ГЛАВА 9
Концепции распределенной обработки в сетевых ОС
Объединение компьютеров в сеть предоставляет возможность программам, работающим на отдельных компьютерах, оперативно взаимодействовать и сообща решать задачи пользователей. Связь между некоторыми программами может быть настолько тесной, что их удобно рассматривать в качестве частей одного приложения, которое называют в этом случае распределенным, или сетевым.
Распределенные приложения обладают рядом потенциальных преимуществ по сравнению с локальными. Среди этих преимуществ — более высокая производительность, отказоустойчивость, масштабируемость и приближение к пользователю.
Модели сетевых служб и распределенных приложений
Значительная часть приложений, работающих в компьютерах сети, являются сетевыми, но, конечно, не все. Действительно, ничто не мешает пользователю запустить на своем компьютере полностью локальное приложение, не использующее имеющиеся сетевые коммуникационные возможности. Достаточно типичным является сетевое приложение, состоящее из двух частей. Например, одна часть приложения работает на компьютере, хранящем базу данных большого объема, а вторая — на компьютере пользователя, который хочет видеть на экране некоторые статистические характеристики данных, хранящихся в базе. Первая часть приложения выполняет поиск в базе записей, отвечающих определенным критериям, а вторая занимается статистической обработкой этих данных, представлением их в графической форме на экране, а также поддерживает диалог с пользователем, принимая от него новые запросы на вычисление тех или иных статистических характеристик. Можно представить себе случаи, когда приложение распределено и между большим числом компьютеров.
Распределенным в сетях может быть не только прикладное, но и системное программное обеспечение — компоненты операционных систем. Как и в случае локальных служб, программы, которые выполняют некоторые общие и часто встречающиеся в распределенных системах функции, обычно становятся частями операционных систем и называются сетевыми службами.
Целесообразно выделить три основных параметра организации работы приложений в сети. К ним относятся:
Способ разделения приложений на части
Очевидно, что можно предложить различные схемы разделения приложений на части, причем для каждого конкретного приложения можно предложить свою схему. Существуют и типовые модели распределенных приложений. В следующей достаточно детальной модели предлагается разделить приложение на шесть функциональных частей:
На основе этой модели можно построить несколько схем распределения частей приложения между компьютерами сети.
Распределение приложения между большим числом компьютеров может повысить качество его выполнения (скорость, количество одновременно обслуживаемых пользователей и т. д.), но при этом существенно усложняется организация самого приложения, что может просто не позволить воспользоваться потенциальными преимуществами распределенной обработки. Поэтому на практике приложение обычно разделяют на две или три части и достаточно редко — на большее число частей. Наиболее распространенной является двухзвенная схема, распределяющая приложение между двумя компьютерами. Перечисленные выше типовые функциональные части приложения можно разделить между двумя компьютерами различными способами.
Рассмотрим сначала два крайних случая двухзвенной схемы, когда нагрузка в основном ложится на один узел — либо на центральный компьютер, либо на клиентскую машину.
В централизованной схеме (рис. 9.1, а) компьютер пользователя работает как терминал, выполняющий лишь функции представления данных, тогда как все остальные функции передаются центральному компьютеру. Ресурсы компьютера пользователя используются в этой схеме в незначительной степени, загруженными оказываются только графические средства подсистемы ввода-вывода ОС, отображающие на экране окна и другие графические примитивы по командам центрального компьютера, а также сетевые средства ОС, принимающие из сети команды центрального компьютера и возвращающие данные о нажатии клавиш и координатах мыши. Программа, работающая на компьютере пользователя, часто называется эмулятором терминала — графическим или текстовым, в зависимости от поддерживаемого режима. Фактически эта схема повторяет организацию многотерминальной системы на базе мэйнфрейма с тем лишь отличием, что вместо терминалов используются компьютеры, подключенные не через локальный интерфейс, а через сеть, локальную или глобальную.
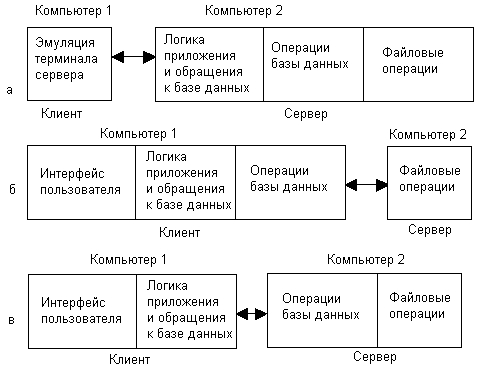
Рис. 9.1. Варианты распределений частей приложения по двухзвенной схеме
Главным и очень серьезным недостатком централизованной схемы является ее недостаточная масштабируемость и отсутствие отказоустойчивости. Производительность центрального компьютера всегда будет ограничителем количества пользователей, работающих с данным приложением, а отказ центрального компьютера приводит к прекращению работы всех пользователей. Именно из-за этих недостатков централизованные вычислительные системы, представленные мэйнфреймами, уступили место сетям, состоящим из мини-компьютеров, RISC-серверов и персональных компьютеров. Тем не менее централизованная схема иногда применяется как из-за простоты организации программы, которая почти целиком работает на одном компьютере, так и из-за наличия большого парка не распределенных приложений.
В схеме «файловый сервер» (рис. 9.1, б) на клиентской машине выполняются все части приложения, кроме файловых операций. В сети имеется достаточно мощный компьютер, имеющий дисковую подсистему большого объема, который хранит файлы, доступ к которым необходим большому числу пользователей. Этот компьютер играет роль файлового сервера, представляя собой централизованное хранилище данных, находящихся в разделяемом доступе. Распределенное приложение в этой схеме мало отличается от полностью локального приложения. Единственным отличием является обращение к удаленным файлам вместо локальных. Для того чтобы в этой схеме можно было использовать локальные приложения, в сетевые операционные системы ввели такой компонент сетевой файловой службы, как редиректор, который перехватывает обращения к удаленным файлам (с помощью специальной нотации для сетевых имен, такой, например, как //server"!/doc/file1.txt) и направляет запросы в сеть, освобождая приложение от необходимости явно задействовать сетевые системные вызовы.
Файловый сервер представляет собой компонент наиболее популярной сетевой службы — сетевой файловой системы, которая лежит в основе многих распределенных приложений и некоторых других сетевых служб. Первые сетевые ОС (NetWare компании Novell, IBM PC LAN Program, Microsoft MS-Net) обычно поддерживали две сетевые службы — файловую службу и службу печати, оставляя реализацию остальных функций разработчикам распределенных приложений.
Такая схема обладает хорошей масштабируемостью, так как дополнительные пользователи и приложения добавляют лишь незначительную нагрузку на центральный узел — файловый сервер. Однако эта архитектура имеет и свои недостатки:
Другие варианты двухзвенной модели более равномерно распределяют функции между клиентской и серверной частями системы. Наиболее часто используется схема, в которой на серверный компьютер возлагаются функции проведения
внутренних операций базы данных и файловых операций (рис. 9.1, в). Клиентский компьютер при этом выполняет все функции, специфические для данного приложения, а сервер — функции, реализация которых не зависит от специфики приложения, из-за чего эти функции могут быть оформлены в виде сетевых служб. Поскольку функции управления базами данных нужны далеко не всем приложениям, то в отличие от файловой системы они чаще всего не реализуются в виде службы сетевой ОС, а являются независимой распределенной прикладной системой. Система управления базами данных (СУБД) является одним из наиболее часто применяемых в сетях распределенных приложений. Не все СУБД являются распределенными, но практически все мощные СУБД, позволяющие поддерживать большое число сетевых пользователей, построены в соответствии с описанной моделью клиент-сервер. Сам термин «клиент-сервер» справедлив для любой двухзвенной схемы распределения функций, но исторически он оказался наиболее тесно связанным со схемой, в которой сервер выполняет функции по управлению базами данных (и, конечно, файлами, в которых хранятся эти базы) и часто используется как синоним этой схемы.
Трехзвенная архитектура позволяет еще лучше сбалансировать нагрузку на различные компьютеры в сети, а также способствует дальнейшей специализации серверов и средств разработки распределенных приложений. Примером трехзвенной архитектуры может служить такая организация приложения, при которой на клиентской машине выполняются средства представления и логика представления, а также поддерживается программный интерфейс для вызова частей приложения второго звена — промежуточного сервера (рис. 9.2).
Промежуточный сервер называют в этом варианте сервером приложений, так как на нем выполняются прикладная логика и логика обработки данных, представляющих собой наиболее специфические и важные части большинства приложений. Слой логики обработки данных вызывает внутренние операции базы данных, которые реализуются третьим звеном схемы — сервером баз данных.
Сервер баз данных, как и в двухзвенной модели, выполняет функции двух последних слоев — операции внутри базы данных и файловые операции. Примером такой схемы может служить неоднородная архитектура, включающая клиентские компьютеры под управлением Windows 95/98, сервер приложений с монитором транзакций TUXEDO в среде Solaris на компьютере компании Sun Microsystems и сервер баз данных Oracle в среде Windows 2000 на компьютере компании Compaq.
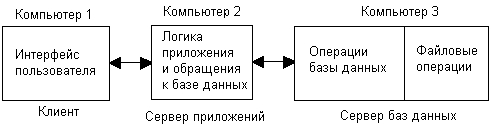
Рис. 9.2. Трехзвенная схема распределения частей приложения
Централизованная реализация логики приложения решает проблему недостаточной вычислительной мощности клиентских компьютеров для сложных приложений, а также упрощает администрирование и сопровождение. В том случае когда сервер приложений сам становится узким местом, в сети можно применить несколько серверов приложений, распределив каким-то образом запросы пользователей между ними. Упрощается и разработка крупных приложений, так как в этом случае четко разделяются платформы и инструменты для реализации интерфейса и прикладной логики, что позволяет с наибольшей эффективностью реализовывать их силами специалистов узкого профиля.
Монитор транзакций представляет собой популярный пример программного обеспечения, не входящего в состав сетевой ОС, но выполняющего функции, полезные для большого количества приложений. Такой монитор управляет транзакциями с базой данных и поддерживает целостность распределенной базы данных.
Трехзвенные схемы часто применяются для централизованной реализации в сети некоторых общих для распределенных приложений функций, отличных от файлового сервиса и управления базами данных. Программные модули, выполняющие такие функции, относят к классу middleware — то есть промежуточному слою, располагающемуся между индивидуальной для каждого приложения логикой и сервером баз данных.
В крупных сетях для связи клиентских и серверных частей приложений также используется и ряд других средств, относящихся к классу middleware, в том числе:
Эти средства помогают улучшить качество взаимодействия клиентов с серверами за счет промышленной реализации достаточно важных и сложных функций, а также упорядочить поток запросов от множества клиентов к множеству серверов, играя роль регулировщика, распределяющего нагрузку на серверы.
Сервер приложений должен базироваться на мощной аппаратной платформе (мультипроцессорные системы, специализированные кластерные архитектуры). ОС сервера приложений должна обеспечивать высокую производительность вычислений, а значит, поддерживать многопоточную обработку, вытесняющую многозадачность, мультипроцессирование, виртуальную память и наиболее популярные прикладные среды.
Механизм передачи сообщений в распределенных системах
Единственным по-настоящему важным отличием распределенных систем от централизованных является способ взаимодействия между процессами. Принципиально межпроцессное взаимодействие может осуществляться одним из двух способов:
В централизованных системах связь между процессами, как правило, предполагает наличие разделяемой памяти. Типичный пример — задача «поставщик-потребитель». В этом случае один процесс пишет в разделяемый буфер, а другой читает из него. Даже наиболее простая форма синхронизации — семафор — требует, чтобы хотя бы одно слово (переменная самого семафора) было разделяемым. Аналогичным образом происходит взаимодействие не только между пользовательскими процессами, но и между приложением и операционной системой — процесс в пользовательском режиме запрашивает у ОС выполнения некоторой операции с помощью системного вызова, помещая в доступную ему часть оперативной памяти параметры этого системного вызова (например, имя файла, смещение от его начала и количество байт, которые необходимо прочитать). После этого модуль ядра ОС считывает эти параметры из пользовательской памяти (ядру в привилегированном режиме доступна вся память, как ее системная часть, так и пользовательская) и выполняет системный вызов. Взаимодействие и в этом случае происходит за счет непосредственно доступной обоим участникам области памяти.
В распределенных системах не существует памяти, непосредственно доступной процессам, работающим на разных компьютерах, поэтому взаимодействие процессов (как находящихся в пользовательской фазе, так и в системной, то есть выполняющих код операционной системы) может осуществляться только путем передачи сообщений через сеть. Как было показано в разделе «Сетевые службы и сетевые сервисы» главы 2 «Назначение и функции операционной системы», на основе механизма передачи сообщений работают все сетевые службы, предоставляющие пользователям сети разнообразные услуги — доступ к удаленным файлам, принтерам, почтовым ящикам и т. п. В сообщениях переносятся запросы от клиентов некоторой службы к соответствующим серверам — например, запрос на просмотр содержимого определенного каталога файловой системы, расположенной на сетевом сервере. Сервер возвращает ответ — набор имен файлов и подкаталогов, входящих в данный каталог, также помещая его в сообщение и отправляя его по сети клиенту.
Сообщение — это блок информации, отформатированный процессом-отправителем таким образом, чтобы он был понятен процессу-получателю. Сообщение состоит из заголовка, обычно фиксированной длины, и набора данных определенного типа переменной длины. В заголовке, как правило, содержатся следующие элементы.
В любой сетевой ОС имеется подсистема передачи сообщений, называемая также транспортной подсистемой, которая обеспечивает набор средств для организации взаимодействия процессов по сети. Назначение этой системы — экранировать детали сложных сетевых протоколов от программиста. Подсистема позволяет процессам взаимодействовать посредством достаточно простых примитивов. В самом простом случае системные средства обеспечения связи могут быть сведены к двум основным коммуникационным примитивам, один send (отправить) — для посылки сообщения, другой recei ve (получить) — для получения сообщения. В дальнейшем на их базе могут быть построены более мощные средства сетевых коммуникаций, такие как распределенная файловая система или служба вызова удаленных процедур, которые, в свою очередь, также могут служить основой для работы других сетевых служб.
Транспортная подсистема сетевой ОС имеет обычно сложную структуру, отражающую структуру семиуровневой модели взаимодействия открытых систем (Open System Interconnection, OSI)1. Представление сложной задачи сетевого взаимодействия компьютеров в виде иерархии нескольких частных задач позволяет организовать это взаимодействие максимально гибким образом. В то же время каждый уровень модели OSI экранирует особенности лежащих под ним уровней от вышележащих уровней, что делает средства взаимодействия компьютеров все более универсальными по мере продвижения вверх по уровням. Таким образом, в процесс выполнения примитивов send и receive вовлекаются средства всех нижележащих коммуникационных протоколов (рис. 9.3).
1 Более подробно с моделью OSI и функциями ее уровней можно ознакомится в приложе-! нии. Структура сетевых средств ОС обсуждалась также в разделе «Многослойная модель .-.подсистемы ввода-вывода» главы 7 «Ввод-вывод и файловая система».
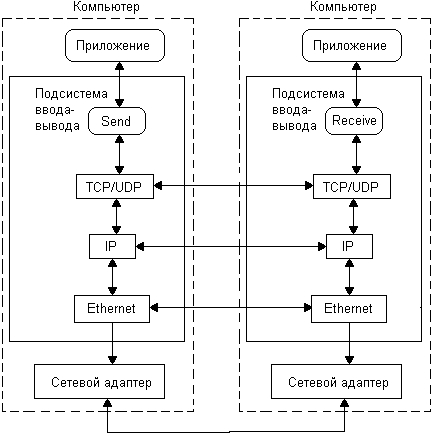
Рис. 9.3. Примитивы обмена сообщениями и транспортные средства подсистемы ввода-вывода
Несмотря на концептуальную простоту примитивов send и receive, существуют различные варианты их реализации, от правильного выбора которых зависит эффективность работы сети. В частности, эффективность зависит от способа задания адреса получателя. Не менее важны при реализации примитивов передачи сообщений ответы и на другие вопросы. В сети всегда имеется один получатель или их может быть несколько? Требуется ли гарантированная доставка сообщений? Должен ли отправитель дождаться ответа на свое сообщение, прежде чем продолжать свою работу? Как отправитель, получатель и подсистема передачи сообщений должны реагировать на отказы узла или коммуникационного канала во время взаимодействия? Что нужно делать, если приемник не готов принять сообщение, нужно ли отбрасывать сообщение или сохранять его в буфере? А если сохранять, то как быть, если буфер уже заполнен? Разрешено ли приемнику изменять порядок обработки сообщений в соответствии с их важностью? Ответы на подобные вопросы составляют семантику конкретного протокола передачи сообщений.
Центральным вопросом взаимодействия процессов в сети является способ их синхронизации, который полностью определяется используемыми в операционной системе коммуникационными примитивами. В этом отношении коммуникационные примитивы делятся на блокирующие (синхронные) и неблокирующие (асинхронные), причем смысл данных терминов в целом соответствует смыслу аналогичных терминов, применяемых при описании системных вызовов (см. подраздел «Системные вызовы» раздела «Мультипрограммирование на основе прерываний» в главе 4 «Процессы и потоки») и операций ввода-вывода (см. подраздел «Поддержка синхронных и асинхронных операций ввода-вывода» раздела «Задачи ОС по управлению файлами и устройствами» в главе 7 «Ввод-вывод и файловая система»). В отличие от локальных системных вызовов (а именно такие системные вызовы были рассмотрены в главах 4 и 7) при выполнении коммуникационных примитивов завершение запрошенной операции в общем случае зависит не только от некоторой работы локальной ОС, но и от работы удаленной ОС.
Коммуникационные примитивы могут быть оформлены в операционной системе двумя способами: как внутренние процедуры ядра ОС (в этом случае ими могут использоваться только модули ОС) или как системные вызовы (доступные в этом случае процессам в пользовательском режиме).
При использовании блокирующего примитива send процесс, выдавший запрос на его выполнение, приостанавливается до момента получения по сети сообщения-подтверждения о том, что приемник получил отправленное сообщение. А вызов блокирующего примитива receive приостанавливает вызывающий процесс до момента, когда он получит сообщение. При использовании неблокирующих примитивов send и receive управление возвращается вызывающему процессу немедленно, сразу после того, как ядру передается информация о том, где в памяти находится буфер, в который нужно поместить сообщение, отправляемое в сеть или ожидаемое из сети. Преимуществом этой схемы является параллельное выполнение вызывающего процесса и процедур передачи сообщения (не обязательно работающих в контексте вызвавшего соответствующий примитив процесса).
Важным вопросом при использовании неблокирующего примитива receive является выбор способа уведомления процесса-получателя о том, что сообщение пришло и помещено в буфер. Обычно для этой цели требуется один из двух способов.
При использовании блокирующего примитива send может возникнуть ситуация, когда процесс-отправитель блокируется навсегда. Например, если процесс получатель потерпел крах или же отправленное сообщение было утеряно из-за сетевой ошибки. Чтобы предотвратить такую ситуацию, блокирующий примитив send часто использует механизм тайм-аута. То есть определяется интервал времени, после которого операция send завершается со статусом «ошибка». Механизм тайм-аута может использоваться также блокирующим примитивом receive для предотвращения блокировки процесса-получателя на неопределенное время, когда процесс-отправитель потерпел крах или сообщение было потеряно вследствие сетевой ошибки.
Если при взаимодействии двух процессов оба примитива — send и receive — являются блокирующими, говорят^ что процессы взаимодействуют по сети синхронно (рис. 9.4), в противном случае взаимодействие считается асинхронным (рис. 9.5).
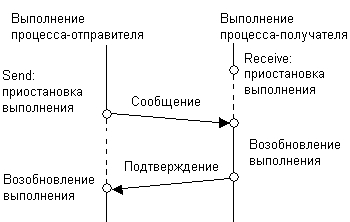
Рис. 9.4. Синхронное взаимодействие с помощью блокирующих примитивов send и receive
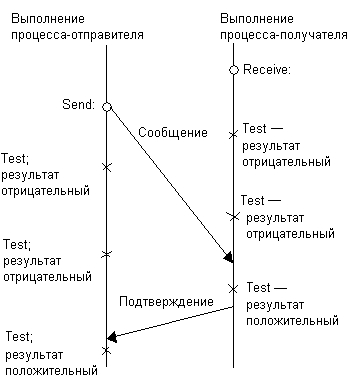
Рис. 9.5. Асинхронное взаимодействие с помощью неблокирующих примитивов send и receive
По сравнению с асинхронным взаимодействием синхронное является более простым, его легко реализовать. Оно также более надежно, так как гарантирует процессу-отправителю, возобновившему свое выполнение, что его сообщение было получено. Главный же недостаток — ограниченный параллелизм и возможность возникновения клинчей.
Обычно в ОС имеется один из двух видов примитивов, но ОС является более гибкой, если поддерживает как блокирующие, так и неблокирующие примитивы.
Буферизация в примитивах передачи сообщений
При передаче сообщений могут возникнуть ситуации, когда принимающий процесс оказывается не готовым обработать сообщение при его прибытии, но для процесса было бы желательным, чтобы операционная система на время сохранила поступившее сообщение в буфере для последующей обработки.
Способ буферизации тесно связан со способом синхронизации процессов при обмене сообщениями. При использовании синхронных, то есть блокирующих примитивов, можно вообще обойтись без буферизации сообщений операционной системой. При этом возможны два варианта организации работы примитивов. В первом случае процесс-отправитель подготавливает сообщение в своей памяти и обращается к примитиву send, после чего процесс блокируется. Операционная система отправителя ждет, когда процесс-получатель выполнит на своем компьютере примитив receive, в результате чего ОС получателя направит служебное сообщение-подтверждение готовности к приему основного сообщения. После получения такого подтверждения ОС на компьютере-отправителе разблокирует процесс-отправитель и тот немедленно после этого пошлет сообщение по сети. Процесс-получатель после обращения к примитиву receive также переводится своей ОС в состояние ожидания, из которого он выходит при поступлении сообщения по сети. Сообщение немедленно копируется ОС в память процесса-получателя, не требуя буферизации, так как процесс ожидает его прихода и готов к его обработке.
Буферизация не требуется и при другом варианте обмена сообщениями, когда процесс-отправитель посылает сообщение в сеть, не дожидаясь прихода от получателя подтверждения о готовности к приему. Затем процесс-отправитель блокируется либо до прихода такого подтверждения (в этом случае никакой дополнительной работы с данным сообщением не выполняется), либо до истечения тайм-аута, после которого сообщение посылается вновь, причем в случае многократных повторных неудачных попыток сообщение отбрасывается.
В обоих случаях сообщение непосредственно из памяти процесса-отправителя попадает в сеть, а после прихода из сети — в память процесса-получателя, минуя буфер, поддерживаемый системой. Однако такая организация на практике в сетевых операционных системах не применяется, так как в первом варианте процесс-получатель может достаточно долго ждать, пока сообщение будет передано по сети (в большой составной сети, например в Интернете, задержки могут достигать нескольких секунд), а во втором — из-за неготовности процесса-получателя сообщение может многократно бесполезно передаваться по сети, засоряя каналы связи.
Именно поэтому при использовании синхронных примитивов все же предусматривают буферизацию. При этом буфер, как правило, выбирается размером в одно сообщение, так как процесс-отправитель не может послать следующее сообщение, не получив подтверждения о приеме предыдущего. Сообщение помещается в буфер, поддерживаемый операционной системой компьютера-получателя, если в момент его прихода процесс-получатель не может обработать сообщение немедленно, например из-за того, что процесс либо не является текущим, либо не готов к приему сообщения, так как не обратился к примитиву receive. Буфер может располагаться как в системной области памяти, так и в области памяти пользовательского процесса, в любом случае буфером управляет операционная система, модули которой получают сообщения по сети.
Для всех вариантов обмена сообщениями с помощью асинхронных примитивов необходима буферизация. Поскольку при асинхронном обмене процесс-отправитель может посылать сообщение всегда, когда ему это требуется, не дожидаясь подтверждения от процесса-получателя, для исключения потерь сообщений требуется буфер неограниченной длины. Так как буфер в реальной системе всегда имеет ограниченный размер, то могут возникать ситуации с переполнением буфера и на них нужно каким-то образом реагировать. Для уменьшения вероятности потерь сообщений степень асинхронности процесса обмена сообщениями обычно ограничивается механизмом управления потоком сообщений. Управление потоком заключается в том, что при заполнении буфера на принимающей стороне до некоторого опасного порога процесс-передатчик блокируется до тех пор, пока процесс-приемник не обработает часть принятых сообщений и не разгрузит буфер до безопасной величины. Конечно, вероятность потерь сообщений из-за переполнения буфера все равно сохраняется, например из-за того, что служебное сообщение о необходимости приостановки передачи сообщений может быть потеряно сетью. Асинхронный обмен с управлением потоком — это наиболее сложный способ организации обмена сообщениями, так как для повышения эффективности, то есть максимизации скорости обмена и минимизации потерь, он требует применения сложных алгоритмов приостановки и возобновления процесс передачи, например таких, которые применяются в протоколе TCP.
Обычно операционная система предоставляет для прикладных процессов специальный примитив для создания буферов сообщений. Такого рода примитив, назовем его, например, create_buffer (создать буфер), процесс должен использовать перед тем, как отправлять или получать сообщения с помощью примитивов send и receive. При создании буфера его размер может либо устанавливаться по умолчанию, либо выбираться прикладным процессом. Часто такой буфер носит название порта (port), или почтового ящика {mailbox).
При реализации схем буферизации сообщений необходимо также решить вопрос о том, что должна делать операционная система с поступившими сообщениями, для которых буфер не создан. Такая ситуация может возникнуть в том случае, когда примитив send на одном компьютере выполнен раньше, чем примитив create_buffer на другом. Каким образом ядро на компьютере получателя сможет узнать, какому процессу адресовано вновь поступившее сообщение, если имеется несколько активных процессов? И как оно узнает, куда его скопировать?
Один из вариантов — просто отказаться от сообщения в расчете на то, что отправитель после тайм-аута передаст сообщение повторно и к этому времени получатель уже создаст буфер. Этот подход не сложен в реализации, но, к сожалению, отправитель (или скорее ядро его компьютера) может сделать несколько таких безуспешных попыток. Еще хуже то, что после достаточно большого числа безуспешных попыток ядро отправителя может сделать неправильный вывод об аварии на машине получателя или о неправильности его адреса.
Второй подход к этой проблеме заключается в том, чтобы хранить хотя бы некоторое время поступающие сообщения в ядре получателя в расчете на то, что вскоре будет выполнен соответствующий примитив create_buffer. Каждый раз, когда поступает такое «неожидаемое» сообщение, включается таймер. Если заданный временной интервал истекает раньше, чем происходит создание буфера, то сообщение теряется.
Хотя этот метод и уменьшает вероятность потери сообщений, он порождает проблему хранения и управления преждевременно поступившими сообщениями. Необходимы буферы, которые следует где-то размещать, освобождать, то есть которыми нужно как-то управлять, что создает дополнительную нагрузку на операционную систему.
Для того чтобы послать сообщение, необходимо указать адрес получателя. В очень простой сети адрес может задаваться в виде константы, но в сложных сетях нужен более гибкий способ адресации.
Одним из вариантов адресации является использование аппаратных адресов сетевых адаптеров. Если в получающем компьютере выполняется только один процесс, то ядро ОС будет знать, что делать с поступившим сообщением — передать его этому процессу. Однако если на машине выполняется несколько процессов, то ядру не известно, какому из них предназначено сообщение, поэтому использование сетевого адреса адаптера в качестве адреса получателя приводит к очень серьезному ограничению — на каждой машине должен выполняться только один процесс. Кроме того, на основе аппаратного адреса сетевого адаптера сообщения можно передавать только в пределах одной локальной сети, в более сложных сетях, состоящих из нескольких подсетей, в том числе и глобальных, для передачи данных между узлами требуются числовые адреса, несущие информацию как о номере узла, так и о номере подсети, например IP-адреса.
Наибольшее распространение получила система адресации, в которой адрес состоит из двух частей, определяющих компьютер и процесс, которому предназначено сообщение, то есть адрес имеет вид пары числовых идентификаторов: mach1ne_id@local_id. В качестве идентификатора компьютера machine_id наиболее употребительным на сегодня является использование IP-адреса, который представляет собой 32-битовое число, условно записываемое в виде четырех десятичных чисел, разделенных точками, например 185.23.123.26. Идентификатором компьютера может служить любой другой тип адреса узла, который воспринимается транспортными средствами сети, например IPX-адрес, ATM-адрес или уже упоминавшийся аппаратный адрес сетевого адаптера, если система передачи сообщений ОС работает только в пределах одной локальной сети.
Для адресации процесса в этом способе применяется числовой идентификатор local_id, имеющий уникальное в пределах узла machine_1d значение. Этот идентификатор может однозначно указывать на конкретный процесс, работающий на данном компьютере, то есть являться идентификатором типа processed. Однако существует и другой подход, функциональный, при котором используется адрес службы, которой пересылается сообщение, при этом идентификатор принимает вид service_id. Последний вариант более удобен для отправителя, так как службы, поддерживаемые сетевыми операционными системами, представляют собой достаточно устойчивый набор (в него входят, как правило, наиболее популярные службы FTP, SMB, NFS, SMTP, HTTP, SNMP) и этим службам можно дать вполне определенные адреса, заранее известные всем отправителям. Такие адреса называют «хорошо известными» (well-known). Примером хорошо известных адресов служб являются номера портов в протоколах TCP и UDP. Отправитель всегда знает, что, посылая с помощью этих протоколов сообщение на порт 21 некоторого компьютера, он посылает его службе FTP, то есть службе передачи файлов. При этом отправителя не интересует, какой именно процесс (с каким локальным идентификатором) реализует в настоящий момент времени услуги FTP на данном компьютере.
Ввиду повсеместного применения стека протоколов TCP/IP номера портов являются на сегодня наиболее популярными адресами служб в системах обмена сообщениями сетевых ОС. Порт TCP/UDP является не только абстрактным адресом службы, но и представляет собой нечто более конкретное — для каждого порта операционная система поддерживает буфер в системной памяти, куда помещаются отправляемые и получаемые сообщения, адресуемые данному порту. Порт задается в протоколах TCP/UDP двухбайтным адресом, поэтому ОС может поддерживать до 65 535 портов. Кроме хорошо известных номеров портов, которым отводится диапазон от 1 до 1023, существуют и динамически используемые порты со старшими номерами. Значения этих портов не закрепляются за определенными службами, поэтому они часто дополняют хорошо известные порты для обмена в рамках обслуживания некоторой службы сообщениями специфического назначения. Например, клиент FTP всегда начинает взаимодействие с сервером FTP отправкой сообщения на порт 21, а после установления сеанса обмен данными между клиентом и сервером выполняется уже по порту, номер которого динамически выбирается в процессе установления сеанса.
Описанная схема адресации типа «машина-процесс» или «машина-служба» хорошо зарекомендовала себя, работая уже на протяжении многих лет в Интернете, а также в корпоративных сетях IP и IPX (в этих сетях также используется адресация службы, а не процесса). Однако эта схема имеет один существенный недостаток — она не гибка и не прозрачна, так как пользователь должен явно указывать адрес машины-получателя. В этом случае, если в один прекрасный день машина, на которой работает некоторая служба, отказывает, то программа, в которой все обращения к данной службе выполняются по жестко заданному адресу, не сможет использовать аналогичную службу, установленную на другой машине.
Основным способом повышения степени прозрачности адресации является использование символьных имен вместо числовых. Примером такого подхода является характерная для сегодняшнего Интернета нотация URL (Universal Resource Locator, универсальный указатель ресурса), в соответствии с которой адрес состоит из символьного имени узла и символьного имени службы. Например, если в сообщении указан адрес ftp://arc.bestcompany.ru/, то это означает, что оно отправлено службе ftp, работающей на компьютере arc.bestcompany.ru. Использование символьных имен требует создания в сети службы оперативного отображения символьных имен на числовые идентификаторы, поскольку именно в таком виде адреса распознаются сетевым оборудованием. Применение символьного имени позволяет разорвать жесткую связь адреса с одним-единственным компьютером, так как символьное имя перед отправкой сообщения в сеть заменяется на числовое, например на IP-адрес. Этап замены позволяет сопоставить с символьным именем различные числовые адреса и выбрать тот компьютер, который в данный момент в наибольшей степени подходит для выполнения запроса, содержащегося в сообщении. Например, отправляя запрос на получение услуг службы Web от компании Microsoft по адресу http://www.microsoft.com/, вы точно не знаете, какой из нескольких серверов этой компании, предоставляющих данный вид услуг и обслуживающих один и тот же символьный адрес, ответит вам.
Для замены символьных адресов на числовые применяются две схемы: широковещание и централизованная служба имен. Широковещание удобно в локальных сетях, в которых все сетевые технологии нижнего уровня, такие как Ethernet, Token Ring, FDDI, поддерживают широковещательные адреса в пределах всей сети, а пропускной способности каналов связи достаточно для обслуживания таких запросов для сравнительного небольшого количества клиентов и серверов. На широковещании были построены все службы ОС NetWare (до версии 4), ставшие в свое время эталоном прозрачности для пользователей. В этой схеме сервер периодически широковещательно рассылает по сети сообщения о соответствии числовым адресам его имени и имен служб, которые он поддерживает. Клиент также может сделать широковещательный запрос о наличии в сети сервера, поддерживающего определенную службу, и если такой сервер в сети есть, то он ответит на запрос своим числовым адресом. После обмена подобными сообщениями пользователь должен явно указать в своем запросе имя сервера, к ресурсам которого он обращается, а клиентская ОС заменит это имя на числовой адрес в соответствии с информацией, широковещательно распространенной сервером. Однако широковещательный механизм разрешения адресов плохо работает в территориальных сетях, так как наличие большого числа клиентов и серверов, а также использование менее скоростных по сравнению с локальными сетями каналов делают широковещательный трафик слишком интенсивным, практически не оставляющим пропускной способности для передачи пользовательских данных. В территориальных сетях для разрешения символьных имен компьютеров применяется другой подход, основанный на специализированных серверах, хранящих базу данных соответствия между символьными именами и числовыми адресами. Эти серверы образуют распределенную службу имен, обрабатывающую запросы многочисленных клиентов. Хорошо известным примером такой службы является служба доменных имен Интернета (Domain Name Service, DNS). Эта служба позволяет обрабатывать в реальном масштабе времени многочисленные запросы пользователей Интернета, обращающихся к ресурсам серверов по составным именам, таким как http://www.microsoft.com/ или http://www.gazeta.ru/. Другим примером может служить служба каталогов (NetWare Directory Sevices, NDS) компании Novell, которая выполняет в крупной корпоративной сети более общие функции, предоставляя справочную информацию по любым сетевым ресурсам, в том числе и по соответствию символьных имен компьютеров их числовым адресам.
Централизованная служба имен на сегодня считается наиболее перспективным средством повышения прозрачности услуг для пользователей сетей. С такой службой связывают и перспективы дальнейшего повышения прозрачности адресации сетевых ресурсов, когда имя ресурса будет полностью независимо от компьютера, предоставляющего этот ресурс в общее пользование. Например, в службе NDS уже сегодня можно использовать такие имена, как имена томов, не указывая их точного расположения на том или ином компьютере. При перемещении тома с одного компьютера на другой изменение связи тома с компьютером регистрируется в базе службы NDS, так что все обращения к тому после его перемещения разрешаются корректно путем замены имени адресом нового компьютера. По пути применения централизованной службы-посредника между клиентами и ресурсами идут и разработчики распределенных приложений, например разработчики технологии CORBA, в которой запросы к программным модулям приложений обрабатывает специальный элемент — брокер запросов.
Использование символьных имен вместо числовых адресов несколько повышает прозрачность, но не до той степени, которой хотелось бы достичь приверженцам идеи распределенных операционных систем, главным отличием которых от сетевых ОС является именно полная прозрачность адресации разделяемых ресурсов. Тем не менее символьные имена — это значительный шаг вперед по сравнению с числовыми.
Надежные и ненадежные примитивы
Ранее подразумевалось, что когда отправитель посылает сообщение, адресат его обязательно получает. Но на практике сообщения могут теряться. Предположим, что для обмена сообщениями используются блокирующие примитивы. Когда отправитель посылает сообщение, то он приостанавливает свою работу до тех пор, пока сообщение не будет послано. Однако нет никаких гарантий, что после того, как он возобновит свою работу, сообщение будет доставлено адресату.
Для решения этой проблемы существуют три подхода. Первый заключается в том, что система не берет на себя никаких обязательств по поводу доставки сообщений. Такой способ доставки сообщений обычно называют дейтаграммным (datagram). Реализация надежного взаимодействия при его применении целиком становится заботой прикладного программиста.
Второй подход заключается в том, что ядро принимающей машины посылает квитанцию-подтверждение ядру отправляющей машины на каждое сообщение или на группу последовательных сообщений. Посылающее ядро разблокирует пользовательский процесс только после получения такого подтверждения. Обработкой подтверждений занимается подсистема обмена сообщениями ОС, ни процесс-отправитель, ни процесс-получатель их не видят.
Третий подход заключается в использовании ответа в качестве подтверждения в тех системах, в которых запрос всегда сопровождается ответом, что характерно для клиент-серверных служб. В этом случае служебные сообщения-подтверждения не используются, так как в их роли выступают пользовательские сообщения-ответы. Процесс-отправитель остается заблокированным до получения ответа. Если же ответа нет слишком долго, то после истечения тайм-аута ОС отправителя повторно посылает запрос.
Надежная передача сообщений может подразумевать не только гарантию доставки отдельных сообщений, но и упорядоченность этих сообщений, при которой процесс-получатель извлекает из системного буфера сообщения в том же порядке, в котором они были отправлены. Для надежной и упорядоченной доставки чаще всего используется обмен с предварительным установлением соединения, причем на стадии установления соединения (называемого также сеансом) стороны обмениваются начальными номерами сообщений, чтобы можно было в процессе обмена отслеживать как факт доставки отдельных сообщений последовательности, так и упорядочивать их (сами сетевые технологии не всегда гарантируют, что порядок доставки сообщений будет совпадать с порядком их отправки, например из-за того, что разные сообщения могут доставляться адресату по разным маршрутам).
В хорошей подсистеме обмена сообщения должны поддерживаться как ненадежные примитивы, так и надежные. Это позволяет прикладному программисту использовать тот тип примитивов, который в наибольшей степени подходит для организации взаимодействия в той или иной ситуации. Например, для передачи данных большого объема, транспортируемых по сети в нескольких сообщениях (в сетях обычно существует ограничение на максимальный размер поля данных, из-за чего данные приходится пересылать в нескольких сообщениях), больше подходит надежный вид обмена с упорядочиванием сообщений. А вот для взаимодействия типа «короткий запрос — короткий ответ» предпочтительны ненадежные примитивы. Действительно, вероятность потери отдельного сообщения не так уж велика, а скорость такого обмена будет выше, чем при применении надежных примитивов, поскольку на установление необходимого в этом случае соединения тратится дополнительное время.
Для реализации примитивов с различной степенью надежности передачи сообщений система обмена сообщениями ОС использует различные коммуникационные протоколы. Так, если сообщения передаются через IP-сеть, то для надежной передачи сообщений используется протокол транспортного уровня TCP, работающий с установлением соединений, обеспечивающий гарантированную и упорядоченную доставку и управляющий потоком данных при обмене. Если же надежность при передаче сообщений не требуется, то будет использован протокол UDP, обеспечивающий быструю доставку небольших сообщений без всяких
гарантий. Аналогично при работе через сети Novell для надежной доставки сообщений используется протокол SPX, а для дейтаграммной — IPX. В стеке OSI существует один транспортный протокол, но он поддерживает несколько режимов, отличающихся степенью надежности.
Механизм сокетов (sockets) впервые появился в версии 4.3 BSD UNIX (Berkeley Software Distribution UNIX — ветвь UNIX, начавшая развиваться в калифорнийском университете Беркли). Позже он превратился в одну из самых популярных систем сетевого обмена сообщениями. Сегодня этот механизм реализован во многих операционных системах, иногда его по-прежнему называют Berkeley Sockets, отдавая дань уважения его создателям, хотя существует большое количество его реализаций как для различных ОС семейства UNIX, так и для других ОС, например для ОС семейства Windows, где он носит название Windows Sockets (WinSock).
Механизм сокетов обеспечивает удобный и достаточно универсальный интерфейс обмена сообщениями, предназначенный для разработки сетевых распределенных приложений. Его универсальность обеспечивают следующие концепции.
Для обмена сообщениями механизм сокетов предлагает следующие примитивы, реализованные как системные вызовы.
s = socket(domain, type, protocol)
Процесс должен создать сокет перед началом его использования. Системный вызов socket создает новый сокет с параметрами, определяющими коммуникационный домен (domain), тип соединения, поддерживаемого сокетом (type), и транспортный протокол (например, TCP или UDP), который будет поддерживать это соединение. Если транспортный протокол не задан, то система сама выбирает протокол, соответствующий типу сокета. Указание домена определяет возможные значения остальных двух параметров. Системный вызов socket возвращает дескриптор созданного сокета, который используется как идентификатор сокета в последующих операциях.
bind(s. addr. addrlen)
Системный вызов bind связывает созданный сокет с его высокоуровневым именем либо с низкоуровневым адресом. Адрес addr относится к тому узлу, на котором расположен сокет. Для низкоуровневого адреса домена Интернета адресом будет пара (IP-адрес, порт). Третий параметр делает адрес доменно-независимым, позволяя задавать адреса различных типов, в том числе символьные. Связывать сокет с адресом необходимо только в том случае, если на данный сокет будут приниматься сообщения.
connect(s, server_addr. server_addrlen)
Системный вызов connect используется только в том случае, если предполагается передавать сообщения в потоковом режиме, который требует установления соединения. Процедура установления несимметрична: один процесс (процесс-сервер) ждет запроса на установление соединения, а второй (процесс-клиент) — инициирует соединение, посылая такой запрос. Системный вызов connect является запросом клиента на установление соединения с сервером. Второй и третий аргументы вызова указывают адрес сокета сервера, с которым устанавливается соединение. После установления соединения сообщения по нему могут передаваться в дуплексном режиме, то есть в любом направлении. Системный вызов write, используемый для передачи сообщений в рамках установленного соединения, не требует указания адреса сокета получателя, так как локальный сокет, через который сообщение отправляется, уже соединен с определенным удаленным сокетом. Способ, с помощью которого клиенты узнают адрес сокета сервера, не стандартизован.
listen (s. backlog)
Системный вызов listen используется для организации режима ожидания сервером запросов на установление соединения. Система обмена сообщениями после отработки данного системного вызова будет принимать запросы на установление, имеющие адрес сокета s, и передавать их на обработку другому системному вызову — accept, который решает, принимать их или отвергать.Аргумент backlog оговаривает максимальное число хранимых системой запросов на установление соединения, ожидающих принятия.
snew = accept(s. client_addr. client_addr1en)
Системный вызов accept используется сервером для приема запроса на установление соединения, поступившего от системного вызова 11 sten через сокет s от клиента с адресом cl ient_addr (если этот аргумент опущен, то принимается запрос от любого клиента). При этом создается новый сокет snew, через который и устанавливается соединение с данным клиентом. Таким образом, сокет s используется сервером для приема запросов на установление соединения от клиентов, а сокеты snew — для обмена сообщениями с клиентами по индивидуальным соединениям.
write(s. message, msgjen)
Сообщение длиной msg_len, хранящееся в буфере message, отправляется получателю, с которым предварительно соединен сокет s.
Mbytes =read(snew, buffer, amount)
Сообщение, поступившее через сокет snew, с которым предварительно соединен отправитель, принимается в буфер buffer размером amount. Если сообщений нет, то процесс-получатель блокируется.
sendto(s. message, receiver_address)
Так как сообщение отправляется без предварительного установления соединения, то в каждом системном вызове sendto необходимо указывать адрес со-кета получателя.
amount = recvfrom(s, message, sender_address)
Аналогично предыдущему вызову при приеме без установленного соединения в каждом вызове recvfrom указывается адрес сокета отправителя, от которого нужно принять сообщение. Если сообщений нет, то процесс-получатель блокируется.
Рассмотрим использование системных вызовов механизма сокетов для организации обмена сообщениями между двумя узлами.
Для обмена короткими сообщениями, не требующими надежной доставки и упорядоченности, целесообразно воспользоваться системными вызовами, не требующими установления соединения. Фрагмент программы процесса-отправителя может выглядеть так:
s = socket(AF_INET. SOCKJJGRAM.0):
bind(s, sender_addr, sender_addrlen):
sendto(s, message, receiver_addr);
close(s):
Соответственно для процесса-получателя:
s =socket(AF_INET, SOCK_DGRAM,0);
bind(s. receiver_addr, receiver_addrlen):
amount = recvfrom(s, message, sender_addr):
close(s);
Константа AF_INET определяет, что обмен ведется в коммуникационном домене Интернета, а константа SOCK_DGRAM задает дейтаграммный режим обмена без установления соединения. Выбор транспортного протокола оставлен на усмотрение системы.
Если же необходимо организовать обмен сообщениями надежным способом с упорядочением, то фрагменты программ будут выглядеть следующим образом.
Для процесса-клиента:
s =socket(AF_INET. SOCK_STREAM.0);
connect(s, server_addr, server_addrlen);
wrlte(s, message, msgjen);
wrlte(s, message, msgjen);
closets):
Для процесса-сервера:
s = socket(AFJNET. SOCKJTREAM.0):
bind(s, server_addr, server_addrlen);
1isten(s, backlog):
snew - accept(s. c11ent_addr, cl1ent_addrlen);
nbytes =read(snew, buffer, amount);
nbytes = read(snew, buffer, amount);
close(s);
Еще одним удобным механизмом, облегчающим взаимодействие операционных систем и приложений по сети, является механизм
вызова удаленных процедур (Remote Procedure Call, RPC). Этот механизм представляет собой надстройку над
системой обмена сообщениями ОС, поэтому в ряде случаев он позволяет более удобно и прозрачно организовать взаимодействие программ по сети, однако его полезность не универсальна.
Концепция удаленного вызова процедур
Идея вызова удаленных процедур состоит в расширении хорошо известного и понятного механизма передачи управления и данных внутри программы, выполняющейся на одной машине, на передачу управления и данных через сеть. Средства удаленного вызова процедур предназначены для облегчения организации распределенных вычислений. Впервые механизм RPC реализовала компания Sun Microsystems, и он хорошо соответствует девизу «Сеть — это компьютер», взятому этой компанией на вооружение, так как приближает сетевое программирование к локальному. Наибольшая эффективность RPC достигается в тех приложениях, в которых существует интерактивная связь между удаленными компонентами с небольшим временем ответов и относительно малым количеством передаваемых данных. Такие приложения называются RPC-ориентированными.
Характерными чертами вызова локальных процедур являются:
Реализация удаленных вызовов существенно сложнее реализации вызовов локальных процедур. Начнем с того, что поскольку вызывающая и вызываемая процедуры выполняются на разных машинах, то они имеют разные адресные пространства и это создает проблемы при передаче параметров и результатов, особенно если машины и их операционные системы не идентичны. Так как RPC не может рассчитывать на разделяемую память, это означает, что параметры RPC не должны содержать указателей на ячейки памяти и что значения параметров должны как-то копироваться с одного компьютера на другой.
Следующим отличием RPC от локального вызова является то, что он обязательно использует нижележащую систему обмена сообщениями, однако это не должно быть явно видно ни в определении процедур, ни в самих процедурах. Удаленность вносит дополнительные проблемы. Выполнение вызывающей программы и вызываемой локальной процедуры в одной машине реализуется в рамках единого процесса. Но в реализации RPC участвуют как минимум два процесса — по одному в каждой машине. В случае если один из них аварийно завершится, могут возникнуть следующие ситуации:
Кроме того, существует ряд проблем, связанных с неоднородностью языков программирования и операционных сред: структуры данных и структуры вызова процедур, поддерживаемые в каком-либо одном языке программирования, не поддерживаются точно таким же способом в других языках.
Рассмотрим, каким образом технология RPC, лежащая в основе многих распределенных операционных систем, решает эти проблемы.
Чтобы понять работу RPC, рассмотрим сначала выполнение вызова локальной процедуры в автономном компьютере. Пусть это, например, будет процедура записи данных в файл:
m.= my_write(fd,buf.length);
Здесь fd — дескриптор файла, целое число, buf — указатель на массив символов, length — длина массива, целое число.
Чтобы осуществить вызов, вызывающая процедура помещает указанные параметры в стек в обратном порядке и передает управление вызываемой процедуре my_wr1te. Эта пользовательская процедура после некоторых манипуляций с данными символьного массива buf выполняет системный вызов write для записи данных в файл, передавая ему параметры тем же способом, то есть помещая их в стек (при реализации системного вызова они копируются в стек системы, а при возврате из него результат помещается в пользовательский стек). После того как процедура my_write выполнена, она помещает возвращаемое значение m в регистр, перемещает адрес возврата и возвращает управление вызывающей процедуре, которая выбирает параметры из стека, возвращая его в исходное состояние. Заметим, что в языке С параметры могут вызываться по ссылке (by name), представляющей собой адрес глобальной области памяти, в которой хранится параметр, или по значению (by value), в этом случае параметр копируется из исходной области памяти в локальную память процедуры, располагаемую обычно в стековом сегменте. В первом случае вызываемая процедура работает с оригинальными значениями параметров и их изменения сразу же видны вызывающей процедуре. Во втором случае вызываемая процедура работает с копиями значений параметров, и их изменения никак не влияют на значение оригиналов этих переменных в вызывающей процедуре. Эти обстоятельства весьма существенны для RPC.
Решение о том, какой механизм передачи параметров использовать, принимается разработчиками языка. Иногда это зависит от типа передаваемых данных. В языке С, например, целые и другие скалярные данные всегда передаются по значению, а массивы — по ссылке.
Рисунок 9.6 иллюстрирует передачу параметров вызываемой процедуре: стек до выполнения вызова write (а), стек во время выполнения процедуры (б), стек после возврата в вызывающую программу (в).
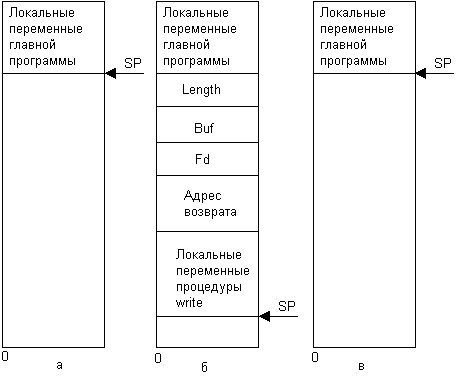
Рис. 9.6. Передача параметров вызываемой процедуре: а —состояние стека до выполнения процедуры, б —состояние стека во время выполнения процедуры и в — состояние стека после выполнения процедуры
Идея, положенная в основу RPC, состоит в том, чтобы вызов удаленной процедуры по возможности выглядел так же, как и вызов локальной процедуры. Другими словами, необходимо сделать механизм RPC прозрачным для программиста: вызывающей процедуре не требуется знать, что вызываемая процедура находится на другой машине, и наоборот.
Механизм RPC достигает прозрачности следующим образом. Когда вызываемая процедура действительно является удаленной, в библиотеку процедур вместо локальной реализации оригинального кода процедуры помещается другая версия процедуры, называемая клиентским стабом (stub — заглушка). На удаленный компьютер, который выполняет роль сервера процедур, помещается оригинальный код вызываемой процедуры, а также еще один стаб, называемый серверным стабом. Назначение клиентского и серверного стабов - организовать передачу параметров вызываемой процедуры и возврат значения процедуры через сеть, при этом код оригинальной процедуры, помещенной на сервер, должен быть полностью сохранен. Стабы используют для передачи данных через сеть средства подсистемы обмена сообщениями, то есть существующие в ОС примитивы send и receive. Иногда в подсистеме обмена сообщениями выделяется программный модуль, организующий связь стабов с примитивами передачи сообщений, называемый модулем RPCRimtime.
Подобно оригинальной процедуре, клиентский стаб вызывается путем обычной передачи параметров через стек (как показано на рис. 9.6), однако затем вместо выполнения системного вызова, работающего с локальным ресурсом, происходит формирование сообщения, содержащего имя вызываемой процедуры и ее параметры (рис. 9.7).
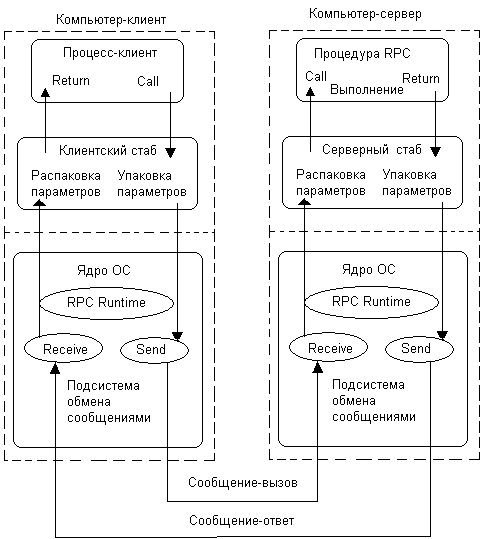
Рис. 9.7. Выполнение удаленного вызова процедуры
Эта операция называется операцией упаковки параметров. После этого клиентский стаб обращается к примитиву send для передачи этого сообщения удаленному компьютеру, на который помещена реализация оригинальной процедуры. Получив из сети сообщение, ядро ОС удаленного компьютера вызывает серверный стаб, который извлекает из сообщения параметры и вызывает обычным образом оригинальную процедуру. Для получения сообщения серверный стаб должен предварительно вызвать примитив receive, чтобы ядро знало, для кого пришло сообщение. Серверный стаб распаковывает параметры вызова, имеющиеся в сообщении, и обычным образом вызывает оригинальную процедуру, передавая ей параметры через стек. После окончания работы процедуры серверный стаб упаковывает результат ее работы в новое сообщение и с помощью примитива send ./' передает сообщение по сети клиентскому стабу, а тот возвращает обычным обра-' зом результат и управление вызывающей процедуре. Ни вызывающая процеду-' ра, ни оригинальная вызываемая процедура не изменились оттого, что они стали работать на разных компьютерах.
Стабы могут генерироваться либо вручную, либо автоматически. В первом случае программист использует для генерации ряд вспомогательных функций, которые ему предоставляет разработчик средств RPC. Программист при этом способе получает большую свободу в выборе способа передачи параметров вызова и применении тех или иных примитивов передачи сообщений, однако этот способ связан с большим объемом ручного труда.
Автоматический способ основан на применении специального языка определения интерфейса (Interface Definition Language, IDL). С помощью этого языка программист описывает интерфейс между клиентом и сервером RPC. Описание включает список имен процедур, выполнение которых клиент может запросить у сервера, а также список типов аргументов и результатов этих процедур. Информация, содержащаяся в описании интерфейса, достаточна для выполнения ста-бами проверки типов аргументов и генерации вызывающей последовательности. Кроме того, описание интерфейса содержит некоторую дополнительную информацию, полезную для оптимизации взаимодействия стабов, например каждый аргумент помечается как входной, выходной или играющий и ту, и другую роли (входной аргумент передается от клиента серверу, а выходной — в обратном направлении). Интерфейс может включать также описание общих для клиента и сервера констант. Необходимо подчеркнуть, что обычно интерфейс RPC включает не одну, а некоторый набор процедур, выполняющих взаимосвязанные функции, например функции доступа к файлам, функции удаленной печати и т. п. Поэтому при вызове удаленной процедуры обычно необходимо каким-то образом задать нужный интерфейс, а также конкретную процедуру, поддерживаемую этим интерфейсом. Часто интерфейс также называют сервером RPC, например файловый сервер, сервер печати.
После того как описание интерфейса составлено программистом, оно компилируется специальным IDL-компилятором, который вырабатывает исходные модули клиентских и серверных стабов для указанных в
описании процедур, а также генерирует специальные файлы-заголовки с описанием типов процедур и их аргументов. Генерации исходных модулей и файлов-заголовков стабов выполняются для конкретного языка, программирования, например для языка С. После этого исходные модули интерфейса могут включаться в любое приложение наряду с любыми другими модулями как написанными программистом, так и библиотечными, компилироваться и связываться в исполняемую программу стандартными средствами инструментальной системы программирования.
Механизм RPC оперирует двумя типами сообщений: сообщениями-вызовами, с помощью которых клиент запрашивает у сервера выполнение определенной удаленной процедуры и передает ее аргументы; сообщениями-ответами, с помощью которых сервер возвращает результат работы удаленной процедуры клиенту.
С помощью этих сообщений реализуется протокол RPC, определяющий способ взаимодействия клиента с сервером. Протокол RPC обычно не зависит от транспортных протоколов, с помощью которых сообщения RPC доставляются по сети от клиента к серверу и обратно. При использования в сети стека протоколов TCP/IP это могут быть протоколы TCP или UDP, в локальных сетях часто ис1 пользуется также NetBEUI/NetBIOS или IPX/SPX.
Типичный формат двух типов сообщений, используемых RPC, показан на рис. 9.8.
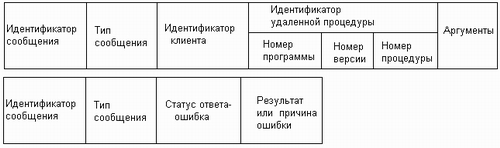
Рис. 9.8. Формат сообщений RPC
Тип сообщения позволяет отличить сообщения-вызовы от сообщений-ответов. Поле идентификатора удаленной процедуры в сообщении-вызове позволяет серверу понять, вызов какой процедуры запрашивает в сообщении клиент (процедуры идентифицируются не именами, а номерами, которые при автоматической генерации стабов присваивает им IDL-компилятор, а при ручной — программист). Поле аргументов имеет переменную длину, определяемую количеством и типом аргументов вызываемой процедуры. В поле идентификатора сообщения помещается порядковый номер сообщения, который полезен для обнаружения фактов потерь сообщений или прихода дубликатов сообщений. Кроме того, этот номер позволяет клиенту правильно сопоставить полученный от сервера ответ со своим вызовом в том случае, когда ответы приходят не в том порядке, в котором посылались вызовы. Идентификатор клиента нужен серверу для того, чтобы знать, какому клиенту нужно отправить результат работы вызываемой процедуры. Это поле может также использоваться в процедурах аутентификации клиента, если эти процедуры предусмотрены протоколом RPC.
Поле статуса и результата в сообщениях-ответах позволяют серверу сообщить клиенту об успешном выполнении удаленной процедуры или же о том, что при попытке выполнения процедуры была зафиксирована ошибка определенного типа. Сервер может столкнуться с различными ситуациями, препятствующими нормальному выполнению процедуры. Такие ситуации могут возникнуть еще до выполнения, так как клиенту может быть не разрешено выполнять данную процедуру, клиент может неправильно сформировать аргументы процедуры, клиентом могут использоваться версии интерфейса, не удовлетворяющие сервер, и т. п. Выполнение процедуры также может привести к ошибке, например связанной с делением на ноль. Все эти ситуации должны корректно обрабатываться стабом клиента и соответствующие коды ошибок должны передаваться в вызывающую процедуру.
Для устойчивой работы серверов и клиентов RPC необходимо каким-то образом обрабатывать ситуации, связанные с потерями сообщений, которые происходят
из-за ошибок сети (эти ошибки транспортные протоколы пытаются компенсировать, но все равно некоторая вероятность потерь все же остается) или же по причине краха операционной системы и перезагрузки компьютера (здесь транспортные протоколы исправить ситуацию не могут). Протокол RPC использует в таких случаях механизм тайм-аутов с повторной передачей сообщений. Для того чтобы сервер мог повторно переслать клиенту потерянный результат без необходимости передачи от клиента повторного вызова, в протокол RPC иногда добавляется специальное сообщение — подтверждение клиента, которое тот посылает при получении ответа от сервера.
Рассмотрим вопрос о том, как клиент узнает место расположения сервера, которому необходимо послать сообщение-вызов. Процедура, устанавливающая соответствие между клиентом и сервером RPC, носит название связывание (binding). Методы связывания, применяемые в различных реализациях RPC, отличаются:
Метод связывания тесно связан с принятым методом именования сервера. В наиболее простом случае имя или адрес сервера RPC задается в явной форме, в качестве аргумента клиентского стаба или программы-сервера, реализующей интерфейс определенного типа. Например, можно использовать в качестве такого аргумента IP-адрес компьютера, на котором работает некоторый RPC-сервер, и номер TCP/UDP порта, через который он принимает сообщения-вызовы своих процедур. Основной недостаток такого подхода — отсутствие гибкости и прозрачности. При перемещении сервера или при существовании нескольких серверов клиентская программа не может автоматически выбрать новый сервер или тот сервер, который в данный момент наименее загружен. Тем не менее во многих случаях такой способ вполне приемлем и ввиду своей простоты часто используется на практике. Необходимый сервер часто выбирает пользователь, например путем просмотра списка или графического представления имеющихся в сети разделяемых файловых систем (набор этих файловых систем может быть собран операционной системой клиентского компьютера за счет прослушивания широковещательных объявлений, которые периодически делают серверы). Кроме того, пользователь может задать имя требуемого сервера на основании заранее известной ему информации об адресе или имени сервера.
Подобный метод связывания можно назвать полностью статическим. Существуют и другие методы, которые являются в той или иной степени динамическими, так как не требуют от клиента точного задания адреса RPC-сервера, вплоть до указания номера порта, а динамически находят нужный клиенту сервер.
Динамическое связывание требует изменения способа именования сервера. Наиболее гибким является использование для этой цели имени RPC-интерфейса, состоящего из двух частей:
Тип интерфейса определяет все характеристики интерфейса, кроме его месторасположения. Это те же характеристики, который имеются в описании для IDL-компилятора, например файловая служба определенной версии, включающая процедуры open, close, read, write, и т. п. Часть, описывающая экземпляр интерфейса, должна точно задавать сетевой адрес сервера, который поддерживает данный интерфейс. Если клиенту безразлично, какой сервер его будет обслуживать, то вторая часть имени интерфейса опускается.
Динамическое связывание иногда называют импортом/экспортом интерфейса: клиент импортирует интерфейс, а сервер его экспортирует.
В том случае, когда для клиента важен только тип интерфейса, процесс обнаружения требуемого сервера в сети с экземпляром интерфейса определенного типа может быть построен двумя способами:
Эти два способа характерны для поиска сетевого ресурса любого типа по его имени, они уже рассматривались в общем виде в подразделе «Способы адресации» раздела «Механизм передачи сообщений в распределенных системах». Первый способ основан на широковещательном распространении по сети серверами RPC имени своего интерфейса, включая и адрес экземпляра. Применение этого способа позволяет автоматически балансировать нагрузку на несколько серверов, поддерживающий один и тот же интерфейс, — клиент просто выбирает первое из подходящих ему объявлений.
Схема с централизованным агентом связывания предполагает наличие в сети сервера имен, который связывает тип интерфейса с адресом сервера, поддерживающего такой интерфейс. Для реализации этой схемы каждый сервер RPC должен предварительно зарегистрировать тип своего интерфейса и сетевой адрес у агента связывания, работающего на сервере имен. Сетевой адрес агента связывания (в формате, принятом в данной сети) должен быть известным адресом как для серверов RPC, так и для клиентов. Если сервер по каким-то причинам не может больше поддерживать определенный RFC-интерфейс, то он должен обратиться к агенту и отменить свою регистрацию. Агент связывания на основании запросов регистрации ведет таблицу текущего наличия в сети серверов и поддерживаемых ими RFC-интерфейсов.
Клиент RFC для определения адреса сервера, обслуживающего требуемый интерфейс, обращается к агенту связывания с указанием характеристик, задающих тип интерфейса. Если в таблице агента связывания имеются сведения о сервере, поддерживающем такой тип интерфейса, то он возвращает клиенту его сетевой адрес. Клиент затем кэширует эту информацию для того, чтобы при последующих обращениях к процедурам данного интерфейса не тратить время на обращения к агенту связывания.
Агент связывания может работать в составе общей централизованной справочной службы сети, такой как NDS, X.500 или LDAP (справочные службы более подробно рассматриваются в следующей главе).
Описанный метод, заключающийся в импорте/экспорте интерфейсов, обладает высокой гибкостью. Например, может быть несколько серверов, поддерживающих один и тот же интерфейс, и клиенты распределяются по серверам случайным образом. В рамках этого метода становится возможным периодический опрос серверов, анализ их работоспособности и, в случае отказа, автоматическое отключение, что повышает общую отказоустойчивость системы. Этот метод может также поддерживать аутентификацию клиента. Например, сервер может определить, что доступ к нему разрешается только клиентам из определенного списка.
Однако у динамического связывания имеются недостатки, например дополнительные накладные расходы (временные затраты) на экспорт и импорт интерфейсов. Величина этих затрат может быть значительна, так как многие клиентские процессы существуют короткое время, а при каждом старте процесса процедура импорта интерфейса должна выполняться заново. Кроме того, в больших распределенных системах может стать узким местом агент связывания, и тогда необходимо использовать распределенную систему агентов, что можно сделать стандартным способом, используя распределенную справочную службу (таким свойством обладают службы NDS, X.500 и LDAP).
Необходимо отметить, что и в тех случаях, когда используется статическое связывание, такая часть адреса, как порт сервера интерфейса (то есть идентификатор процесса, обслуживающего данный интерфейс), определяется клиентом динамически. Эту процедуру поддерживает специальный модуль RPCRuntime, называемый в ОС UNIX модулем отображения портов (portmapper), а в ОС семейства Windows — локатором RFC (RPC Locator). Этот модуль работает на каждом сетевом узле, поддерживающем механизм RPC, и доступен по хорошо известному порту TCP/UDP. Каждый сервер RPC, обслуживающий определенный интерфейс, при старте обращается к такому модулю с запросом о выделении ему для работы номера порта из динамически распределяемой области (то есть с номером, большим 1023). Модуль отображения портов выделяет серверу некоторый свободный номер порта и запоминает это отображение в своей таблице, связывая порт с типом интерфейса, поддерживаемым сервером. Клиент RPC, выяснив каким-либо образом сетевой адрес узла, на котором имеется сервер RPC с нужным интерфейсом, предварительно соединяется с модулем отображения портов по хорошо известному порту и запрашивает номер порта искомого сервера. Получив ответ, клиент использует данный номер для отправки сообщений- J вызовов удаленных процедур. Механизм очень похож на механизм, лежащий в основе работы агента связывания, но только область его действия ограничивается портом одного компьютера.
Особенности реализации RPC на примере систем Sun RPC и DCE RPC
Рассмотрим особенности реализации RPC на примере двух широко распространенных систем удаленного вызова процедур: Sun RPC и DCE RPC. Система Sun RPC является продуктом компании Sun Microsystems и работает во всех сетевых операционных системах этой компании — SunOS, Solaris, а система DCE RPC — это стандарт консорциума Open Software Foundation для распределенной вычислительной среды Distributed Computing Environment (DCE). Реализации DCE RPC доступны сегодня для многих сетевых ОС, кроме того, на основе стандарта DCE RPC разработана система Microsoft RPC, применяющаяся в популярных ОС семейства Windows. К сожалению, реализации Sun RPC и DCE RPC несовместимы друг с другом, более того, нет гарантий, что различные реализации RPC, в основе которых лежит стандарт DCE RPC, смогут совместно работать в гетерогенной сети, так как стандарт DCE определяет только базовые свойства механизма удаленного вызова процедур, а каждая реализация добавляет к стандарту большое количество собственных дополнительных функций.
Sun RPC
Система Sun RPC позволяет автоматически генерировать клиентский и серверный стабы в том случае, если интерфейс RPC описан на языке IDL, называемом RPC Language (RPCL). Язык RPCL является расширением языка Sun XDR (external Data Representation), который был разработан для системно-независимого представления внешних данных в гетерогенной среде. XDR-представление данных по умолчанию используется в Sun RPC при передаче аргументов и результатов между клиентом и сервером RPC.
Механизм Sun RPC обладает некоторыми достаточно жесткими ограничениями. Одним из них является ограничение на аргументы и результаты удаленных процедур — процедура может иметь только один аргумент и вырабатывать только один результат. Для преодоления этого ограничения в качестве аргумента и результата обычно используется структура данных.
Следующий пример описания интерфейса файловой службы иллюстрирует эту особенность:
/* Определение интерфейса для файловой службы с именем FILE_SERVICE_2. включающей процедуры чтения READ и записи WRITE */
const FILEJAMEJIZE =16
const BUFFER.SIZE = 1024
typedef string FileName<FILE_NAME_SIZE>
typedef long Position:
typedef long Mbytes:
struct Data {
long n;
char buffer[BUFFER SIZE]:
}:
struct readargs {
FileName filename;
Position position:
Nbytes n:
}:
struct writeargs {
FileNarae filename;
Position position:
Data data;
}:
program FILE_SERVICE_2 {
version FILE_SERVICE_VERS {
Data READ (readargs) = 1;
Nbytes WRITE (writeargs) = 2;
}=l:
} = 0x20000000:
Интерфейс однозначно идентифицируется номером программы (FILE_SERVICE_2 -- 0x20000000) и номером версии (FILE_SERVICE_VERS = 1), а процедуры внутри интерфейса — номерами процедур, READ — номером 1 и WRITE — номером 2.
Структура readargs позволяет передать процедуре READ три аргумента — имя файла, позицию (смещение) в файле, с которой нужно начать чтение данных, и количество считываемых байт. Структура Data позволяет вызывающей процедуре получить результат чтения в массиве buffer и узнать количество реально считанных байт с помощью переменной п. Аналогично используются структуры writeargs и Data в процедуре записи WRITE.
Результатом обработки описания интерфейса FILE_SERVICE_2 RPCL-компилято-ром являются несколько файлов, в том числе файл, описывающий клиентские стабы, а также файл, описывающий серверные стабы. По умолчанию имена стабов процедур образуются путем преобразования имен процедур, указанных в описании интерфейса, в нижний регистр, а также добавлением после нижнего подчеркивания номера версии интерфейса, то есть стабы в нашем примере будут иметь имена read_l и write_l.
Механизм Sun RPC не поддерживает динамического связывания с сервером с помощью агента связывания. Клиент должен явно указывать сетевой адрес сервера, а для получения номера порта он должен обратиться к модулю отображения портов, работающему на узле сервера. Для взаимодействия с этим модулем система Sun RPC предоставляет в распоряжение клиента системный вызов сlnt_create, имеющий следующий синтаксис:
client_handle = clnt_create(server_host_name. interfacejiame, interface_version, protocol)
Аргумент server_host_name представляет собой имя (символьное DNS-имя или IP-адрес узла, на котором работает сервер RPC), аргументы interface_name и interface_version задают номер и версию интерфейса, а аргумент protocol указывает на один из двух транспортных протоколов стека TCP/IP — TCP или UDP. Жесткая ориентация только на один стек коммуникационных протоколов, а именно стек TCP/IP, — еще одно ограничение Sun RPC. У компании Sun существует также и протокольно-независимая версия системы удаленного вызова процедур — TI-RPC (Transport-Independent RPC), но она менее распространена.
Вызов clnt_create возвращает указатель, который необходимо далее использовать вместо адреса RFC-сервера при последовательных обращениях к удаленным процедурам, обслуживаемым данным сервером. В процессе своего выполнения cl nt_create создает сокет, который связывает с адресом сервера, включающим и неявно полученный от модуля отображения портов (службы portmapper) номер порта. В конце сеанса работы с сервером необходимо выполнить системный вызов clnt_destroy, который закрывает созданный сокет.
Еще одним ограничением Sun RPC является максимальный размер сообщения в 8 Кбайт при использовании протокола UDP (применение протокола TCP не накладывает таких ограничений в силу особенности его интерфейса с вышележащими протоколами, который позволяет передавать непрерывный поток байт в течение периода существования TCP-соединения).
DCE RPC
Служба DCE RPC обладает рядом функциональных преимуществ по сравнению с Sun RPC. Она поддерживает динамическое связывание клиентов и серверов, для чего используется справочная служба среды DCE — служба Cell Directory Service (CDS). Каждый сервер RPC при старте регистрирует свой сетевой адрес и уникальный идентификатор интерфейса на сервере CDS. Кроме того, на каждом узле, поддерживающем RPC, работает процесс rpcd, который выполняет функции по отображению сервера RPC на подходящий локальный адрес процесса (например, порт TCP/UDP, если сервер работает на компьютере, поддерживающем стек TCP/IP). Служба DCE RPC является транспортно-независимой, что позволяет ей работать на разных платформах и в различных сетях.
При описании интерфейса используется язык IDL. Процедуры DCE RPC могут иметь произвольное число аргументов, которые описываются как входные, выходные или входные- выходные.
Распределенные приложения обладают рядом потенциальных преимуществ по сравнению с локальными, такими как более высокая производительность, отказоустойчивость, масштабируемость и приближение к пользователю.
- способ адресации;
- наличие синхронизации;
- способ буферизации;
- степень надежности доставки.
1. Приведите пример сетевого приложения. Каким образом в этом приложении могут быть распределены функции между клиентской и серверной частями? Каким могло бы быть распределение функций, если бы приложение имело трехзвенную структуру?
2. Чем отличается взаимодействие процессов в рамках одного компьютера от их взаимодействия по сети?
3. В каком случае работа с удаленной базой данных порождает более интенсивный трафик: при использовании модели файлового сервера или сервера базы данных?
4. В каком случае прикладному программисту проще писать программу: с использованием синхронных или асинхронных примитивов передачи сообщений?
5. Какая структура операционной системы соответствует понятию «порт», используемому в протоколах TCP/UDP?
6. В каких случаях целесообразно использовать ненадежные примитивы передачи сообщений?
7. Используя интерфейс сокетов, опишите взаимодействие двух процессов, один из которых является сервером, а другой — клиентом файловой службы.
8. В чем состоит основное назначение механизма RPC?
9. Почему в процедурах RPC не используются глобальные переменные?
10. Почему в системных вызовах RPC аргументы передаются по значению (by value), а не по адресу (by name)?
11. Опишите процедуру автоматической генерации стабов.