвращается пользовательскому коду приложения А, который обрабатывает запрошенные у диска данные.
В ОС UNIX вместо одной общей структуры драйвера существуют две стандартные структуры, одна — для блок-ориентированных драйверов, а другая — для байт-ориентированных. По этой причине в UNIX используются две таблицы, bdevsw и cdevsw, хранящие точки входа в функции драйверов. Каждая из таблиц имеет свою структуру, соответствующую стандартным функциям блок-ориентированных и байт-ориентированных драйверов.
Блок-ориентированные драйверы
Драйвер блок-ориентированного устройства состоит из следующих функций:
Указатели на эти функции (то есть их адреса) составляют строку в таблице bdevsw, описывающую один драйвер системы. Ядро UNIX вызывает нужную функцию драйвера, передавая ей параметры, необходимые для работы. Например, при вызове функции open ей передается номер устройства (minor), режим открытия (для чтения, для записи, для чтения и записи и т. д.), а также указатель на идентификаторы безопасности процесса, открывающего файл.
Процедуры обработки прерываний драйвера в таблице bdevsw не указываются, их адреса помещаются в специальную системную структуру — таблицу прерываний. В UNIX все обработчики прерываний, в том числе и обработчики прерываний аппаратных драйверов, состоят из двух процедур, называемых соответственно top_half — верхняя часть обработчика прерываний и bottom_half — нижняя часть обработчика прерываний. Верхняя часть обработчика прерываний соответствует по назначению ISR-процедуре драйвера Windows NT — она вызывается при возникновении аппаратного запроса прерывания от устройства. В обязанности верхней части входит быстрая реакция на событие в устройстве, вызвавшее генерирование сигнала прерывания. При обработке верхних половин все прерывания с более низкими приоритетами блокируются аппаратно, за счет управления контроллером прерываний (или аналогичным по назначению блоком компьютера). Верхняя половина отвечает также за постановку в очередь на выполнение нижней половины обработчика прерываний драйвера, который выполняет менее срочную и более трудоемкую работу.
Нижние половины драйверов выполняются с низким уровнем приоритета, так что любые запросы прерываний устройств могут прервать их обработку. Нижние половины обработчиков прерываний драйверов UNIX по назначению соответствуют DPC-процедурам драйверов Windows NT. Часто единственной обязанностью верхней половины обработчика прерываний является постановка в очередь нижней половины для последующего выполнения.
Примером разделения функций между верхней и нижней половинами является обработчик прерываний от таймера. Верхняя часть, вызываемая 100 раз в секунду, наращивает переменную, хранящую количество тактов системных часов с момента последней загрузки системы, а также две переменные, подсчитывающие, сколько тактов прошло с момента последнего вызова нижней половины и сколько из них пришлось на период работы в режиме системы. Затем верхняя половина ставит в очередь диспетчера прерываний нижнюю половину и завершает свою работу. Нижняя половина обработчика прерываний таймера занимается вычислением статистики на основании данных о тактах, собранных верхней половиной. Нижняя половина вычисляет такие статистические показатели, как средняя загрузка системы в пользовательском и системном режимах, обновляет глобальную переменную системного времени, а также уменьшает оставшееся значение кванта времени текущего процесса. Затем нижняя половина просматривает очередь процедур, ожидающих своего вызова по времени, в число которых входит и планировщик процессов.
Функция стратегии драйвера strategy выполняет чтение и запись блока данных на основании информации в буфере — особой структуре ядра с именем buf, управляющей обменом данных с диском. Функция strategy выполняет обмен только с системной памятью, так как блок-ориентированный драйвер непосредственно не взаимодействует с пользовательским процессом. Между ним и пользовательским процессом всегда работает промежуточный программный слой или слои — либо слой дискового кэша вместе со слоем файловой системы, либо слой байт-ориентированного драйвера диска, с помощью которого пользовательский процесс может открыть специальный файл, соответствующий диску.
В число наиболее важных элементов структуры buf входят следующие:
Функция strategy при вызове получает указатель на структуру buf, описывающую требуемую операцию. На рис. 8.4 приведен пример блок-схемы двух функций драйвера диска — стратегии (hd_strategy) и нижней половины обработчика прерываний (hd_bottom). Функция hd_strategy преобразует логический номер блока в номера цилиндра, головки и сектора и помещает эту информацию в заголовок запроса операции для передачи ее контроллеру диска. В заголовок запроса помещается также другая информация, необходимая для работы контроллера, — это операция чтения или записи, адрес системной памяти, куда нужно поместить прочитанную информацию или откуда контроллеру нужно считать записываемые данные. Драйвер ведет две очереди для передачи запросов на выполнение операций чтения и записи контроллеру диска: рабочую очередь, в которой находятся обрабатываемые контроллером запросы, и очередь приостановленных запросов, куда помещаются новые запросы в том случае, если рабочая очередь заполнена, а ее размер зависит от возможностей контроллера по параллельной обработке запросов.
После помещения нового запроса в одну из очередей функция стратегии разрешает прерывания от данного устройства и завершает свою работу. Всю дальнейшую работу по обслуживанию поставленных в очереди запросов выполняют контроллер и обработчики прерываний. После выполнения запроса, когда данные либо записаны в системную память (чтение), либо переписаны из системной памяти в .блок диска (запись), контроллер генерирует сигнал прерывания. По этому сигналу вызывается верхняя часть обработчика прерываний дискового драйвера (на рисунке не показана), которая просто ставит в очередь диспетчера прерываний нижнюю часть обработчика прерываний диска hd_bottom. Эта процедура считывает данные из регистра управления контроллера для того, чтобы определить, корректно ли завершилась запрошенная операция. Если признак ошибки в регистре не установлен, то в рабочую очередь контроллера помещается следующий заголовок запроса из очереди приостановленных запросов, а по завершении операции вызывается функция iodone, указатель на которую имеется в буфере buf операции.
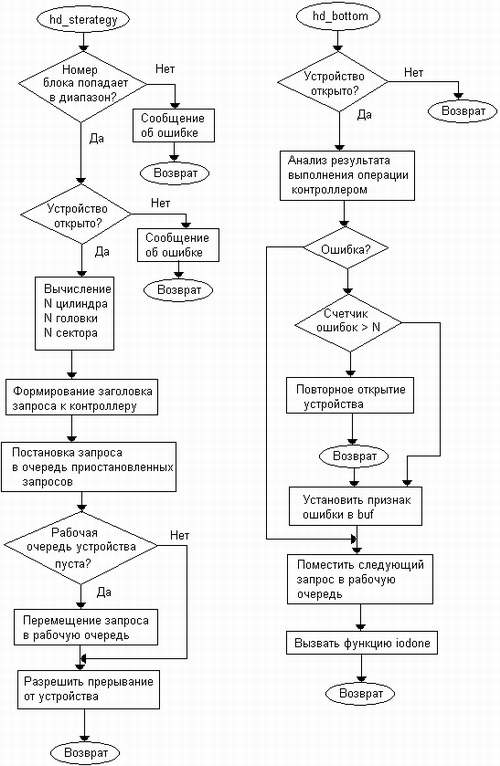
Рис. 8.4. Блок-схема драйвера диска
Байт-ориентированные драйверы
Драйвер байт-ориентированного устройства состоит из следующих стандартных функций:
Функции чтения и записи данных выполняют обмен заданной последовательности байт из буфера в области пользователя с контроллером символьного устройства.
Функция управления ioctl обеспечивает интерфейс к драйверу устройства, который выходит за рамки возможностей функций read и write. С помощью функции ioctl обычно устанавливается режим работы устройства, например задаются параметры СОМ-порта, такие как разрядность символов, количество стоповых бит, режим проверки четности и т. п.
Функции, используемые для отображения специального файла в виртуальную память, рассматриваются ниже в разделе «Отображаемые в память файлы».
Если драйвер не поддерживает какую-либо из стандартных функций, то в таблицу bdevsw помещается указатель на специальную функцию nodev ядра. Например, драйвер принтера может не поддерживать функцию read. Функция nodev при вызове просто возвращает код ошибки ENODEV и на этом завершает свою работу. Для тех случаев, когда функция должна обязательно поддерживаться (примерами таких функций являются функции open и cl ose), но она не выполняет ника-• кой полезной работы, в операционной системе имеется функция nul I dev, которая похожа на функцию nodev, но в отличие от нее возвращает значение 0, которое во всех системных вызовах означает успешное завершение.
На рис. 8.5 показано взаимодействие функции записи драйвера байт-ориентированного устройства с обработчиком прерываний. Функция записи осуществляет передачу данных из пользовательского буфера процесса, выдавшего запрос на обмен, в системный буфер, организованный в виде очереди байт. Передача байт идет до тех пор, пока системный буфер не заполнится до некоторого, заранее определенного в драйвере уровня. Затем функция записи драйвера приостанавливается, выполнив системную функцию sleep, переводящую процесс, в рамках которого работает функция записи write, в состояние ожидания.
Если при очередном прерывании оказывается, что очередь байт уменьшилась до определенной нижней границы, то обработчик прерываний активизирует секцию записи драйвера путем обращения к системной функции wakeup для перевода процесса в состояние готовности. Аналогично организована работа драйвера при чтении данных с устройства.
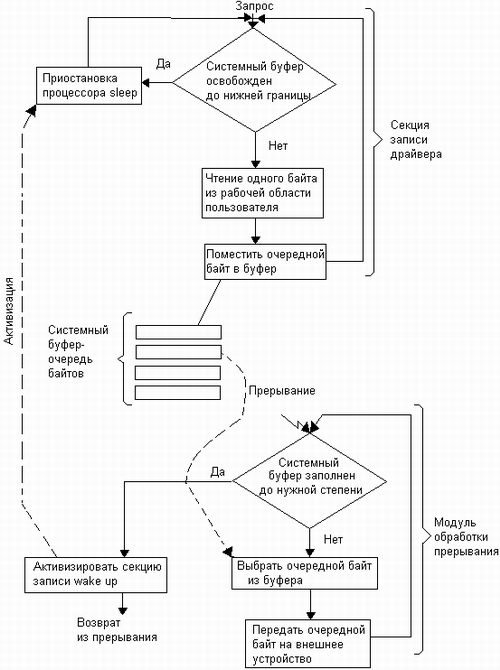
Рис. 8.5. Взаимодействие секции записи драйвера с модулем обработки прерывания
Отображение файла в виртуальное адресное пространство процесса применяется для упрощения программирования. Такое отображение позволяет работать с данными файла с помощью адресных указателей как с обычными переменными программы, без использования несколько громоздких файловых функций read, write и Iseek. При отображении файлов в память широко используются механизмы подсистемы виртуальной памяти.
Действительно, подсистема виртуальной памяти связывает некоторый сегмент виртуального адресного пространства процесса с некоторым файлом или частью файла. Так, кодовый сегмент и сегмент инициализированных данных всегда связаны с файлом, в котором находится исполняемый модуль приложения. Сегменты стека и неинициализированных данных связаны с выделенными им областями системного страничного файла. При обращении кода приложения к некоторой переменной сегмента данных подсистема виртуальной памяти читает с диска данные из блоков, соответствующих странице виртуального адресного пространства, содержащей эту переменную, и переносит данные в оперативную память, если на момент обращения эта страница там отсутствовала. В сущности, подсистема виртуальной памяти выполняет обмен данными с файлом по запросу, только этот запрос формулируется косвенно, а не путем явного описания области файла, с которой нужно выполнить обмен данными, как это происходит при выполнении операций read или write.
Механизм отображения файлов в память использует возможности системы виртуальной памяти для файлов, содержащих произвольные данные (а не только данные исполняемого модуля программы).
Отображение данных файла в память осуществляется с помощью системного вызова, который указывает, какую часть какого файла нужно отобразить в память, а также задает виртуальный адрес, с которого должен начинаться новый сегмент виртуальной памяти процесса. Подсистема управления виртуальной памятью создает по этому системному вызову новый сегмент процесса, в дескриптор которого помещает указатель на открытый отображаемый файл. При первом же обращении приложения по виртуальному адресу, принадлежащему новому сегменту, происходит страничный отказ, при обработке которого из отображаемого файла читается несколько блоков и данные из них помещаются в физическую страницу.
В UNIX SystemV Release 4 отображение файла в память выполняется с помощью системного вызова mmар.
Этот вызов имеет следующие аргументы:
Для сравнения рассмотрим две функции, которые выполняют одни и те же действия с файлом ,но с помощью разных средств — функция f f i 1 е использует традиционные файловые операции, а функция fmap работает с отображенным в память файлом.
Пусть файл /data/base 1 .dat состоит из записей фиксированной длины, каждая из которых включает переменную, отражающую значение баланса предприятия (переменная balance) и признак типа баланса (переменная mode):
/* Структура записи */
struct record {
unsigned long balance;
unsigned short mode:
}:
/* Функция ffile использует для работы файловые операции */
finction ffile ()
{
int fd;
struct record r:
/* Открытие файла и "пролистывание" первых 24 записей и чтение 25-й */
fd - openC'/data/basel.dat". 0_RDWR, 0):
lseek (fd, 24 * sizeof(struct record). SEEKJET):
read(fd, &r. sizeof(struct record));
/* Модификация данных 25-й записи */
r.balance - 1000000; г.mode - 3:
/* Возвращение указателя на начало 25-й записи, так как в результате чтения он переместился на начало 26-й*/
lseek (fd. 24 * sizeof (struct record). SEEKJET);
/* Запись модифицированных данных и закрытие файла*/
write (fd. &r. sizeof(struct record)): close (fd):
}
/* Функция fmap отображает файл в паиять */
function fmap ():
{
int fd;
struct record *rp:
/* rp является адресом записи recored */
int len = 1000 * sizeoftstruct record);
/* len хранит длину файла.
состоящего из 1000 записей */
/* Открытие файла и отображение его в память, которая доступна для чтения и записи, причем доступна в режиме разделения другим процессам*/
rр =nmapt(0. len. PROT_READ|PROT_WRITE. MAP_SHARED. fd. 0):
/* Модификация 25-й записи простым присваиванием значений пеерменным */
rp[24].balance -1000000;
rp[24].mode = 3;
Close(fd);
}
В некоторых операционных системах, например в версиях UNIX, основанных на коде System V Release 4, можно отобразить в память не только обычные файлы, но и некоторые другие типы файлов, например специальные файлы. Отображение в память блок-ориентированного специального файла, то есть раздела или части раздела диска, дает простой доступ к любой области диска, рассматриваемого как последовательность байт. При отображении байт-ориентированных устройств в оперативную память отображается внутренняя память контроллера устройства, например память сетевого адаптера Ethernet.
В общем случае не все типы файлов можно отобразить в память, например в UNIX SVR4 нельзя отображать каталоги и символьные связи.
Отображение файла эффективней непосредственного использования файловых операций в нескольких отношениях.
К недостаткам техники отображения файлов в память можно отнести то, что размер отображенного файла нельзя увеличить, в то время как файловые операции допускают это путем записи данных в конец файла.
Механизм отображения файлов в память используется большинством современных операционных систем.
Во многих операционных системах запросы к блок-ориентированным внешним устройствам с прямым доступом (типичными и наиболее распространенными представителями которых являются диски) перехватываются промежуточным программным слоем — подсистемой буферизации, называемой также дисковым кэшем. Дисковый кэш располагается между слоем драйверов файловых систем и блок-ориентированными драйверами. При поступлении запроса на чтение некоторого блока диспетчер дискового кэша просматривает свой буферный пул, находящийся в системной области оперативной памяти, и если требуемый блок имеется в кэше, то диспетчер копирует его в буфер запрашивающего процесса. Операция ввода-вывода считается выполненной, хотя физического обмена с устройством не происходило, при этом выигрыш во времени доступа к файлу очевиден.
При записи данные также попадают сначала в буфер, и только потом, при необходимости освободить место в буферном пуле или же по требованию приложения они действительно переписываются на диск. Операция же записи считается завершенной по завершении обмена с кэшем, а не с диском. Данные блоков диска за время пребывания в кэше могут быть многократно прочитаны прикладными процессами и модулями ОС без выполнения операций ввода-вывода с диском, что также существенно повышает производительность операционной системы.
Дисковый кэш обычно занимает достаточно большую часть оперативной системной памяти, чтобы максимально повысить вероятность попадания в кэш при выполнении дисковых операций. В таких специализированных операционных системах, как NetWare 3.x и 4.x дисковый кэш занимает большую часть физической памяти компьютера, что во многом и обеспечивает высокую скорость файлового сервиса, который находит значительную часть запрошенных по сети данных в кэше. Доля оперативной памяти, отводимой под дисковый кэш, зависит от специфики функций, выполняемых компьютером, — например, сервер приложений выделяет под дисковый кэш меньше памяти, чем файловый сервер, чтобы обеспечить более высокую скорость работы приложений за счет предоставления им большего объема оперативной памяти.
Отрицательным последствием использования дискового кэша является потенциальное снижение надежности системы. При крахе системы, когда по разным причинам (сбой по питанию, ошибка кода ОС и т. д.) теряется информация, находившаяся в оперативной памяти, могут пропасть и данные, которые пользователь считает надежно сохраненными на диске, но которые фактически до диска еще не дошли и хранились в кэше. Обычно для предотвращения таких потерь все содержимое дискового кэша периодически переписывается («сбрасывается») на диск. Существуют специальные системные вызовы, которые позволяют организовать принудительное выталкивание всех модифицированных блоков кэша на диск. Примером может служить системный вызов sync в ОС UNIX.
Однако и в этом случае потери возможны, хотя вероятность их уменьшается — теряются данные, которые появились в кэше в период после последнего сброса и до краха. Потери данных, хранящихся в кэше, можно существенно сократить при использовании восстанавливаемых файловых систем, которые рассматриваются ниже в разделе «Отказоустойчивость файловых и дисковых систем».
Существуют два способа организации дискового кэша. Первый способ, который можно назвать традиционным, основан на автономном диспетчере кэша, обслуживающем набор буферов системной памяти и самостоятельно организующим загрузку блока диска в буфер при необходимости, не обращаясь за помощью к другим подсистемам ОС. По такому принципу был организован дисковый кэш во многих ранних версиях UNIX (традиционный дисковый кэш работает и в последних версиях UNIX, но в качестве вспомогательного механизма), а также в ОС семейства NetWare.
Второй способ основан на использовании возможностей подсистемы виртуальной памяти по отображению файлов в память, рассмотренных в предыдущем разделе. При этом способе функции диспетчера дискового кэша значительно сокращаются, так как большую часть работы выполняет подсистема виртуальной памяти, а значит, уменьшается объем ядра ОС и повышается его надежность. Однако применение механизма отображения файлов имеет одно ограничение — во многих файловых системах существуют служебные данные, которые не относятся к файлам, а следовательно, не могут кэшироваться. Поэтому в таких случаях наряду с кэшем на основе виртуальной памяти применяется и традиционный кэш.
Рассмотрим традиционный дисковый кэш на примере его организации в ОС UNIX, где он появился в первых же версиях.
Любой запрос на ввод-вывод к блок-ориентированному устройству преобразуется в запрос к подсистеме буферизации, которая представляет собой буферный пул и комплекс программ управления этим пулом, называемых диспетчером дискового кэша. Буферный пул состоит из буферов, находящихся в области ядра. Размер отдельного буфера равен размеру блока данных (сектора) диска.
С каждым буфером связан заголовок, структура которого уже рассматривалась, — это та же структура buf, которая используется блок-ориентированным драйвером при выполнении операций чтения и записи. В заголовке buf драйверу передаются такие параметры, как адрес самого буфера в системной памяти, тип операции — чтение или запись, а также адресная информация для нахождения блока на диске — номер диска, номер раздела диска и логический номер блока.
Диспетчер дискового кэша управляет пулом буферов данных дисковых блоков с помощью дважды связанного списка заголовков buf, каждый из которых указывает на буфер данных (рис. 8.6).
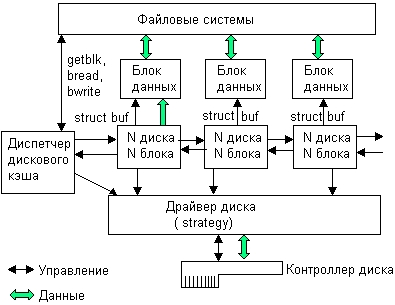
Рис. 8.6. Организация традиционного дискового кэша
При наличии кэша большая часть операций, которые выполняет функция strategy блок-ориентированного драйвера, производится с данными, размещенными в буферах дискового кэша, хотя драйверу все равно, кто инициировал данную операцию — диспетчер кэша или другой модуль ядра ОС, лишь бы она описывалась структурой buf с правильно заполненными полями. Отличие для драйвера заключается только в том, что диспетчер кэша всегда указывает в buf в качестве размера переписываемых данных размер блока диска (который чаще всего составляет 512 байт), а другие модули ОС могут указывать произвольный размер области данных. Например, менеджер виртуальной памяти запрашивает обмен страницами.
Таким образом, диспетчер кэша для фактической записи данных на диск использует интерфейс с блок-ориентированным драйвером, вызывая для этого его функцию strategy. Для вышележащих драйверов файловых систем диспетчер кэша предоставляет свой собственный интерфейс, который состоит из функций выделения буферов в кэше и функций чтения и записи данных из своих буферов. Функции диспетчера кэша не являются системными вызовами, они предназначены для внутреннего употребления, их используют модули операционной системы или же системные вызовы.
Интерфейс диспетчера кэша образуют следующие функции.
Функция getblk используется тогда, когда содержимое зарезервированного блока не существенно, например при записи на устройство блока данных.
Упрощенный алгоритм выполнения запросов к подсистеме буферизации приведен на рис. 8.7.

Рис. 8.7. Упрощенная схема выполнения запросов диспетчером дискового кэша
Отложенная запись является основным механизмом, за счет которого в системном буферном пуле задерживается определенное число блоков данных. На рисунке звездочками отмечены те операции, которые приводят к действительному обмену данных с диском, а остальные заканчиваются обменом данными в пределах оперативной памяти.
Дисковый кэш на основе виртуальной памяти
После того как средства виртуальной памяти получили в ОС большое распространение, их стали использовать для кэширования файлов вместо специализированных традиционных механизмов автономного буферного пула. Выше были рассмотрены механизмы отображения файлов в пользовательское виртуальное пространство по явному запросу приложения (например, с помощью системного вызова пипар ОС UNIX). При кэшировании же файл отображается не в пользовательскую, а в общую системную часть виртуального адресного пространства, а в остальном использование виртуальной памяти остается таким же. Для прикладного программиста кэширование файла путем отображения в системную область памяти остается прозрачным, оно выполняется неявно по инициативе ОС при выполнении обычных системных вызовов read и write.
В операционных системах UNIX на основе кода SVR4 в виртуальном адресном пространстве системы существует специальный сегмент segkmap, в который отображаются данные всех открытых файлов. Диспетчер кэша поддерживает массив структур smap, каждая из которых хранит описание одного отображения. Одно отображение состоит из 8096 последовательных блоков одного файла. Отображаемый файл описывается в структуре smap парой vnode/offset, где vnode является указателем на виртуальный дескриптор операции с файлом (см. раздел «Файловые операции» в главе 7 «Ввод-вывод и файловая система»), a offset — смещением в файле на диске, начиная с которого отображаются данные файла. Кроме того, в структуре smap указывается виртуальный адрес внутри сегмента segkmap, на который отображаются данные файла.
При выполнении системного вызова read для чтения данных из некоторого открытого файла подсистема ввода-вывода вызывает функцию segmap_getmap диспетчера кэша, которой передается в качестве параметра пара vnode/offset (эти значения берутся из структуры file, описывающей операцию с файлом). Функция segmap_getmap ищет в массиве smap элемент, который содержит требуемую пару vnode/offset. Если такого элемента нет, то это значит, что требуемый участок файла еще не был отображен в системную память и для нового отображения создается новый элемент smap, а значение виртуального адреса, на который он указывает, возвращается в read. После этого системный вызов read пытается скопировать данные из системной памяти, начиная с указанного адреса, в пользовательский буфер. Так как страницы, содержащей требуемый виртуальный адрес, в оперативной памяти пока нет, то при обращении к памяти возникает страничное прерывание, которое обслуживается соответствующим обработчиком прерываний. В результате блок-ориентированный драйвер читает блоки отсутствующей страницы (а при упреждающей загрузке — и нескольких окружающих ее страниц) с диска и помещает их в системную память. Затем системный вызов read продолжает свою работу, фактически копируя данные в пользовательский буфер. Последующие обращения с помощью вызова read к близкой к прочитанным данным области файла (в пределах 8096 блоков) уже не вызывают нового отображения, а страничные прерывания будут загружать новые блоки файла в кэш по мере необходимости.
На основе таких же принципов работают диспетчеры кэша и в других современных ОС, поддерживающих виртуальную память, например Windows NT, OS/2.
Отказоустойчивость файловых и дисковых систем
Диски и файловые системы, используемые для упорядоченного хранения данных на дисках, часто представляют собой последний «островок стабильности», на котором находит спасение пользователь после неожиданного краха системы, разрушившего результаты его труда, полученные за последние нескольких минут или даже часов, но не сохраненные на диске. Однако те данные, которые пользователь записывал в течение своего сеанса работы на диск, останутся, скорее всего, нетронутыми. Вероятность того, что система при сбое питания или программной ошибке в коде какого-либо системного модуля будет делать осмысленные действия по уничтожению файлов на диске, пренебрежимо мала. Поэтому при перезапуске операционной системы после краха большинство данных, хранящихся в файлах на диске, по-прежнему корректны и доступны пользователю. Коды и данные операционной системы также хранятся в файлах, что и позволяет легко ее перезапустить после сбоя, не связанного с отказом диска или повреждением системных файлов.
Тем не менее диски также могут отказывать, например, по причине нарушения магнитных свойств отдельных областей поверхности. В данном разделе рассматриваются методы, которые повышают устойчивость вычислительной системы к отказам дисков за счет использования избыточных дисков и специальных алгоритмов управления массивами таких дисков.
Другой причиной недоступности данных после сбоя системы может служить нарушение целостности служебной информации файловой системы, произошедшее из-за незавершенности операций по изменению этой информации при крахе системы. Примером такого нарушения может служить несоответствие между адресной информацией файла, хранящейся в каталоге, и фактическим размещением кластеров файла. Для борьбы с этим явлением применяются так называемые восстанавливаемые файловые системы, которые обладают определенной степенью устойчивости к сбоям и отказам компьютера (при сохранении работоспособности диска, на котором расположена данная файловая система). Комплексное применение отказоустойчивых дисковых массивов и восстанавливаемых файловых систем существенно повышают такой важный показатель вычислительной системы, как общая надежность.
Восстанавливаемость файловых систем
Причины нарушения целостности файловых систем
Восстанавливаемость файловой системы — это свойство, которое гарантирует, что в случае отказа питания или краха системы, когда все данные в оперативной памяти безвозвратно теряются, все начатые файловые операции будут либо успешно завершены, либо отменены безо всяких отрицательных последствий для работоспособности файловой системы.
Любая операция над файлом (создание, удаление, запись, чтение и т. д.) может быть представлена в виде некоторой последовательности подопераций. Последствия сбоя питания или краха ОС зависят от того, какая операция ввода-вывода выполнялась в этот момент, в каком порядке выполнялись подоперации и до какой подоперации продвинулось выполнение операции к этому моменту. Рассмотрим, например, последствия сбоя при удалении файла в файловой системе FAT. Для выполнения этой операции требуется пометить как недействительную запись об этом файле в каталоге, а также обнулить все элементы FAT, которые соответствуют кластерам удаляемого файла. Предположим, что сбой питания произошел после того, как была объявлена недействительной запись в каталоге и обнулено несколько (но не все) элементов FAT, занимаемых удаляемым файлом. В этом случае после сбоя файловая система сможет продолжать нормальную работу, за исключением того, что несколько последних кластеров удаленного файла будут теперь «вечно» помечены занятыми. Хуже было бы, если бы операция удаления начиналась с обнуления элементов FAT, а корректировка каталога происходила бы после. Тогда при возникновении сбоя между этими подоперациями содержимое каталога не соответствовало бы действительному состоянию файловой системы: файл как будто существует, а на самом деле его нет. Не исправленная запись в каталоге содержит адрес кластера, который уже объявлен свободным и может быть назначен другому файлу; это может привести к разного рода коллизиям.
Некорректность файловой системы может возникать не только в результате насильственного прерывания операций ввода-вывода, выполняемых непосредственно с диском, но и в результате нарушения работы дискового кэша. Кэширование данных с диска предполагает, что в течение некоторого времени результаты операций ввода-вывода никак не сказываются на содержимом диска — все изменения происходят с копиями блоков диска, временно хранящихся в буферах оперативной памяти. В этих буферах оседают данные из пользовательских файлов и служебная информация файловой системы, такая как каталоги, индексные дескрипторы, списки свободных, занятых и поврежденных блоков и т. п.
Для согласования содержимого кэша и диска время от времени выполняется запись всех модифицированных блоков, находящихся в кэше, на диск. Выталкивание блоков на диск может выполняться либо по инициативе менеджера дискового кэша, либо по инициативе приложения. Менеджер дискового кэша вытесняет блоки из кэша в следующих случаях:
Кроме того, в распоряжение приложений обычно предоставляются средства, с помощью которых они могут запросить у подсистемы ввода-вывода операцию сквозной записи; при ее выполнении данные немедленно и практически одновременно записываются и на диск, и в кэш.
Несмотря на то что период полного сброса кэша на диск обычно выбирается весьма коротким (порядка 10-30 секунд), все равно остается высокая вероятность того, что при возникновении сбоя содержимое диска не в полной мере будет соответствовать действительному состоянию файловой системы — копии некоторых блоков с обновленным содержимым система может не успеть переписать на диск. Для восстановления некорректных файловых систем, использующих кэширование диска, в операционных системах предусматриваются специальные утилиты, такие как fsck для файловых систем s5/uf, ScanDisk для FAT
или Chkdsk для файловой системы HPFS. Однако объем несоответствий может быть настолько большим, что восстановление файловой системы после сбоя с помощью стандартных системных средств становится невозможным.
Протоколирование транзакций
Проблемы, связанные с восстановлением файловой системы, могут быть решены при помощи техники протоколирования транзакций, которая сводится к следующему. В системе должны быть определены транзакции (transactions) — неделимые работы, которые не могут быть выполнены частично. Они либо выполняются полностью, либо вообще не выполняются.
Модель неделимой транзакции пришла из бизнеса. Пусть, например, идет переговорный процесс двух фирм о покупке-продаже некоторого товара. В процессе переговоров условия договора могут многократно меняться, уточняться. Пока договор еще не подписан обеими сторонами, каждая из них может от него отказаться. Но после подписания контракта сделка (транзакция) должна быть выполнена от начала и до конца. Если же контракт не подписан, то любые действия, которые были уже проделаны, отменяются или объявляются недействительными. В файловых системах такими транзакциями являются операции ввода-вывода, изменяющие содержимое файлов, каталогов или других системных структур файловой системы (например, индексных дескрипторов ufs или элементов FAT). Пусть к файловой системе поступает запрос на выполнение той или иной операции ввода-вывода. Эта операция включает несколько шагов, связанных с созданием, уничтожением и модификацией объектов файловой системы. Если все подоперации были благополучно завершены, то транзакция считается выполненной. Это действие называется фиксацией (committing) транзакции. Если же одна или более подопераций не успели выполниться из-за сбоя питания или краха ОС, тогда для обеспечения целостности файловой системы все измененные в рамках транзакции данные файловой системы должны быть возвращены точно в то состояние, в котором они находились до начала выполнения транзакции. Так, например, транзакцией может быть представлена операция удаления файла. Действительно, для целостности файловой системы необходимо, чтобы все требуемые при выполнении данной операции изменения каталога и таблицы распределения дисковой памяти были сделаны в полном объеме. Либо, если во время операции произошел сбой, каталог и таблица распределения памяти должны быть приведены в исходное состояние.
С другой стороны, в файловой системе существуют операции, которые не изменяют состояния файловой системы и которые вследствие этого нет необходимости рассматривать как транзакции. Примерами таких операций являются чтение файла, поиск файла на диске, просмотр атрибутов файла.
Незавершенная операция с диском несет угрозу целостности файловой системы. Каким же образом файловая система может реализовать свойство транзакций «все или ничего»? Очевидно, что решение в этом случае может быть одно — необходимо протоколировать (запоминать) все изменения, происходящие в рамках транзакции, чтобы на основе этой информации в случае прерывания транзакции можно было отменить все уже выполненные подоперации, то есть сделать так называемый откат транзакции.
В файловых системах с кэшированием диска для восстановления системы после сбоя кроме отката незавершенных транзакций необходимо выполнить дополнительное действие — повторение зафиксированных транзакций. Когда происходит сбой по питанию или крах ОС, все данные, находящиеся в оперативной памяти, теряются, в том числе и модифицированные блоки данных, которые менеджер дискового кэша не успел вытолкнуть на диск. Единственный способ восстановить утерянные изменения данных — это повторить все завершенные транзакции, которые участвовали в модификации этих блоков. Чтобы обеспечить возможность повторения транзакций, система должна включать в протокол не только данные, которые могут быть использованы для отката транзакции, но и данные, которые позволят в случае необходимости повторить всю транзакцию.
ПРИМЕЧАНИЕ
При восстановлении часто возникают ситуации, когда система пытается отменить транзакцию, которая уже была отменена или вообще не выполнялась. Аналогично при повторении некоторой транзакции может оказаться, что она уже была выполнена. Учитывая это, необходимо так определить подоперации транзакции, чтобы многократное выполнение каждой из этих подопераций не имело никакого добавочного эффекта по сравнению с первым выполнением этой подоперации. Такое свойство операции называется идемпотентностью (idempotency). Примером идемпотентной операции может служить, например, многократное присвоение переменной некоторого значения (сравните с операциями инкремента и декремента).
Для восстановления файловой системы используется упреждающее протоколирование транзакций. Оно заключается в том, что перед изменением какого-либо блока данных на диске или в дисковом кэше производится запись в специальный системный файл —
журнал транзакций (log file), где отмечается, какая транзакция делает изменения, какой файл и блок изменяются и каковы старое и новое значения изменяемого блока. Только после успешной регистрации всех подопераций в журнале делаются изменения в исходных блоках. Если транзакция прерывается, то информация журнала регистрации используется для приведения файлов, каталогов и служебных данных файловой системы в исходное состояние, то есть производится откат. Если транзакция фиксируется, то и об этом делается запись в журнал регистрации, но новые значения измененных данных сохраняются в журнале еще некоторое время, чтобы сделать возможным повторение транзакции, если это потребуется.
Восстанавливаемость файловой системы NTFS
Файловая система NTFS является восстанавливаемой файловой системой, однако восстанавливаемость обеспечивается только для системной информации файловой системы, то есть каталогов, атрибутов безопасности, битовой карты занятости кластеров и других системных файлов. Сохранность данных пользовательских файлов, работа с которыми выполнялась в момент сбоя, в общем случае не гарантируется.
Для повышения производительности файловая система NTFS использует дисковый кэш, то есть все изменения файлов, каталогов и управляющей информации выполняются сначала над копиями соответствующих блоков в буферах оперативной памяти и только спустя некоторое время переносятся на диск. Однако кэширование, как уже было сказано, повышает риск разрушения файловой системы. В таких условиях NTFS обеспечивает отказоустойчивость с помощью технологии протоколирования транзакций и восстановления системных данных. Пользовательские данные, которые в момент краха находились в дисковом кэше и не успели записаться на диск, в NTFS не восстанавливаются.
Журнал регистрации транзакций в NTFS делится на две части: область рестарта и область протоколирования (рис. 8.8).
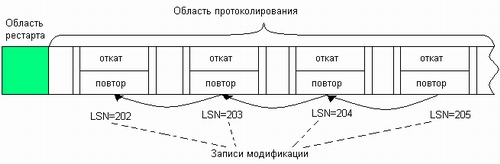
Рис. 8.8. Записи модификации в журнале транзакций
Существует несколько типов записей в журнале транзакций: запись модификации, запись контрольной точки, запись фиксации транзакции, запись таблицы модификации, запись таблицы модифицированных страниц.
Запись модификации заносится в журнал транзакций относительно каждой подоперации, которая модифицирует системные данные файловой системы. Эта запись состоит из двух частей: одна содержит информацию, необходимую системе для повторения этого действия, а другая — информацию для его отмены. Информация о модификации хранится в двух формах — в физическом и в логическом описаниях. Логическое описание используется программным обеспечением уровня приложений и формулируется в терминах операций, например «выделить файловую запись в MFT» или «удалить имя из корневого индекса». На нижнем уровне программного обеспечения, к которому относятся модули самой NTFS, используется менее компактное, но более простое физическое описание, сводящееся к указанию диапазона байт на диске, в которые необходимо поместить определенные значения.
Пусть, например, регистрируется транзакция создания файла lotus.doc, которая включает, как показано на рисунке, три подоперации. Тогда в журнале будут сделаны три записи модификации, содержимое которых приведено в табл. 8.1.
Таблица 8.1. Структура записи модификации
|
Запись модификации |
Информация для повторения транзакции |
Информация для отката транзакции |
|
LSN-202 |
Выделить и инициировать запись для нового файла lotus.doc в таблице MFT |
Удалить запись о файле lotus.doc из таблицы MFT |
|
LSN-203 |
Добавить имя файла в индекс |
Исключить имя файла из индекса |
|
LSN-204 |
Установить биты 3-9 в битовой карте |
Обнулить биты 3-9 в битовой карте |
Журнал транзакций, как и все остальные файлы, кэшируется в буферах оперативной памяти и периодически сбрасывается на диск.
Файловая система NTFS все действия с журналом транзакций выполняет только путем запросов к специальной службе LFS (Log File Service). Эта служба размещает в журнале новые записи, сбрасывает на диск все записи до некоторого заданного номера, считывает записи в прямом и обратном порядке и выполняет некоторые другие действия над записями журнала.
Прежде чем выполнить любую транзакцию, NTFS вызывает службу журнала транзакций LFS для регистрации всех подопераций в журнале транзакций. И только после этого описанные подоперации действительно выполняются над копиями блоков данных файловой системы, находящимися в кэше. Когда все подоперации транзакции выполнены, с помощью службы LFS транзакция фиксируется. Это выражается в том, что в журнал заносится специальный вид записи — запись фиксации транзакции.
Параллельно с регистрацией и выполнением транзакций происходит процесс выталкивания блоков кэша на диск. Сброс на диск измененных блоков выполняется в два этапа: сначала сбрасываются блоки журнала, а потом — модифицированные блоки транзакций. Такой порядок реализуется следующим образом. Каждый раз, когда диспетчер кэша принимает решение о том, что определенные модифицированные блоки (не обязательно все) должны быть вытеснены на диск, он сообщает об этом службе LFS. В ответ на это сообщение LFS обращается к диспетчеру кэша с запросом о записи на диск всех измененных блоков журнала. После того как блоки журнала сброшены на диск, сбрасываются на диск модифицированные блоки транзакций, среди которых могут быть, конечно, и блоки системных данных файловой системы.
Такая двухэтапная процедура сброса данных кэша на диск делает возможным восстановление файловой системы, если во время записи модифицированных блоков из кэша на диск произойдет сбой. Действительно, какие бы неприятности не произошли во время записи модифицированных блоков на диск, вся информация об изменениях, произведенных в этих блоках, уже записана на диск в файл журнала транзакций. Заметим, что все действия, которые были выполнены файловой системой в интервале между последним сбросом данных на диск и сбоем, отменяются сами собой, поскольку все они проводятся только над блоками в кэше и не вызывают никаких изменений содержимого диска.
Какие же дефекты может иметь файловая система после сбоя?
Во-первых, это несогласованность системных данных, возникшая в результате незавершенности транзакций, которые были начаты еще до момента последнего сброса данных из кэша на диск. На рис. 8.9 показана транзакция А, две подоперации которой — ai и а2 — были сделаны до сброса кэша, а еще две — а3 и а4 — после сброса кэша. К моменту сбоя результаты первых двух подопераций могли быть записаны на диск, в то время как изменения, вызванные подоперациями аз и а4, отразились только на копиях блоков файловой системы в кэше и были потеряны в результате сбоя. Чтобы устранить несогласованность, вызванную этой причиной, требуется сделать откат для всех транзакций, незафиксированных к моменту последнего сброса кэша. Для примера, изображенного на рисунке, такими транзакциями являются транзакции А и С. В каждый момент времени NTFS располагает списком незафиксированных транзакций, называемым таблицей незавершенных транзакций (transaction table). Для каждой незавершенной транзакции эта таблица содержит последовательный номер LSN последней по времени подоперации, выполненной в рамках данной транзакции. По этому номеру может быть найдена вся цепочка подопераций транзакции.
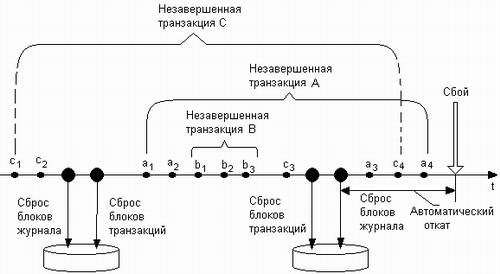
Рис. 8.9. Временная диаграмма событий в файловой системе
Во-вторых, противоречия в файловой системе могут быть вызваны потерей тех изменений, которые были сделаны транзакциями, завершившимися еще до сброса кэша, но которые не были записаны на диск в ходе последнего сброса. На рисунке такой транзакцией может оказаться транзакция В. Чтобы определить, какие завершенные транзакции надо повторять, система ведет таблицу модифицированных страниц1 {dirty page table), находящихся в данный момент в кэше. В таблице для каждой модифицированной страницы указывается, какая транзакция вызвала эти изменения. Повторение транзакций, которые имели дело со страницами, указанными в данном списке, гарантирует, что ни одно изменение не будет потеряно.
1 Дисковый кэш в Windows NT основан на использовании виртуальной памяти, поэтому он оперирует не блоками, а страницами.
Таблицы модифицированных страниц и незавершенных транзакций создаются NTFS на основании записей журнала транзакций и поддерживаются в оперативной памяти. Следует подчеркнуть, что обе эти таблицы не добавляют новой информации в журнал транзакций, они лишь представляют информацию, содержащуюся в записях журнала, в концентрированном виде, более удобном для использования при восстановлении. Содержимое таблиц фиксируется в журнале транзакций во время выполнения операции контрольная точка.
Операция контрольная точка выполняется каждые 5 секунд и включает выполнение следующих действий (рис. 8.10). Сначала в области протоколирования журнала транзакций создаются две записи — запись таблицы незавершенных транзакций и запись таблицы модифицированных страниц, содержащие копии соответствующих таблиц. Затем номера этих записей включаются в запись контрольной точки, которая также создается в области протоколирования журнала транзакций. Сделав запись контрольной точки, NTFS помещает ее номер LSN в область рестарта.
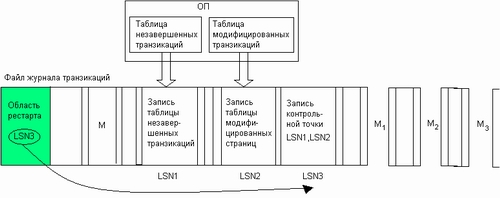
Рис. 8.10. Записи операции контрольная точка
Заметим, что процессы создания контрольных точек и сброса блоков данных из кэша на диск протекают асинхронно. Когда в результате сбоя из оперативной памяти исчезает вся информация, в том числе из таблиц незавершенных транзакций и модифицированных страниц, состояние этих таблиц, хотя и несколько устаревшее, сохраняется на диске в файле журнала транзакций. Кроме того, здесь же имеется несколько более поздних записей, которые были сделаны в период между сохранением таблиц и сбросом кэша (на рисунке это записи Ml, M2, МЗ). При восстановлении файловая система обрабатывает эти записи и вносит изменения в таблицы незавершенных транзакций и модифицированных страниц, сохраненные в журнале. Так, например, если запись Ml является записью фиксации транзакции, то соответствующая транзакция исключается из таблицы незавершенных транзакций, а если это запись модификации, то в таблицу модифицированных страниц заносится информация об еще одной странице.
Процесс восстановления файловой системы включает следующие шаги:
1. Чтение области рестарта из файла журнала транзакций и определение номера самой последней по времени записи о контрольной точке.
2. Чтение записи контрольной точки и определение номеров записей таблицы незавершенных транзакций и таблицы модифицированных страниц.
3. Чтение и корректировка таблиц незавершенных транзакций и модифицированных страниц на основании записей, сделанных в журнале транзакций уже после сохранения таблиц в журнале, но еще до записи журнала на диск (рис. 8.11).
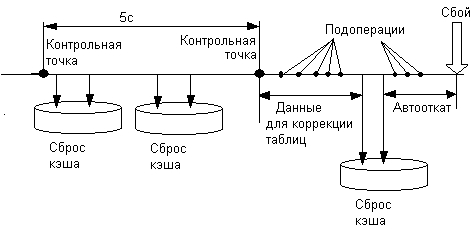
Рис. 8.11. Асинхронность процессов сброса кэша и создания контрольных точек
4. Анализ таблицы модифицированных страниц, определение номера самой ранней записи модификации страницы.
5. Чтение журнала транзакций в прямом направлении, начиная с самой ранней записи модификации, найденной при анализе таблицы модифицированных страниц. При этом система выполняет повторение завершенных транзакций, в результате которого устраняются все несоответствия файловой системы, вызванные потерями модифицированных страниц в кэше во время сбоя или краха операционной системы.
6. Анализ таблицы незавершенных транзакций, определение номера самой поздней подоперации, выполненной в рамках незавершенной транзакции.
7. Чтение журнала транзакций в обратном направлении. Учитывая, что все подоперации каждой транзакции связаны в список, система легко переходит от одной записи модификации к другой, извлекает из них информацию, необходимую для отмены, и выполняет откат незавершенных транзакций.
Операция отмены сама является транзакцией, поскольку связана с модификацией системных блоков файловой системы — поэтому она протоколируется обычным образом в журнале транзакций. По отношению к ней также могут быть применены операции повторения или отката.
Избыточные дисковые подсистемы RAID
В основе средств обеспечения отказоустойчивости дисковой памяти лежит общий для всех отказоустойчивых систем принцип избыточности, и дисковые подсистемы RAID (Redundant Array of Inexpensive Disks, дословно — «избыточный массив недорогих дисков») являются примером реализации этого принципа. Идея технологии RAID-массивов состоит в том, что для хранения данных используется несколько дисков, даже в тех случаях, когда для таких данных хватило бы места на одном диске. Организация совместной работы нескольких централизованно управляемых дисков позволяет придать их совокупности новые свойства, отсутствовавшие у каждого диска в отдельности.
RAID-массив может быть создан на базе нескольких обычных дисковых устройств, управляемых обычными контроллерами, в этом случае для организации управления всей совокупностью дисков в операционной системе должен быть установлен специальный драйвер. В Windows NT, например, таким драйвером является FtDisk — драйвер отказоустойчивой дисковой подсистемы. Существуют также различные модели дисковых систем, в которых технология RAID реализуется полностью аппаратными средствами, в этом случае массив дисков управляется общим специальным контроллером.
Дисковый массив RAID представляется для пользователей и прикладных программ единым логическим диском. Такое логическое устройство может обладать различными качествами в зависимости от стратегии, заложенной в алгоритмы работы средств централизованного управления и размещения информации на всей совокупности дисков. Это логическое устройство может, например, обладать повышенной отказоустойчивостью или иметь производительность, значительно большую, чем у отдельно взятого диска, либо обладать обоими этими свойствами. Различают несколько вариантов RAID-массивов, называемых также уровнями: RAID-0, RAID-1, RAID-2, RAID-3, RAID-4, RAID-5 и некоторые другие.
При оценке эффективности RAID-массивов чаще всего используются следующие критерии:
В логическом устройстве RAID-0 (рис. 8.12) общий для дискового массива контроллер при выполнении операции записи расщепляет данные на блоки и передает их параллельно на все диски, при этом первый блок данных записывается на первый диск, второй — на второй и т. д. Различные варианты реализации технологии RAID-0 могут отличаться размерами блоков данных, например в наборах с чередованием, представляющих собой программную реализацию RAID-0 в Windows NT, на диски поочередно записываются полосы данных (strips) по 64 Кбайт. При чтении контроллер мультиплексирует блоки данных, поступающие со всех дисков, и передает их источнику запроса.
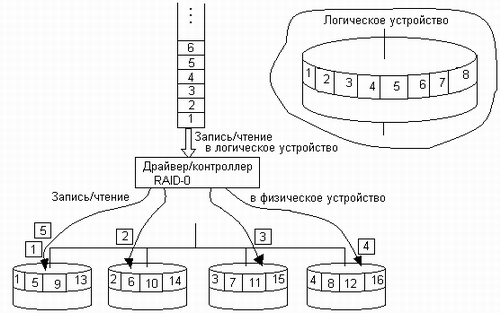
Рис. 8.12. Организация массива RAID-0
По сравнению с одиночным диском, в котором данные записываются и считываются с диска последовательно, производительность дисковой конфигурации RAID-0 значительно выше за счет одновременности операций записи/чтения по всем дискам массива.
Уровень RAID-0 не обладает избыточностью данных, а значит, не имеет возможности повысить отказоустойчивость. Если при считывании произойдет сбой, то данные будут безвозвратно испорчены. Более того, отказоустойчивость даже снижается, поскольку если один из дисков выйдет из строя, то восстанавливать придется все диски массива. Имеется еще один недостаток — если при работе с RAID-0 объем памяти логического устройства потребуется изменить, то сделать это путем простого добавления еще одного диска к уже имеющимся в RAID-массиве дискам невозможно без полного перераспределения информации по всему изменившемуся набору дисков.
Уровень RAID-1 (рис. 8.13) реализует подход, называемый зеркальным копированием (mirroring). Логическое устройство в этом случае образуется на основе одной или нескольких пар дисков, в которых один диск является основным, а другой диск (зеркальный) дублирует информацию, находящуюся на основном диске. Если основной диск выходит из строя, зеркальный продолжает сохранять данные, тем самым обеспечивается повышенная отказоустойчивость логического устройства. За это приходится платить избыточностью — все данные хранятся на логическом устройстве RAID-1 в двух экземплярах, в результате дисковое пространство используется лишь на 50 %.
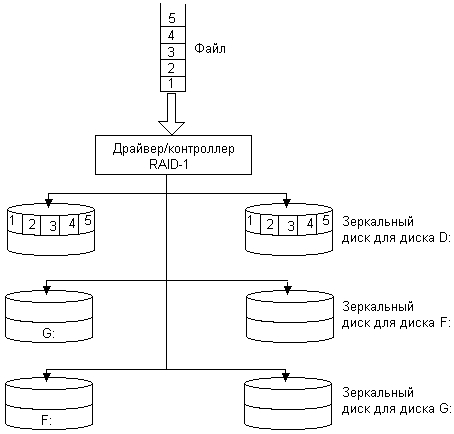
Рис. 8.13. Организация массива RAID-1
При внесении изменений в данные, расположенные на логическом устройстве RAID-1, контроллер (или драйвер) массива дисков одинаковым образом модифицирует и основной, и зеркальный диски, при этом дублирование операций абсолютно прозрачно для пользователя и приложений. Удвоение количества операций записи снижает, хотя и не очень значительно, производительность дисковой подсистемы, поэтому во многих случаях наряду с дублированием дисков дублируются и их контроллеры. Такое дублирование (duplexing) помимо повышения скорости операций записи обеспечивает большую надежность системы — данные на зеркальном диске останутся доступными не только при сбое диска, но и в случае сбоя дискового контроллера.
Некоторые современные контроллеры (например, SCSI-контроллеры) обладают способностью ускорять выполнение операций чтения с дисков, связанных в зеркальный набор. При высокой интенсивности ввода-вывода контроллер распределяет нагрузку между двумя дисками так, что две операции чтения могут быть выполнены одновременно. В результате распараллеливания работы по считыванию данных между двумя дисками время выполнения операции чтения может быть снижено в два раза! Таким образом, некоторое снижение производительности, возникающее при выполнении операций записи, с лихвой компенсируется повышением скорости выполнения операций чтения.
Уровень RAID-2 расщепляет данные побитно: первый бит записывается на первый диск, второй бит — на второй диск и т. д. Отказоустойчивость реализуется в RAID-2 путем использования для кодирования данных корректирующего кода Хэмминга, который обеспечивает исправление однократных ошибок и обнаружение двукратных ошибок. Избыточность обеспечивается за счет нескольких дополнительных дисков, куда записывается код коррекции ошибок. Так, массив с числом основных дисков от 16 до 32 должен иметь три дополнительных диска для хранения кода коррекции. RAID-2 обеспечивает высокую производительность и надежность, но он применяется в основном в мэйнфреймах и суперкомпьютерах. В сетевых файловых серверах этот метод в настоящее время практически не используется из-за высокой стоимости его реализации.
В массивах RAID-3 используется расщепление (stripping) данных на массиве дисков с выделением одного диска на весь набор для контроля четности. То есть если имеется массив из N дисков, то запись на N-1 из них производится параллельно с побайтным расщеплением, а N-й диск используется для записи контрольной информации о четности. Диск четности является резервным. Если какой-либо диск выходит из строя, то данные остальных дисков плюс данные о четности резервного диска позволяют не только определить, какой из дисководов массива вышел из строя, но и восстановить утраченную информацию. Это восстановление может выполняться динамически, по мере поступления запросов, или в результате выполнения специальной процедуры восстановления, когда содержимое отказавшего диска заново генерируется и записывается на резервный диск.
Рассмотрим пример динамического восстановления данных. Пусть массив RAID-3 состоит из четырех дисков: три из них — ДИСК 1, ДИСК 2 и ДИСК 3 — хранят данные, а ДИСК 4 хранит контрольную сумму по модулю 2 (XOR). И пусть на логическое устройство, образованное этими дисками, записывается последовательность байт, каждый из которых имеет значение, равное его порядковому номеру в последовательности. Тогда первый байт 0000 0001 попадет на ДИСК 1, второй, байт 0000 0010 - на ДИСК 2, а третий по порядку байт - на ДИСК 3. На четвертый диск будет записана сумма по модулю 2, равная в данном случае 0000 0000 (рис. 8.14). Вторая строка таблицы, приведенной на рисунке, соответствует следующим трем байтам и их контрольной сумме и т. д. Представим, что ДИСК 2 вышел из строя.
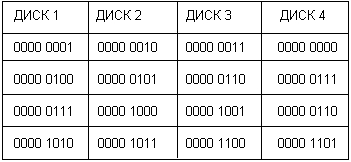
Рис. 8.14. Пример распределения данных по дискам массива RAID-3
При поступлении запроса на чтение, например, пятого байта (он выделен жирным шрифтом) контроллер дискового массива считывает данные, относящиеся к этой строке со всех трех оставшихся дисков — байты 0000 0100, 0000 ОНО, 0000 0111 — и вычисляет для них сумму по модулю 2. Значение контрольной суммы 0000 0101 и будет являться восстановленным значением потерянного из-за неисправности пятого байта.
Если же требуется записать данные на отказавший диск, то эта операция физически не выполняется, вместо этого корректируется контрольная сумма — она получает такое значение, как если бы данные были действительно записаны на этот диск.
Однако динамическое восстановление данных снижает производительность дисковой подсистемы. Для полного восстановления исходного уровня производительности необходимо заменить вышедший из строя диск и провести регенерацию всех данных, которые хранились на отказавшем диске.
Минимальное количество дисков, необходимое для создания конфигурации RAID-3, равно трем. В этом случае избыточность достигает максимального значения — 33 %. При увеличении числа дисков степень избыточности снижается, так, для 33 дисков она составляет менее 1 %.
Уровень RAID-3 позволяет выполнять одновременное чтение или запись данных на несколько дисков для файлов с длинными записями, однако следует подчеркнуть, что в каждый момент выполняется только один запрос на ввод-вывод, то есть RAID-3 позволяет распараллеливать ввод-вывод в рамках только одного процесса (рис. 8.15). Таким образом, уровень RAID-3 повышает как надежность, так и скорость обмена информацией.
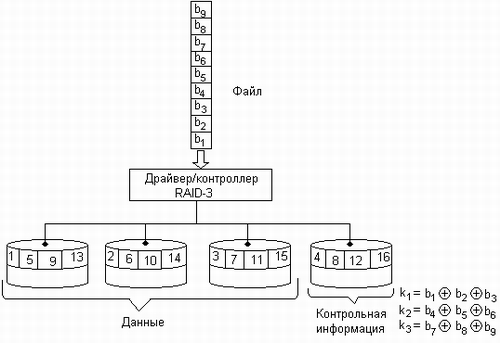
Рис. 8.15. Организация массива RAID-3
Организация RAID-4 аналогична RAID-3, за тем исключением, что данные распределяются на дисках не побайтно, а блоками. За счет этого может происходить независимый обмен с каждым диском. Для хранения контрольной информации также используется один дополнительный диск. Эта реализация удобна для файлов с очень короткими записями и большей частотой операций чтения по сравнению с операциями записи, поскольку в этом случае при подходящем размере блоков диска возможно одновременное выполнение нескольких операций чтения.
Однако по-прежнему допустима только одна операция записи в каждый момент времени, так как все операции записи используют один и тот же дополнительный диск для вычисления контрольной суммы. Действительно, информация о четности должна корректироваться каждый раз, когда выполняется операция записи. Контроллер должен сначала считать старые данные и старую контрольную информацию, а затем, объединив их с новыми данными, вычислить новое значение контрольной суммы и записать его на диск, предназначенный для хранения контрольной информации. Если требуется выполнить запись в более чем один блок, то возникает конфликт по обращению к диску с контрольной информацией. Все это приводит к тому, что скорость выполнения операций записи в массиве RAID-4 снижается.
В уровне RAID-5 (рис. 8.16) используется метод, аналогичный RAID-4, но данные о контроле четности распределяются по всем дискам массива. При выполнении операции записи требуется в три раза больше оперативной памяти. Каждая команда записи инициирует ту же последовательность «считывание—модификация—запись» в нескольких дисках, как и в методе RAID-4. Наибольший выигрыш в производительности достигается при операциях чтения. Поскольку информация о четности может быть считана и записана на несколько дисков одновременно, скорость записи по сравнению с уровнем RAID-4 увеличивается, однако она все еще гораздо ниже скорости отдельного диска метода RAID-1 или RAID-3.
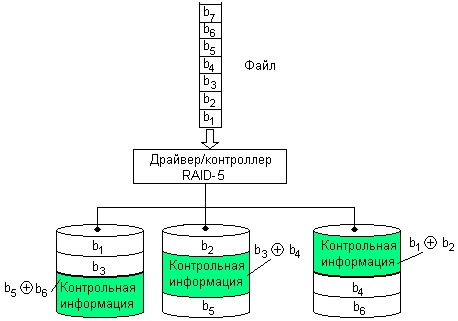
Рис. 8.16. Организация массива RAID-5
Кроме рассмотренных выше имеются еще и другие варианты организации совместной работы избыточного набора дисков, среди них можно особо отметить технологию RAID-10, которая представляет собой комбинированный способ, при котором данные «расщепляются» (RAID-0) и зеркально копируются (RAID-1) без вычисления контрольных сумм. Обычно две пары «зеркальных» массивов объединяются и образуют один массив RAID-0. Этот способ целесообразно применять при работе с большими файлами.
В табл. 8.2 сведены основные характеристики для некоторых конфигураций избыточных дисковых массивов.
Таблица 8.2. Характеристики уровней RAID
|
Конфигу- рация RAID |
Избы-
точность |
Отказо- устойчивость |
Скорость чтения |
Скорость записи |
|
RAID-0 |
Нет |
Нет |
Повышен- ная |
Повышен- ная |
|
RAID RAID-1 |
50% |
Есть |
Повышен- ная |
Пониженная (в варианте без дуплекси-
рования) |
|
RAID-3, RAID-4, RAID-5 |
До 33% |
Есть |
Повышен- ная |
Пониженная (в разной степени) |
|
RAID-10 |
50% |
Есть |
Повышен- ная |
Повышен- ная |
Обмен данными между процессами и потоками
Если абстрагироваться от вопросов синхронизации, то обмен данными между потоками одного процесса не представляет никакой сложности — имея общее адресное пространство и общие открытые файлы, потоки получают беспрепятственный доступ к данным друг друга. Другое дело — обмен данными потоков, выполняющихся в рамках разных процессов. Для защиты процессов друг от друга ОС возводит мощные изолирующие преграды, которые не только защищают процессы, но и не позволяют им передавать друг другу данные. Потоки разных процессов работают в разных адресных пространствах. Однако операционная система имеет доступ ко всем областям памяти, поэтому она может играть роль посредника в информационном обмене прикладных потоков. При возникновении необходимости в обмене данными поток обращается с запросом к ОС. По этому запросу ОС, пользуясь своими привилегиями, создает различные системные средства связи, такие, например, как конвейеры или очереди сообщений.
Эти средства, так же как и рассмотренные выше средства синхронизации процессов, относятся к классу средств межпроцессного взаимодействия, то есть IPC (Inter-Process Communications).
Многие из средств межпроцессного обмена данными выполняют также и функции синхронизации: в том случае, когда данные для процесса-получателя отсутствуют, последний переводится в состояние ожидания средствами ОС, а при поступлении данных от процесса-отправителя процесс-получатель активизируется.
Набор средств межпроцессного обмена данными в большинстве современных ОС выглядит следующим образом:
Кроме этого достаточно стандартного набора средств в конкретных ОС часто имеются и более специфические средства межпроцессного обмена, например средства среды STREAMS для различных версий UNIX или почтовые ящики (mail slots) в ОС Windows.
Конвейеры как средство межпроцессного обмена данными впервые появились в операционной системе UNIX. Системный вызов pipe позволяет двум процессам обмениваться неструктурированным потоком байт. Конвейер представляет собой буфер в оперативной памяти, поддерживающий очередь байт по алгоритму FIFO. Для программиста, использующего системный вызов pipe, этот буфер выглядит как безымянный файл, в который можно писать и читать, осуществляя тем самым обмен данными.
Системный вызов pipe имеет одно существенное ограничение — обмениваться данными могут только родственные процессы, точнее, процессы, которые имеют общего прародителя, создавшего данный конвейер. Если операционная система поддерживает потоки, то это же ограничение будет означать, что конвейером могут воспользоваться только потоки, относящиеся к такого рода процессам. Ограничение проистекает из-за того, что конвейер такого типа не имеет имени, а обращение к нему происходит по дескриптору файла, который, как это было сказано выше, имеет локальное для каждого процесса значение.
При выполнении системного вызова pipe в процесс возвращаются два дескриптора файла, один для записи данных в конвейер, а другой для чтения данных из конвейера. Обычно для выполнения некоторой общей работы ведущий процесс сначала создает конвейер, а затем — несколько процессов-потомков с помощью соответствующего системного вызова. В результате механизм наследования процессов копирует для всех процессов-потомков значения дескрипторов, указывающих на один и тот же конвейер, так что все кооперирующиеся процессы, включая процесс-прародитель, могут использовать этот конвейер для обмена данными. Данные читаются из конвейера с помощью системного вызова read с использованием первого из возвращенных вызовом pipe дескрипторов файла, а записываются в конвейер с помощью системного вызова write с использованием второго дескриптора. Синтаксис системных вызовов read и write тот же, что и при работе с обычными файлами.
Конвейер обеспечивает автоматическую синхронизацию процессов — если при использовании системного вызова read в буфере конвейера нет данных, то процесс, обратившийся к ОС с системным вызовом read, переводится в состояние ожидания и активизируется при появлении данных в буфере.
Механизм конвейеров доступен не только программистам, но и пользователям большинства современных операционных систем. Именно системные вызовы pipe используются оболочкой (командным процессором) операционной системы для организации конвейера команд, когда выходные данные одной команды пользователя становятся входными данными для другой команды. Примером такого конвейера команд может служить показанная ниже строка командного интерпретатора shell ОС UNIX, которая передает выходные данные команды Is (чтение списка имен файлов текущего каталога) на вход команды we (подсчет слов) с ключом -1:
ls | wc -1
Результатом работы этой командной строки будет количество файлов в текущем каталоге.
Именованные конвейеры представляют собой развитие механизма обычных конвейеров. Такие конвейеры имеют имя, которое является записью в каталоге файловой системы ОС, поэтому они пригодны для обмена данными между двумя произвольными процессами или потоками этих процессов.
Именованный конвейер является специальным файлом типа FIFO и не имеет области данных на диске. Создается именованный конвейер с помощью того же системного вызова, который используется и для создания файлов любого типа, но только с указанием в качестве типа файла параметра FIFO. Системный вызов порождает в каталоге запись о файле типа FIFO с заданным именем, после чего любой процесс может открыть этот файл и передавать данные другому процессу, также открывшему файл с этим именем.
Ввиду того что именованные конвейеры основаны на файловой системе, обычные конвейеры, создаваемые системным вызовом pipe, иногда называют программными конвейерами (software-pipes). Следует иметь в виду, что именованные конвейеры используют файловую систему только для хранения имени конвейера в каталоге, а данные между процессами передаются через буфер в оперативной памяти, как и в случае программного конвейера.
Механизм очередей сообщений похож на механизм конвейеров с тем отличием, что он позволяет процессам и потокам обмениваться структурированными сообщениями. При этом синхронизация осуществляется по сообщениям, то есть процесс, пытающийся прочитать сообщение, переводится в состояние ожидания в том случае, если в очереди нет ни одного полного сообщения. Очереди сообщений являются глобальными средствами коммуникаций для процессов операционной системы, как и именованные конвейеры, так как каждая очередь имеет в пределах ОС уникальное имя. В ОС UNIX в качестве такого имени используется числовое значение — так называемый ключ. Ключ является числовым аналогом имени файла, при использовании одного и того же значения ключа процессы будут работать с одной и той же очередью сообщений. Существует также функция, которая преобразует произвольное символьное имя в значение ключа, что позволяет программисту использовать для указания уникальных очередей имена вместо трудно запоминаемых чисел.
Для работы с очередью сообщений процесс должен воспользоваться системным вызовом msgget, указав в качестве параметра значение ключа. Если очередь с данным ключом в настоящий момент не используется ни одним процессом, то для нее резервируется область памяти, а затем процессу возвращается идентификатор очереди, который, как и дескриптор файла, имеет локальное для процесса значение. Если же очередь уже используется, то процессу просто возвращается ее идентификатор. Системный администратор может управлять настройками операционной системы для изменения максимального объема памяти, отводимой очереди, а также максимального размера сообщения.
После открытия очереди процесс может помещать в него сообщения с помощью вызова msgsnd или читать сообщения с помощью вызова msgrsv. Программист может влиять на то, как ОС будет обрабатывать ситуацию, когда процесс пытается читать сообщения, которые еще не поступили в очередь, то есть на синхронизацию процесса с данными. При задании в системных вызовах msgsnd и msgrcv параметра IPC_NOWAIT операционная система в любом случае будет возвращать управление в вызывающий процесс, даже если он пытается прочитать несуществующее сообщение (в последнем случае в процесс возвращается код ошибки). Без этого параметра процесс при отсутствии данных переводится в состояние ожидания. Параметр IPC_NOWAIT используется не только в очередях сообщений, но и в некоторых других средствах IPC, например в семафорах. При использовании параметра IPC_NOWAIT программист должен самостоятельно организовать ожидание данных.
Разделяемая память представляет собой сегмент физической памяти, отображенной в виртуальное адресное пространство двух или более процессов. Механизм разделяемой памяти поддерживается подсистемой виртуальной памяти, которая настраивает таблицы отображения адресов для процессов, запросивших разделение памяти, так что одни и те же адреса некоторой области физической памяти соответствуют виртуальным адресам разных процессов.
1. На какой стадии операция записи данных в специальный файл начинает отличаться от операций записи в дисковый файл в ОС UNIX?
2. Если при поступлении запроса от приложения к файлу система обнаруживает требуемые данные в системном буфере (кэше), то время доступа приложения к нужным ему данным будет:
3. Какая секция блок-ориентированного драйвера ОС UNIX выполняет вывод данных?
4. Какие преимущества связаны с включением в модель драйвера большого количества секций различного типа?
5. Чем функции секции nodev драйвера ОС UNIX отличаются от функций секции nulIdev?
6. Чем принципиально отличается отображение файла в память от кэширования файла с помощью средств менеджера виртуальной памяти?
7. Все ли типы файлов можно отображать в память в ОС UNIX?
8. В каких ситуациях целесообразно использовать асинхронные операции записи в файл?
9. Какие дополнительные меры должны предприниматься при восстановлении файловой системы при наличии дискового кэша?
10. Какие параметры операции с файлом фиксируются в журнале транзакций?
11. Восстанавливаются ли пользовательские данные в NTFS?
12. Из каких двух частей состоит запись о модификации в журнале транзакций Windows NT?
13. Можно ли организовать дисковый массив RAID без специального контроллера?
14. В чем преимущество дисковых массивов RAID-0 по сравнению с обычными дисками?
15. Скорость какого типа операций повышается при использовании дисковых массивов RAID-1?
16. Что такое «динамическое восстановление данных»?
17. В каких случаях обмен данными между процессами можно выполнить только с помощью именованных конвейеров?