ГЛАВА 7
Ввод-вывод и файловая система
Одной из главных задач ОС является обеспечение обмена данными между приложениями и периферийными устройствами компьютера. Собственно ради выполнения этой задачи и были разработаны первые системные программы, послужившие прототипами операционных систем. В современной ОС функции обмена данными с периферийными устройствами выполняет подсистема ввода-вывода. Клиентами этой подсистемы являются не только пользователи и приложения, но и некоторые компоненты самой ОС, которым требуется получение системных данных или их вывод, например подсистеме управления процессами при смене активного процесса необходимо записать на диск контекст приостанавливаемого процесса и считать с диска контекст активизируемого процесса.
Основными компонентами подсистемы ввода-вывода являются драйверы, управляющие внешними устройствами, и файловая система. К подсистеме ввода-вывода можно также с некоторой долей условности отнести и диспетчер прерываний, рассмотренный выше. Условность заключается в том* что диспетчер прерываний обслуживает не только модули подсистемы ввода-вывода, но и другие модули ОС, в частности такой важный модуль, как планировщик/диспетчер потоков. Но из-за того, что планирование работ подсистемы ввода-вывода составляет основную долю нагрузки диспетчера прерываний, его вполне логично рассматривать как ее составную часть (к тому же первопричиной появления в компьютерах системы прерываний были в свое время именно операции с устройствами ввода-вывода).
Файловая система ввиду ее сложности, специфичности и важности как основного хранилища всей информации вычислительной системы заслуживает рассмотрения в отдельной главе. Тем не менее,
здесь файловая система рассматривается совместно с другими компонентами подсистемы ввода-вывода по двум причинам. Во-первых, файловая система активно использует остальные части подсистемы ввода-вывода, а во-вторых, модель файла лежит в основе большинства механизмов доступа к устройствам, используемых в современной подсистеме ввода-вывода.
Задачи ОС по управлению файлами и устройствами
Подсистема ввода-вывода (Input-Output Subsystem) мультипрограммной ОС при обмене данными с внешними устройствами компьютера должна решать ряд общих задач, из которых наиболее важными являются следующие:
В следующих разделах все эти задачи рассматриваются подробно.
Организация параллельной работы устройств ввода-вывода и процессора
Каждое устройство ввода-вывода вычислительной системы — диск, принтер, терминал и т. п. — снабжено специализированным блоком управления, называемым контроллером. Контроллер взаимодействует с драйвером — системным программным модулем, предназначенным для управления данным устройством. Контроллер периодически принимает от драйвера выводимую на устройство информацию, а также команды управления, которые говорят о том, что с этой информацией нужно сделать (например, вывести в виде текста в определенную область терминала или записать в определенный сектор диска). Под управлением контроллера устройство может некоторое время выполнять свои операции автономно, не требуя внимания со стороны центрального процессора. Это время зависит от многих факторов — объема выводимой информации, степени интеллектуальности управляющего устройством контроллера, быстродействия устройства и т. п. Даже самый примитивный контроллер, выполняющий простые функции, обычно тратит довольно много времени на самостоятельную реализацию подобной функции после получения очередной команды от процессора. Это же справедливо и для сложных контроллеров, так как скорость работы любого устройства ввода-вывода, даже самого скоростного, обычно существенно ниже скорости работы процессора.
Процессы, происходящие в контроллерах, протекают в периоды между выдачами команд независимо от ОС. От подсистемы ввода-вывода требуется спланировать в реальном масштабе времени (в котором работают внешние устройства) запуск и приостановку большого количества разнообразных драйверов, обеспечив приемлемое время реакции каждого драйвера на независимые события контроллера. С другой стороны, необходимо минимизировать загрузку процессора задачами ввода-вывода, оставив как можно больше процессорного времени на выполнение пользовательских потоков.
Данная задача является классической задачей планирования систем реального времени и обычно решается на основе многоуровневой приоритетной схемы обслуживания по прерываниям. Для обеспечения приемлемого уровня реакции все драйверы (или части драйверов) распределяются по нескольким приоритетным уровням в соответствии с требованиями ко времени реакции и временем использования процессора. Для реализации приоритетной схемы обычно задействуется общий диспетчер прерываний ОС.
Согласование скоростей обмена и кэширование данных
При обмене данными всегда возникает задача согласование скорости. Например, если один пользовательский процесс вырабатывает некоторые данные и передает их другому пользовательскому процессу через оперативную память, то в общем случае скорости генерации данных и их чтения не совпадают. Согласование скорости обычно достигается за счет буферизации данных в оперативной памяти и синхронизации доступа процессов к буферу.
В подсистеме ввода-вывода для согласования скоростей обмена также широко используется буферизация данных в оперативной памяти. В тех специализированных операционных системах, в которых обеспечение высокой скорости ввода-вывода является первоочередной задачей (управление в реальном времени, услуги сетевой файловой службы и т. п.), большая часть оперативной памяти отводится не под коды прикладных программ, а под буферизацию данных. Однако буферизация только на основе оперативной памяти в подсистеме ввода-вывода оказывается недостаточной — разница между скоростью обмена с оперативной памятью, куда процессы помещают данные для обработки, и скоростью работы внешнего устройства часто становится слишком значительной, чтобы в качестве временного буфера можно было бы использовать оперативную память — ее объема может просто не хватить. Для таких случаев необходимо предусмотреть особые меры, и часто в качестве буфера используется дисковый файл, называемый также спул-файлом (от spool — шпулька, тоже буфер, только для ниток). Типичный пример применения спулинга дает организация вывода данных на принтер. Для печатаемых документов объем в несколько десятков мегабайт — не редкость, поэтому для их временного хранения (а печать каждого документа занимает от нескольких минут до десятков минут) объема оперативной памяти явно недостаточно.
Другим решением этой проблемы является использование большой буферной памяти в контроллерах внешних устройств. Такой подход особенно полезен в тех случаях, когда помещение данных на диск слишком замедляет обмен (или когда данные выводятся на сам диск). Например, в контроллерах графических дисплеев применяется буферная память, соизмеримая по объему с оперативной, и это существенно ускоряет вывод графики на экран.
Буферизация данных позволяет не только согласовать скорости работы процессора и внешнего устройства, но и решить другую задачу — сократить количество реальных операций ввода-вывода за счет кэширования данных. Дисковый кэш является непременным атрибутом подсистем ввода-вывода практически всех операционных систем, значительно сокращая время доступа к хранимым данным.
Разделение устройств и данных между процессами
Устройства ввода-вывода могут предоставляться процессам как в монопольное, так и в совместное (разделяемое) использование. При этом ОС должна обеспечивать контроль доступа теми же способами, что и при доступе процессов к другим ресурсам вычислительной системы — путем проверки прав пользователя или группы пользователей, от имени которых действует процесс, на выполнение той или иной операции над устройством. Например, определенной группе пользователей последовательный порт разрешено захватывать в монопольное владение, а другим пользователям это запрещено.
Операционная система может контролировать доступ не только к устройству в целом, но -и к отдельным порциям данных, хранимых или отображаемых этим устройством. Диск является типичным примером устройства, для которого важно контролировать доступ не к устройству в целом, а к отдельным каталогам и файлам. При выводе информации на графический дисплей отдельные окна экрана также представляют собой ресурсы, к которым необходимо обеспечить тот или иной вид доступа для протекающих в системе процессов. При этом для каждой порции данных или части устройства могут быть заданы свои права доступа, не связанные прямо с правами доступа к устройству в целом. Так, в файловой системе обычно для каждого каталога и файла можно задать индивидуальные права доступа. Очевидно, что для организации совместного доступа к частям устройства или частям данных, хранящихся на нем, непременным условием является задание режима совместного использования устройства в целом.
Одно и то же устройство в разные периоды времени может использоваться как в разделяемом, так и в монопольном режимах. Тем не менее существуют устройства, для которых обычно характерен один из этих режимов, например последовательные порты и алфавитно-цифровые терминалы чаще используются в монопольном режиме, а диски — в режиме совместного доступа. Операционная система должна предоставлять эти устройства в обоих режимах, осуществляя отслеживание процедур захвата и освобождения монопольно используемых устройств, а в случае совместного использования оптимизируя последовательность операций ввода-вывода для различных процессов в целях повышения общей производительности, если это возможно. Например, при обмене данными нескольких процессов с диском можно так упорядочить последовательность операций, что непроизводительные затраты времени на перемещение головок существенно уменьшаются (при этом для отдельных процессов возможно некоторое замедление операции ввода-вывода).
При разделении устройства между процессами может возникнуть необходимость в разграничении порции данных двух процессов друг от друга. Обычно такая потребность возникает при совместном использовании так называемых последовательных устройств, данные в которых в отличие от устройств прямого доступа не адресуются. Типичным представителем такого рода устройства является принтер, который не выделяется в монопольное владение процессам, и в то же время каждый документ должен быть напечатан в виде последовательного набора страниц. Для подобных устройств организуется очередь заданий на вывод, при этом каждое задание представляет собой порцию данных, которую нельзя разрывать, например документ для печати. Для хранения очереди заданий используется спул-файл, который одновременно согласует скорости работы принтера и оперативной памяти и позволяет организовать разбиение данных на логические порции. Так как спул-файл находится на разделяемом устройстве прямого доступа, то процессы могут одновременно выполнять вывод на принтер, помещая данные в свой раздел спул-файла.
Обеспечение удобного логического интерфейса между устройствами и остальной частью системы
Разнообразие устройств ввода-вывода делают особенно актуальной функцию ОС по созданию экранирующего логического интерфейса между периферийными устройствами и приложениями. Практически все современные операционные системы поддерживают в качестве основы такого интерфейса файловую модель периферийных устройств, когда любое устройство выглядит для прикладного программиста последовательным набором байт, с которым можно работать с помощью унифицированных системных вызовов (например, read и write), задавая имя файла-устройства и смещение от начала последовательности байт. Для поддержания такого интерфейса подсистема ввода-вывода должна проделать немалую работу, учитывая разницу в организации операций обмена данными, например, с жестким диском и графическим терминалом.
Привлекательность модели файла-устройства состоит в ее простоте и унифицированности для устройств любого типа, однако во многих случаях для программирования операций ввода-вывода некоторого устройства она является слишком бедной. Поэтому данная модель часто используется только в качестве базиса, над которым подсистема ввода-вывода строит более содержательную модель устройств конкретного типа. Подсистема ввода-вывода предоставляет, как правило, специфический интерфейс для вывода графической информации на дисплей или принтер, для программирования операций сетевого обмена и т. п. При этом разработчик специфического интерфейса всегда может опираться на имеющийся базовый интерфейс.
Поддержка широкого спектра драйверов и простота включения нового драйвера в систему
Достоинством подсистемы ввода-вывода любой универсальной ОС является наличие разнообразного набора драйверов для наиболее популярных периферийных устройств. Прекрасно спланированная и реализованная операционная система может потерпеть неудачу на рынке только из-за того, что в ее состав не включен достаточный набор драйверов и администраторы и пользователи вынуждены искать нужный им драйвер для имеющегося у них внешнего устройства у производителей оборудования или, что еще хуже, заниматься его разработкой. Именно в такой ситуации оказались пользователи первых версий OS/2, и, возможно, это обстоятельство послужило в свое время не последней причиной сдачи позиций этой неплохой операционной системы, богатой на драйверы ОС Windows 3.x.
Чтобы операционная система не испытывала недостатка в драйверах, необходимо наличие четкого, удобного и открытого интерфейса между драйверами и другими компонентами ОС. Такой интерфейс нужен для того, чтобы драйверы писали не только непосредственные разработчики данной операционной системы, но и большая армия программистов по всему миру, в первую очередь — тех предприятий, которые выпускают внешние устройства для компьютеров. Открытость интерфейса драйверов, то есть доступность его описания для независимых разработчиков программного обеспечения (а возможно, также и разработка его на основе согласительных процедур между ведущими коллективами разработчиков), является необходимым условием успешного развития операционной системы.
Драйвер взаимодействует, с одной стороны, с модулями ядра ОС (модулями подсистемы ввода-вывода, модулями системных вызовов, модулями подсистем управления процессами и памятью и т. д.), а с другой стороны — с контроллерами внешних устройств. Поэтому существуют два типа интерфейсов: интерфейс «драйвер-ядро» (Driver Kernel Interface, DKI) и интерфейс «драйвер-устройство» {Driver Device Interface, DDF). Интерфейс «драйвер-ядро» должен быть стандартизован в любом случае, а интерфейс «драйвер-устройство» имеет смысл стандартизировать тогда, когда подсистема ввода-вывода не разрешает драйверу непосредственно взаимодействовать с аппаратурой контроллера, а выполняет эти операции самостоятельно. Экранирование драйвера от аппаратуры является весьма полезной функцией, так как драйвер в этом случае становится независимым от аппаратной платформы. Подсистема ввода-вывода может поддерживать несколько различных типов интерфейсов DKI/DDI, предоставляя специфический интерфейс для устройств определенного класса. Так, в ОС Windows NT для драйверов сетевых адаптеров существует интерфейс стандарта NDIS (Network Driver Interface Specification), в то время как драйверы сетевых транспортных протоколов взаимодействуют с верхними слоями сетевого программного обеспечения по интерфейсу TDI (Transport Driver Interface).
Обычно подсистема ввода-вывода поддерживает большое количество системных функций, которые драйвер может вызывать для выполнения некоторых типовых действий. Примерами могут служить упомянутые операции обмена с регистрами контроллера, ведение буферов для промежуточного хранения данных ввода-вывода, синхронизация работы нескольких драйверов, копирование данных из пользовательского пространства в пространство системы и т. д.
Для поддержки процесса разработки драйверов операционной системы обычно выпускается так называемый пакет DDK
(Driver Development Kit), представляющий собой набор соответствующих инструментальных средств — библиотек, компиляторов и отладчиков.
Динамическая загрузка и выгрузка драйверов
Кроме проблемы разработки новых драйверов существует также проблема включения драйвера в состав модулей работающей ОС, то есть динамической загрузки-выгрузки драйвера. Так как набор потенциально поддерживаемых данной ОС периферийных устройств всегда существенно шире набора устройств, которыми ОС должна управлять при установке на конкретной машине, то ценным свойством ОС является возможность динамически загружать в оперативную память требуемый драйвер (без останова ОС) и выгружать его после того, как потребность в поддержке устройства миновала, что может существенно сэкономить системную область памяти.
Альтернативой динамической загрузке драйверов при изменении текущей конфигурации внешних устройств компьютера является повторная компиляция кода ядра с требуемым набором драйверов, что создает между всеми компонентами ядра статические связи вместо динамических. Например, таким образом решалась данная проблема в ранних версиях операционной системы UNIX. При статических связях между ядром и драйверами структура ОС упрощается, но этот подход требует наличия исходных кодов модулей операционной системы, доступность которых скорее является исключением (для некоммерческих версий UNIX), а не правилом. Кроме того, в этом варианте работающую предыдущую версию операционной системы необходимо остановить и заменить новой, а перерывы в работе ОС в некоторых применениях могут и не допускаться.
Поддержка динамической загрузки драйверов является практически обязательным требованием для современных универсальных операционных систем.
Поддержка нескольких файловых систем
Диски представляют особый род периферийных устройств, так как именно на них хранится большая часть как пользовательских, так и системных данных. Данные на дисках организуются в файловые системы, и свойства файловой системы во многом определяют свойства самой ОС — ее отказоустойчивость, быстродействие, максимальный объем хранимых данных. Популярность файловой системы часто приводит к ее миграции из «родной» ОС в другие операционные системы — например, файловая система FAT появилась первоначально в MS-DOS, но затем была реализована в OS/2, семействе MS Windows и многих реализациях UNIX. Ввиду этого поддержка нескольких популярных файловых систем для подсистемы ввода-вывода также важна, как и поддержка широкого спектра периферийных устройств. Важно также, чтобы архитектура подсистемы ввода-вывода позволяла достаточно просто включать в ее состав новые типы файловых систем, без необходимости переписывания кода. Обычно в операционной системе имеется специальный слой программного обеспечения, отвечающий за решение данной задачи, например слой VFS ( Virtual File System) в версиях UNIX на основе кода System V Release 4.
Поддержка синхронных и асинхронных операций ввода-вывода
Операция ввода-вывода может выполняться по отношению к программному модулю, запросившему операцию, в синхронном или асинхронном режимах. Смысл этих режимов тот же, что и для рассмотренных выше системных вызовов, — синхронный режим означает, что программный модуль приостанавливает свою работу до тех пор, пока операция ввода-вывода не будет завершена (рис. 7.1, а), а при асинхронном режиме программный модуль продолжает выполняться в мультипрограммном режиме одновременно с операцией ввода-вывода (рис. 7Л, б). Отличие же заключается в том, что операция ввода-вывода может быть инициирована не только пользовательским процессом — в этом случае операция выполняется в рамках системного вызова, но и кодом ядра, например кодом подсистемы виртуальной памяти для считывания отсутствующей в памяти страницы.
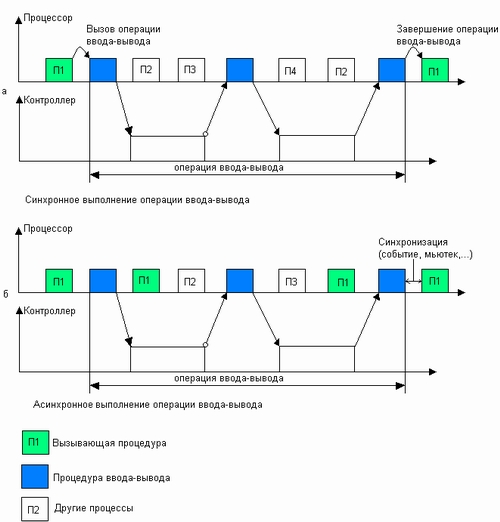
Рис. 7.1. Два режима выполнения операций ввода-вывода
Подсистема ввода-вывода должна предоставлять своим клиентам (пользовательским процессам и кодам ядра) возможность выполнять как синхронные, так и асинхронные операции ввода-вывода, в зависимости от потребностей вызывающей стороны. Системные вызовы ввода-вывода чаще оформляются как синхронные процедуры в связи с тем, что такие операции длятся долго и пользовательскому процессу или потоку все равно придется ждать получения результатов операции для того, чтобы продолжить свою работу. Внутренние же вызовы операций ввода-вывода из модулей ядра обычно выполняются в виде асинхронных процедур, так как кодам ядра нужна свобода в выборе дальнейшего поведения после запроса операции ввода-вывода. Использование асинхронных процедур приводит к более гибким решениям, так как на основе асинхронного вызова всегда можно построить синхронный, создав дополнительную промежуточную процедуру, блокирующую выполнение вызвавшей процедуры до момента завершения ввода-вывода. Иногда и прикладному процессу требуется выполнить асинхронную операцию ввода-вывода, например при микроядерной архитектуре, когда часть кода работает в пользовательском режиме как прикладной процесс, но выполняет функции операционной системы, требующие полной свободы действий и после вызова операции ввода-вывода.
Многослойная модель подсистемы ввода-
вывода
Многослойное построение программного обеспечения, характерное для операционных систем вообще, оказывается особенно естественным и полезным при построении подсистемы ввода-вывода. При большом разнообразии устройств ввода-вывода, обладающих существенно различными характеристиками (принтер и диски, графический монитор и сетевой адаптер и т. п.), иерархическая структура программного обеспечения позволяет соблюсти баланс между двумя весьма противоречивыми требованиями: с одной стороны, необходимо учесть все особенности каждого устройства, а с другой стороны, обеспечить единое логическое представление и унифицированный интерфейс для устройств всех типов. При этом нижние слои подсистемы ввода-вывода должны включать индивидуальные драйверы, написанные для конкретных физических устройств, а верхние слои должны обобщать процедуры управления этими устройствами, предоставляя общий интерфейс если не для всех устройств, то по крайней мере для групп устройств, обладающих некоторыми общими характеристиками, например для принтеров определенного производителя или для всех матричных принтеров и т. п.
Многослойность структуры, безусловно, облегчает решение большинства перечисленных в предыдущем разделе задач подсистемы ввода-вывода, таких как простота включения новых драйверов, поддержка нескольких файловых систем, динамическая загрузка-выгрузка драйверов и других.
Обобщенная структура подсистемы ввода-вывода представлена на рис. 7.2.
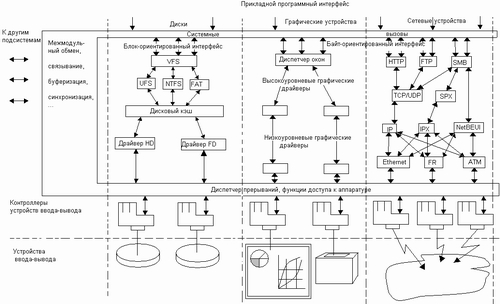
Рис.7.2. Структура подсистемы ввода-вывода
Из рисунка видно, что программное обеспечение ввода-вывода делится не только на горизонтальные слои, но и на вертикальные. Это объясняется тем, что для такого разнообразного мира, как внешние устройства, трудно обеспечить единообразие в разбиении функций управления на слои. Поэтому общий принцип многослойности остается справедливым, однако для устройств определенного типа он реализуется по-разному, со своим количеством слоев и их функциями. В представленной структуре в качестве примера приведены три вертикальные подсистемы, управляющие дисками, графическими устройствами, такими как мониторы, принтеры и плоттеры, и сетевыми адаптерами. Естественно, к этому перечню можно добавить и другие, например подсистему управления символьными терминалами или какими-либо специализированными устройствами, такими как аналого-цифровые и цифро-аналоговые преобразователи.
В каждой вертикальной подсистеме существует несколько слоев модулей. Нижний слой образуют так называемые аппаратные драйверы устройств, название которых отражает тот факт, что они управляют аппаратурой внешних устройств, осуществляя обмен байтами и блоками байтов, и не имеют, как правило, дела с более высокоуровневыми вопросами логической организации данных, например с файлами или сложными графическими объектами. Функции вышележащих слоев в значительной степени зависят от типа вертикальной подсистемы.
В подсистеме ввода-вывода наряду с модулями, отражающими специфику внешних устройств и образующими вертикальные подсистемы, существуют модули универсального назначения. Эти модули организуют согласованную работу всех остальных компонентов подсистемы ввода-вывода и взаимодействие с пользовательскими процессами и другими подсистемами ОС. Так же как и функции управления устройствами, эти организующие функции распределены по всем уровням, образуя оболочку. Эта оболочка иногда называется менеджером ввода-вывода. Задачи такого менеджера довольно разнообразны.
Верхний слой менеджера составляют системные вызовы ввода-вывода, которые принимают от пользовательских процессов запросы на ввод-вывод и переадресуют их отвечающим за определенный класс устройств модулям и драйверам, а также возвращают процессам результаты операций ввода-вывода. Таким образом этот слой поддерживает пользовательский интерфейс ввода-вывода, создавая для прикладных программистов максимум удобств по манипулированию внешними устройствами и расположенными на них данными.
Нижний слой менеджера реализует непосредственное взаимодействие с контроллерами внешних устройств, экранируя драйверы от особенностей аппаратной платформы компьютера — шины ввода-вывода, системы прерываний и т. п. Этот слой принимает от драйверов запросы на обмен данными с регистрами контроллеров в некоторой обобщенной форме с использованием независимых от шины ввода-вывода адресации и формата, а затем преобразует эти запросы в зависящий от аппаратной платформы формат. Диспетчер прерываний, рассмотренный выше, может входить в состав менеджера ввода-вывода или же представлять собой отдельный модуль ядра. В последнем случае менеджер ввода-вывода выполняет для диспетчера прерываний первичную обработку запросов прерываний, передавая диспетчеру обобщенные сведения об источнике запроса.
Важной функцией менеджера ввода-вывода является создание некоторой среды для остальных компонентов подсистемы, которая бы облегчала их взаимодействие друг с другом. Эта задача может быть решена за счет создания некоторого стандартного внутреннего интерфейса взаимодействия модулей ввода-вывода между собой, который бы дополнял внешние интерфейсы подсистемы с прикладными процессами, другими модулями ядра и аппаратурой. Наличие такого интерфейса существенно облегчает включение новых драйверов и файловых систем в состав ОС. Кроме того, разработчики драйверов и других программных компонентов освобождаются от написания общих процедур, таких как буферизация данных и синхронизация нескольких модулей между собой при обмене данными. Все эти функции берет на себя менеджер ввода-вывода.
Еще одной функцией менеджера ввода-вывода является организация взаимодействия модулей ввода-вывода с модулями других подсистем ОС, таких как подсистема управления процессами, виртуальной памятью и другими.
Примерами подобного менеджера являются менеджер ввода-вывода ОС Windows NT, а также среда STREAMS, существующая во многих версиях операционной системы UNIX. Менеджер ввода-вывода Windows NT организует взаимодействие между модулями с помощью пакетов запросов ввода-вывода — IRP (I/O Request Packet). Получив запрос от процедуры системного вызова, менеджер формирует IRP и передает его нужному драйверу. Драйвер после выполнения запрошенной операции возвращает ответ в виде другого IRP менеджеру, а тот, в свою очередь, может при необходимости передать этот IRP другому драйверу. Менеджер позволяет драйверам задавать взаимосвязи (bindings) между собой, и на основании информации о взаимосвязях и происходит передача пакетов IRP. Кроме того, менеджер Windows NT поддерживает динамическую загрузку-выгрузку драйверов без останова системы.
Наличие стандартного внутреннего межмодульного интерфейса повышает устойчивость и улучшает расширяемость подсистемы ввода-вывода, хотя может несколько замедлить ее работу, так как любое разделение на слои и части приводит к дополнительным операциям при взаимодействии по сравнению с монолитной организацией с прямыми передачами управления.
Первоначально термин «драйвер» применялся в достаточно узком смысле: под драйвером понимался программный модуль, который:
Согласно этому определению драйвер вместе с контроллером устройства и прикладной программой воплощали идею многослойного подхода к организации программного обеспечения. Контроллер представлял нижний слой управления устройством, выполняющий операции в терминах блоков и агрегатов устройства (например, передвижение головки дисковода, побитную передачу байта по двухпроводному кабелю). Драйвер выполнял более сложные операции, преобразуя, например, данные, адресуемые в терминах номеров цилиндров, головок и секторов диска, в линейную последовательность блоков или устанавливая логическое соединение между двумя модемами через телефонную сеть. В результате прикладная программа уже работала с данными, преобразованными в достаточно понятную для человека форму, — файлами, таблицами баз данных, текстовыми окнами на мониторе и т. п., не вдаваясь в детали представления этих данных в устройствах ввода-вывода. Кроме того, помещение драйвера в привилегированный режим и запрет для пользовательских процессов выполнять операции ввода-вывода защищают критически важные для работы самой ОС устройства ввода-вывода от ошибок прикладных программ, а также позволяют ОС надежно контролировать процесс разделения устройств и их данных между пользователями и процессами.
В описанной схеме драйверы не делились на слои. При этом они выполняли задачи разного уровня сложности: как самые примитивные, например просто последовательно передавали контроллеру байты для дальнейшего использования, так и достаточно сложные, связанные с отработкой протокола взаимодействия между модемами или вычерчиванием на экране математических кривых.
Постепенно, по мере развития операционных систем и усложнения структуры подсистемы ввода-вывода, наряду с традиционными драйверами в операционных системах появились так называемые высокоуровневые драйверы, которые располагаются в общей модели подсистемы ввода-вывода над традиционными драйверами. Появление высокоуровневых драйверов можно считать дальнейшим развитием идеи многослойной организации подсистемы ввода-вывода. Вместо того чтобы концентрировать все функции по управлению устройством в одном программном модуле, во многих случаях гораздо эффективней распределить их между несколькими модулями в соседних слоях иерархии. Традиционные драйверы, которые стали называть аппаратными драйверами, низкоуровневыми драйверами, или драйверами устройств, подчеркивая их непосредственную связь с управляемым устройством, освобождаются от высокоуровневых функций и занимаются только низкоуровневыми операциями. Эти низкоуровневые операции составляют фундамент, на котором можно построить тот или иной набор операций в драйверах более высоких уровней.
При таком подходе повышается гибкость и расширяемость функций по управлению устройством — вместо жесткого набора функций, сосредоточенных в единственном драйвере, администратор ОС может выбрать требуемый набор функций, установив нужный высокоуровневый драйвер. Если различным приложениям необходимо работать с различными логическими моделями одного и того же физического устройства, то для этого достаточно установить в системе несколько драйверов на одном уровне, работающих над одним аппаратным драйвером.
Количество уровней драйверов в подсистеме ввода-вывода обычно не ограничивается каким-либо пределом, но на практике чаще всего используют от двух до пяти уровней драйверов — слишком большое количество уровней может снизить скорость операций ввода-вывода. Несколько драйверов, управляющих одним устройством, но на разных уровнях, можно рассматривать как набор отдельных драйверов или как один многоуровневый драйвер.
Высокоуровневые драйверы оформляются по тем же правилам и придерживаются тех же внутренних интерфейсов, что и аппаратные драйверы. Единственным отличием является то, что высокоуровневые драйверы, как правило, не вызываются по прерываниям, так как взаимодействуют с управляемым устройством через посредничество аппаратных драйверов. Менеджер ввода-вывода управляет драйверами однотипно, независимо от того, к какому уровню он относится. При наличии большого количества драйверов разного уровня усложняются связи между ними, что, в свою очередь, усложняет их взаимодействие, и именно эта ситуация привела к стандартизации внутреннего интерфейса в подсистеме ввода-вывода и выделения специальной оболочки в виде менеджера ввода-вывода, выполняющего служебные функции по организации работы драйверов.
Рассмотрим, как общие принципы построения многоуровневых драйверов могут быть реализованы при управлении определенными типами внешних устройств.
В вертикальной подсистеме сетевых устройств, приведенной на рис. 7.2, аппаратными драйверами являются драйверы сетевых адаптеров, которые выполняют функции низкоуровневых канальных протоколов, таких как Ethernet, Frame Relay, ATM и других. Эти драйверы выполняют простые функции — они организуют передачу кадров данных между компьютерами одной сети. Над ними располагается слой модулей, которые реализуют функции более интеллектуальных протоколов сетевого уровня — IP и IPX, которые могут обеспечить взаимодействие компьютеров разных сетей с произвольной топологией связей. Модули IP и IPX также могут быть оформлены как драйверы, хотя они находятся в промежуточном программном слое и непосредственно с аппаратурой не взаимодействуют. Вообще, вертикальная подсистема управления сетевыми устройствами является примером эффективного многоуровнего подхода к организации драйверов — просто в силу того, что в ее основе лежит хорошо продуманная семиуровневая модель взаимодействия открытых систем OSI. И, хотя все семь уровней модели OSI обычно не выделяются в самостоятельные программные уровни, четыре уровня драйверов чаще всего присутствуют в подсистеме управления сетевыми устройствами. Над слоем драйверов сетевых протоколов располагается слой драйверов транспортных протоколов, таких как TCP/UDP, SPX и NetBEUI, которые отвечают за надежную связь между компьютерами сети. Еще выше расположен слой драйверов протоколов прикладного уровня (на рисунке — http, ftp и 8MB), которые предоставляют пользователям сети конечные услуги по доступу к гипертекстовой информации, архивам файлов и многие другие.
В подсистеме управления графическими устройствами, такими как графические мониторы и принтеры, также существует несколько уровней драйверов. На нижнем уровне работают аппаратные драйверы, которые позволяют управлять конкретным графическим адаптером или принтером определенного типа, заставляя их выполнять некоторый набор примитивных графических операций: вывод точки, окружности, заполнение области цветом, вывод символов и т. п. Высокоуровневые графические драйверы строят на базе этих операций более мощные операции, например масштабирование изображения, преобразование графического формата в соответствии с разрешающими возможностями устройства и т. п. Самый верхний уровень подсистемы составляет менеджер окон, который создает для каждого приложения виртуальный образ экрана в виде набора окон, в которые приложение может выводить свои графические данные. Менеджер управляет окнами, отображая их в определенную область физического экрана или делая их невидимыми, а также предоставляет к ним совместный доступ с контролем прав доступа. Менеджер окон уже не зависит от особенностей конкретного графического устройства, предоставляя высокоуровневым драйверам заниматься преобразованием форматов выводимых данных.
В подсистеме управления дисками аппаратные драйверы поддерживают для верхних уровней представление диска как последовательного набора блоков одинакового размера, преобразуя вместе с контроллером номер блока в более сложный адрес, состоящий из номеров цилиндра, головки и сектора. Однако такие понятия, как «файл» и «файловая система», аппаратные драйверы дисков не поддерживают — эти удобные для пользователя и программиста логические абстракции создаются на более высоком уровне программным обеспечением файловых систем, которое в современных ОС также оформляется как драйвер, только высокоуровневый. Наличие универсальной среды, создаваемой менеджером ввода-вывода, позволяет достаточно просто решить проблему поддержки в ОС нескольких файловых систем одновременно. Для этого в ОС устанавливается несколько высокоуровневых драйверов (на рисунке это драйверы файловых систем ufs, NTFS и FAT), работающих с общими аппаратными драйверами, но по-своему организующими хранение данных в блоках диска и по-своему представляющими файловую систему пользователю и прикладным процессам. Для унификации представления различных файловых систем в подсистеме ввода-вывода может использоваться общий драйвер верхнего уровня, играющий роль диспетчера нескольких драйверов файловых систем. На рисунке в качестве примера показан диспетчер VFS (Virtual File System), применяемый в операционных системах UNIX, реализованных на основе кода System V Release 4.
Необязательно все модули подсистемы ввода-вывода оформляются в виде драйверов. Например, в подсистеме управлениями дисками обычно имеется такой модуль, как дисковый кэш, который служит для кэширования блоков дисковых файлов в оперативной памяти. Достаточно специфические функции кэша делают нецелесообразным оформление его в виде драйвера, взаимодействующего с другими модулями ОС только с помощью услуг менеджера ввода-вывода. Другим примером модуля, который чаще всего не оформляется в виде драйвера, является диспетчер окон графического интерфейса. Иногда этот модуль вообще выносится из ядра ОС и реализуется в виде пользовательского процесса. Таким образом был реализован диспетчер окон (а также высокоуровневые графические драйверы) в Windows NT 3.5 и 3.51, но этот микроядерный подход заметно замедлял графические операции, поэтому в Windows NT 4.0 диспетчер окон и высокоуровневые графические драйверы, а также графическая библиотека GDI были перенесены в пространство ядра.
Аппаратные драйверы после запуска операции ввода-вывода должны своевременно реагировать на завершение контроллером заданного действия, и для решения этой задачи они взаимодействуют с системой прерываний. Драйверы более высоких уровней вызываются уже не по прерываниям, а по инициативе аппаратных драйверов или драйверов вышележащего уровня. Не все процедуры аппаратного драйвера нужно вызывать по прерываниям, поэтому драйвер обычно имеет определенную структуру, в которой выделяется секция обработки прерываний (Interrupt Service Routine, ISR), которая и вызывается при поступлении запроса от соответствующего устройства диспетчером прерываний. Диспетчер прерываний можно считать частью подсистемы ввода-вывода, как это показано на рис. 7.2, а можно считать и независимым модулем ядра ОС, так как он служит не только для вызова секций обработки прерываний драйверов, но и для диспетчеризации прерываний других типов.
В унификацию драйверов большой вклад внесла операционная система UNIX. В ней все драйверы были разделены на два больших класса: блок-ориентированные (block-oriented) драйверы и байт-ориентированные (character-oriented) драйверы. Это деление является более общим, чем показанное на рис. 7.2 деление на вертикальные подсистемы. Например, драйверы графических устройств и драйверы сетевых устройств относятся к классу байт-ориентированных.
Блок-ориентированные драйверы управляют устройствами прямого доступа, которые хранят информацию в блоках фиксированного размера, каждый из которых имеет собственный адрес. Самое распространенное внешнее устройство прямого доступа — диск. Адресуемость блоков приводит к тому, что для устройств прямого доступа появляется возможность кэширования данных в оперативной памяти, и это обстоятельство значительно влияет на общую организацию ввода-вывода для блок-ориентированных драйверов.
Устройства, с которыми работают байт-ориентированные драйверы, не адресуемы и не позволяют производить операцию поиска данных, они генерируют или потребляют последовательности байт. Примерами таких устройств, которые также называют устройствами последовательного доступа, служат терминалы, строчные принтеры, сетевые адаптеры.
Значительность отличий блок-ориентированных и байт-ориентированных драйверов иллюстрирует тот факт, что среда STREAMS разработана только для байт-ориентированных драйверов и включить в нее блок-ориентированный драйвер невозможно.
Блок- или байт-ориентированность является характеристикой как самого устройства, так и драйвера. Очевидно, что если устройство не поддерживает обмен адресуемыми блоками данных, а позволяет записывать или считывать последовательность байт, то и устройство, и его драйвер можно назвать байт-ориентированными. Для байт-ориентированного устройства невозможно разработать блок-ориентированный драйвер. Устройство прямого доступа с блочной адресацией является блок-ориентированным, и для управления им естественно использовать блок-ориентированный драйвер. Однако блок-ориентированным устройством можно управлять и с помощью байт-ориентированного драйвера. Так, диск можно рассматривать не только как набор блоков, но и как набор байт, первый из которых начинает первый блок диска, а последний завершает последний блок. Физический обмен с контроллером устройства по-прежнему осуществляется блоками, но байт-ориентированный драйвер устройства будет преобразовывать блоки в последовательность байт. Для устройств прямого доступа часто разрабатывают пару драйверов, чтобы к устройству можно было обращаться и по байт-ориентированному, и по блок-ориентированному интерфейсам в зависимости от потребностей.
Деление всех драйверов на блок-ориентированные и байт-ориентированные оказывается полезным для структурирования подсистемы управления вводом-выводом. Тем не менее необходимо учитывать, что эта схема является упрощенной — имеются внешние устройства, драйверы которых не относятся ни к одному классу, например таймер, который, с одной стороны, не содержит адресуемой информации, а с другой стороны, не порождает потока байт. Это устройство только выдает сигнал прерывания в некоторые моменты времени.
Операционная система UNIX в свое время сделала еще один важный шаг по унификации операций и структуризации программного обеспечения ввода-вывода. В ОС UNIX все устройства рассматриваются как некоторые виртуальные (специальные) файлы, что дает возможность использовать общий набор базовых операций ввода-вывода для любых устройств независимо от их специфики. Эти вопросы обсуждаются в следующем разделе, посвященном файлам и файловым системам.
Специальные файлы, называемые иногда виртуальными, не связаны со статичными наборами данных, хранящихся на дисках, а являются удобным унифицированным представлением устройств ввода-вывода.
Понятие специального файла появилось в операционной системе UNIX. Специальный файл всегда связан с некоторым устройством ввода-вывода и представляет его для остальной части операционной системы и прикладных процессов в виде неструктурированного набора байт. Со специальным файлом можно работать так же, как и с обычным, то есть открывать, считывать из него определенное количество байт или же записывать в него определенное количество байт, а после завершения операции закрывать. Для этого используются те же системные вызовы, что и для работы с обычными файлами: open, create, read, write и close. Таким образом, для того чтобы вывести на алфавитно-цифровой терминал, с которым связан специальный файл /dev/tty3, сообщение "Hello, friends!", достаточно открыть этот файл с помощью системного вызова open:
fd =open ("/de/tty3". 2)
Затем можно вывести сообщение с помощью системного вызова write:
write (fd, "Hello, friends!". 15)
Для устройств прямого доступа имеет смысл также указатель текущего положения в файле, которым можно управлять с помощью системного вызова lseek.
Очевидно, что представление устройства в виде файла и использование для управления устройством файловых системных вызовов во многих случаях не позволяет выполнять только достаточно простые операции.
Традиционно специальные файлы помещаются в каталог /dev, хотя ничто не мешает создать их в любом каталоге файловой системы. При появлении нового устройства и соответственно нового драйвера администратор системы может создать новую запись с помощью команды mknod. Например, следующая команда создает блок-ориентированный специальный файл:
mknod /dev/dsk/sc4d2s3 b 32 33
Логическая организация файловой системы
Одной из основных задач операционной системы является предоставление удобств пользователю при работе с данными, хранящимися на дисках. Для этого ОС подменяет физическую структуру хранящихся данных некоторой удобной для пользователя логической моделью. Логическая модель файловой системы материализуется в виде дерева каталогов, выводимого на экран такими утилитами, как Norton Commander или Windows Explorer, в символьных составных именах файлов, в командах работы с файлами. Базовым элементом этой модели является файл, который так же, как и файловая система в целом, может характеризоваться как логической, так и физической структурой.
Цели и задачи файловой системы
Файл — это именованная область внешней памяти, в которую можно записывать и из которой можно считывать данные. Файлы хранятся в памяти, на зависящей от энергопитания, обычно — на магнитных дисках. Однако нет правил без исключения. Одним из таких исключений является так называемый электронный диск, когда в оперативной памяти создается структура, имитирующая файловую систему.
Основные цели использования файла перечислены ниже.
Файловая система (ФС) — это часть операционной системы, включающая:
Файловая система позволяет программам обходиться набором достаточно простых операций для выполнения действий над некоторым абстрактным объектом, представляющим файл. При этом программистам не нужно иметь дело с деталями действительного расположения данных на диске, буферизацией данных и другими низкоуровневыми проблемами передачи данных с долговременного запоминающего устройства. Все эти функции файловая система берет на себя. Файловая система распределяет дисковую память, поддерживает именование файлов, отображает имена файлов в соответствующие адреса во внешней памяти, обеспечивает доступ к данным, поддерживает разделение, защиту и восстановление файлов.
Таким образом, файловая система играет роль промежуточного слоя, экранирующего все сложности физической организации долговременного хранилища данных, и создающего для программ более простую логическую модель этого хранилища, а также предоставляя им набор удобных в использовании команд для манипулирования файлами.
Задачи, решаемые ФС, зависят от способа организации вычислительного процесса в целом. Самый простой тип — это ФС в однопользовательских и однопрограммных ОС, к числу которых относится, например, MS-DOS. Основные функции в такой ФС нацелены на решение следующих задач:
Задачи ФС усложняются в операционных однопользовательских мультипрограммных ОС, которые, хотя и предназначены для работы одного пользователя, но дают ему возможность запускать одновременно несколько процессов. Одной из первых ОС этого типа стала OS/2. К перечисленным выше задачам добавляется новая задача совместного доступа к файлу из нескольких процессов. Файл в этом случае является разделяемым ресурсом, а значит, файловая система должна решать весь комплекс проблем, связанных с такими ресурсами. В частности, в ФС должны быть предусмотрены средства блокировки файла и его частей, предотвращения гонок, исключение тупиков, согласование копий и т. п.
В многопользовательских системах появляется еще одна задача: защита файлов одного пользователя от несанкционированного доступа другого пользователя.
Еще более сложными становятся функции ФС, которая работает в составе сетевой ОС. Эта тема рассматривается в последней главе книги, посвященной управлению сетевыми ресурсами.
Файловые системы поддерживают несколько функционально различных типов файлов, в число которых, как правило, входят обычные файлы, файлы-каталоги, специальные файлы, именованные конвейеры, отображаемые в память файлы и другие.
Обычные файлы, или просто файлы, содержат информацию произвольного характера, которую заносит в них пользователь или которая образуется в результате работы системных и пользовательских программ. Большинство современных операционных систем (например, UNIX, Windows, OS/2) никак не ограничивает и не контролирует содержимое и структуру обычного файла. Содержание обычного файла определяется приложением, которое с ним работает. Например, текстовый редактор создает текстовые файлы, состоящие из строк символов, представленных в каком-либо коде. Это могут быть документы, исходные тексты программ и т. п. Текстовые файлы можно прочитать на экране и распечатать на принтере. Двоичные файлы не используют коды символов, они часто имеют сложную внутреннюю структуру, например исполняемый код программы или архивный файл. Все операционные системы должны уметь распознавать хотя бы один тип файлов — их собственные исполняемые файлы.
Каталоги — это особый тип файлов, которые содержат системную справочную информацию о наборе файлов, сгруппированных пользователями по какому-либо неформальному признаку (например, в одну группу объединяются файлы, содержащие документы одного договора, или файлы, составляющие один программный пакет). Во многих операционных системах в каталог могут входить файлы любых типов, в том числе другие каталоги, за счет чего образуется древовидная структура, удобная для поиска. Каталоги устанавливают соответствие между именами файлов и их характеристиками, используемыми файловой системой для управления файлами. В число таких характеристик входит, в частности, информация (или указатель на другую структуру, содержащую эти данные) о типе файла и расположении его на диске, правах доступа к файлу и датах его создания и модификации. Во всех остальных отношениях каталоги рассматриваются файловой системой как обычные файлы.
Специальные файлы — это фиктивные файлы, ассоциированные с устройствами ввода-вывода, которые используются для унификации механизма доступа к файлам и внешним устройствам. Специальные файлы позволяют пользователю выполнять операции ввода-вывода посредством обычных команд записи в файл или чтения из файла. Эти команды обрабатываются сначала программами файловой системы, а затем на некотором этапе выполнения запроса преобразуются операционной системой в команды управления соответствующим устройством.
Современные файловые системы поддерживают и другие типы файлов, такие как символьные связи, именованные конвейеры, отображаемые в память файлы. Они будут рассмотрены позже.
Иерархическая структура файловой системы
Пользователи обращаются к файлам по символьным именам. Однако способности человеческой памяти ограничивают количество имен объектов, к которым пользователь может обращаться по имени. Иерархическая организация пространства имен позволяет значительно расширить эти границы. Именно поэтому большинство файловых систем имеет иерархическую структуру, в которой уровни создаются за счет того, что каталог более низкого уровня может входить в каталог более высокого уровня (рис. 7.3).
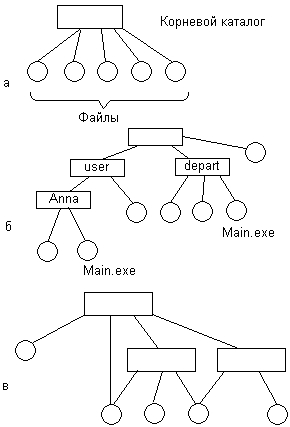
Рис. 7.3. Иерархия файловых систем
Граф, описывающий иерархию каталогов, может быть деревом или сетью. Каталоги образуют дерево, если файлу разрешено входить только в один каталог (рис. 7.3, б), и сеть — если файл может входить сразу в несколько каталогов (рис. 7.3, в). Например, в MS-DOS и Windows каталоги образуют древовидную структуру, а в UNIX — сетевую. В древовидной структуре каждый файл является листом. Каталог самого верхнего уровня называется корневым каталогом, или корнем (root).
При такой организации пользователь освобожден от запоминания имен всех файлов, ему достаточно примерно представлять, к какой группе может быть отнесен тот или иной файл, чтобы путем последовательного просмотра каталогов найти его. Иерархическая структура удобна для многопользовательской работы: каждый пользователь со своими файлами локализуется в своем каталоге или поддереве каталогов, и вместе с тем все файлы в системе логически связаны.
Частным случаем иерархической структуры является одноуровневая организация, когда все файлы входят в один каталог (рис. 7.3,
а).
Все типы файлов имеют символьные имена. В иерархически организованных файловых системах обычно используются три типа имен -файлов: простые, составные и относительные.
Простое, или короткое, символьное имя идентифицирует файл в пределах одного каталога. Простые имена присваивают файлам пользователи и программисты, при этом они должны учитывать ограничения ОС как на номенклатуру символов, так и на длину имени. До сравнительно недавнего времени эти границы были весьма узкими. Так, в популярной файловой системе FAT длина имен ограничивались схемой 8.3 (8 символов — собственно имя, 3 символа — расширение имени), а в файловой системе s5, поддерживаемой многими версиями ОС UNIX, простое символьное имя не могло содержать более 14 символов. Однако пользователю гораздо удобнее работать с длинными именами, поскольку они позволяют дать файлам легко запоминающиеся названия, ясно говорящие о том, что содержится в этом файле. Поэтому современные файловые системы, а также усовершенствованные варианты уже существовавших файловых систем, как правило, поддерживают длинные простые символьные имена файлов. Например, в файловых сие- • темах NTFS и FAT32, входящих в состав операционной системы Windows NT, имя файла может содержать до 255 символов.
Примеры простых имен файлов и каталогов:
quest_ul.doc
task-entran.exe
приложение к СО 254L на русском языке.doc
installable filesystem manager.doc
В иерархических файловых системах разным файлам разрешено иметь одинаковые простые символьные имена при условии, что они принадлежат разным каталогам. То есть здесь работает схема «много файлов — одно простое имя». Для одпозначной идентификации файла в таких системах используется так называемое полное имя.
Полное имя представляет собой цепочку простых символьных имен всех каталогов, через которые проходит путь от корня до данного файла. Таким образом, полное имя является составным, в котором простые имена отделены друг от друга принятым в ОС разделителем. Часто в качестве разделителя используется прямой или обратный слеш, при этом принято не указывать имя корневого каталога. На рис. 7.3, б два файла имеют простое имя main.exe, однако их составные имена /depart/main.ехе и /user/anna/main.exe различаются.
В древовидной файловой системе между файлом и его полным именем имеется взаимно однозначное соответствие «один файл — одно полное имя». В файловых системах, имеющих сетевую структуру, файл может входить в несколько каталогов, а значит, иметь несколько полных имен; здесь справедливо соответствие «один файл — много полных имен». В обоих случаях файл однозначно идентифицируется полным именем.
Файл может быть идентифицирован также относительным именем. Относительное имя файла определяется через понятие «текущий каталог». Для каждого пользователя в каждый момент времени один из каталогов файловой системы является текущим, причем этот каталог выбирается самим пользователем по команде ОС. Файловая система фиксирует имя текущего каталога, чтобы затем использовать его как дополнение к относительным именам для образования полного имени файла. При использовании относительных имен пользователь идентифицирует файл цепочкой имен каталогов, через которые проходит маршрут от текущего каталога до данного файла. Например, если текущим каталогом является каталог /user, то относительное имя файла /user/anna/main.exe выглядит следующим образом: anna/ main.exe.
В некоторых операционных системах разрешено присваивать одному и тому же файлу несколько простых имен, которые можно интерпретировать как псевдонимы. В этом случае, так же как в системе с сетевой структурой, устанавливается соответствие «один файл — много полных имен», так как каждому простому имени файла соответствует по крайней мере одно полное имя.
И хотя полное имя однозначно определяет файл, операционной системе проще работать с файлом, если между файлами и их именами имеется взаимно однозначное соответствие. С этой целью она присваивает файлу
уникальное имя, так что справедливо соотношение
«один файл — одно уникальное имя». Уникальное имя существует наряду с одним или несколькими символьными именами, присваиваемыми файлу пользователями или приложениями. Уникальное имя представляет собой числовой идентификатор и предназначено только для операционной системы. Примером такого уникального имени файла является номер индексного дескриптора в системе
UNIX.
В общем случае вычислительная система может иметь несколько дисковых устройств. Даже типичный персональный компьютер обычно имеет один накопитель на жестком диске, один накопитель на гибких дисках и накопитель для компакт-дисков. Мощные же компьютеры, как правило, оснащены большим количеством дисковых накопителей, на которые устанавливаются пакеты дисков. Более того, даже одно физическое устройство с помощью средств операционной системы может быть представлено в виде нескольких логических устройств, в частности путем разбиения дискового пространства на разделы. Возникает вопрос, каким образом организовать хранение файлов в системе, имеющей несколько устройств внешней памяти?
Первое решение состоит в том, что на каждом из устройств размещается автономная файловая система, то есть файлы, находящиеся на этом устройстве, описываются деревом каталогов, никак не связанным с деревьями каталогов на других устройствах. В таком случае для однозначной идентификации файла пользователь наряду с составным символьным именем файла должен указывать идентификатор логического устройства. Примером такого автономного существования файловых систем является операционная система MS-DOS, в которой полное имя файла включает буквенный идентификатор логического диска. Так, при обращении к файлу, расположенному на диске А, пользователь должен указать имя этого диска: A:\privat\letter\uni\let1.doc1.
1 На практике чаще используется относительная форма именования, которая не включает имя диска и цепочку имей каталогов верхнего уровня, заданных по умолчанию.
Другим вариантом является такая организация хранения файлов, при которой пользователю предоставляется возможность объединять файловые системы, находящиеся на разных устройствах, в единую файловую систему, описываемую единым деревом каталогов. Такая операция называется моптированием. Рассмотрим, как осуществляется эта операция на примере ОС UNIX.
Среди всех имеющихся в системе логических дисковых устройств операционная система выделяет одно устройство, называемое системным. Пусть имеются две файловые системы, расположенные на разных логических дисках (рис. 7.4), причем один, из дисков является системным.
Файловая система, расположенная на системном диске, назначается корневой. Для связи иерархий файлов в корневой файловой системе выбирается некоторый существующий каталог, в данном примере — каталог man. После выполнения монтирования выбранный каталог man становится корневым каталогом второй файловой системы. Через этот каталог монтируемая файловая система подсоединяется как поддерево к общему дереву (рис. 7.5).
После монтирования общей файловой системы для пользователя нет логической разницы между корневой и смонтированной файловыми системами, в частности именование файлов производится так же, как если бы она с самого начала была единой.
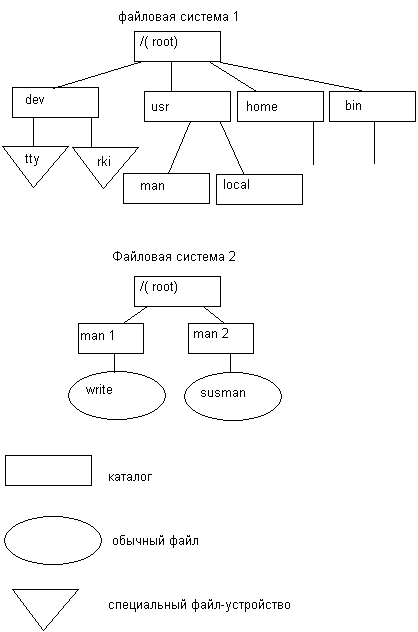
Рис. 7.4. Две файловые системы до монтирования
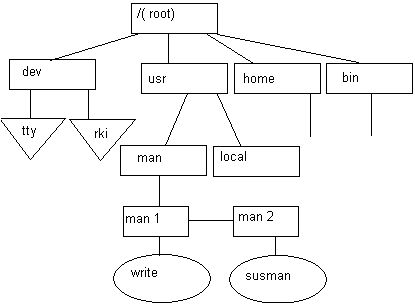
Рис. 7.5. Общая файловая система после монтирования
Понятие «файл» включает не только хранимые им данные и имя, но и атрибуты. Атрибуты — это информация, описывающая свойства файла. Примеры возможных атрибутов файла:
Набор атрибутов файла определяется спецификой файловой системы: в файловых системах разного типа для характеристики файлов могут использоваться разные наборы атрибутов. Например, в файловых системах, поддерживающих неструктурированные файлы, нет необходимости использовать три последних атрибута в приведенном списке, связанных со структуризацией файла. В однопользовательской ОС в наборе атрибутов будут отсутствовать характеристики, имеющие отношение к пользователям и защите, такие как владелец файла, создатель файла, пароль для доступа к файлу, информация о разрешенном доступе к файлу.
Пользователь может получать доступ к атрибутам, используя средства, предоставленные для этих целей файловой системой. Обычно разрешается читать значения любых атрибутов, а изменять — только некоторые. Например, пользователь может изменить права доступа к файлу (при условии, что он обладает необходимыми для этого полномочиями), но изменять дату создания или текущий размер файла ему не разрешается.
Значения атрибутов файлов могут непосредственно содержаться в каталогах, как это сделано в файловой системе MS-DOS (рис. 7.6, а). На рисунке представлена структура записи в каталоге, содержащая простое символьное имя и атрибуты файла. Здесь буквами обозначены признаки файла: R — только для чтения, А — архивный, Н — скрытый, S — системный.
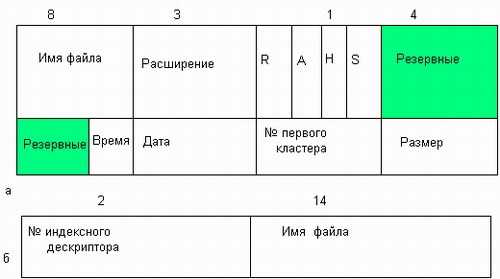
Рис. 7.6. Структура каталогов: а — структура записи каталога MS-DOS (32 байта), б — структура записи каталога ОС UNIX
Другим вариантом является размещение атрибутов в специальных таблицах, когда в каталогах содержатся только ссылки на эти таблицы. Такой подход реализован, например, в файловой системе ufs ОС UNIX. В этой файловой системе структура каталога очень простая. Запись о каждом файле содержит короткое символьное имя файла и указатель на индексный дескриптор файла, так называется в ufs таблица, в которой сосредоточены значения атрибутов файла (рис. 7.6, б).
В том и другом вариантах каталоги обеспечивают связь между именами файлов и собственно файлами. Однако подход, когда имя файла отделено от его атрибутов, делает систему более гибкой. Например, файл может быть легко включен сразу в несколько каталогов. Записи об этом файле в разных каталогах могут содержать разные простые имена, но в поле ссылки будет указан один и тот же номер индексного дескриптора.
В общем случае данные, содержащиеся в файле, имеют некую логическую структуру. Эта структура является базой при разработке программы, предназначенной для обработки этих данных. Например, чтобы текст мог быть правильно выведен на экран, программа должна иметь возможность выделить отдельные слова, строки, абзацы и т. д. Признаками, отделяющими один структурный элемент от другого, могут служить определенные кодовые последовательности или просто известные программе значения смещений этих структурных элементов относительно начала файла. Поддержание структуры данных может быть либо целиком возложено на приложение, либо в той или иной степени эту работу может взять на себя файловая система.
В первом случае, когда все действия, связанные со структуризацией и интерпретацией содержимого файла целиком относятся к ведению приложения, файл представляется ФС неструктурированной последовательностью данных. Приложение формулирует запросы к файловой системе на ввод-вывод, используя общие для всех приложений системные средства, например, указывая смещение от начала файла и количество байт, которые необходимо считать или записать. Поступивший к приложению поток байт интерпретируется в соответствии с заложенной в программе логикой. Например, компилятор генерирует, а редактор связей воспринимает вполне определенный формат объектного модуля программы. При этом формат файла, в котором хранится объектный модуль, известен только этим программам. Подчеркнем, что интерпретация данных никак не связана с действительным способом их хранения в файловой системе.
Модель файла, в соответствии с которой содержимое файла представляется неструктурированной последовательностью (потоком) байт, стала популярной вместе с ОС UNIX, а теперь она широко используется в большинстве современных ОС, в том числе в MS-DOS, Windows NT/2000, NetWare. Неструктурированная модель файла позволяет легко организовать разделение файла между несколькими приложениями: разные приложения могут по-своему структурировать и интерпретировать данные, содержащиеся в файле.
Другая модель файла, которая применялась в ОС OS/360, DEC RSX и VMS, а в настоящее время используется достаточно редко, — это структурированный файл. В этом случае поддержание структуры файла поручается файловой системе. Файловая система видит файл как упорядоченную последовательность логических записей. Приложение может обращаться к ФС с запросами на ввод-вывод на уровне записей, например «считать запись 25 из файла FILE.DOC». ФС должна обладать информацией о структуре файла, достаточной для того, чтобы выделить любую запись. ФС предоставляет приложению доступ к записи, а вся дальнейшая обработка данных, содержащихся в этой записи, выполняется приложением. Развитием этого подхода стали системы управления базами данных (СУБД), которые поддерживают не только сложную структуру данных, но и взаимосвязи между ними.
Логическая запись является наименьшим элементом данных, которым может оперировать программист при организации обмена с внешним устройством. Даже если физический обмен с устройством осуществляется большими единицами, операционная система должна обеспечивать программисту доступ к отдельной логической записи.
Файловая система может использовать два способа доступа к логическим записям: читать или записывать логические записи последовательно (последовательный доступ) или позиционировать файл на запись с указанным номером (прямой доступ).
Очевидно, что ОС не может поддерживать все возможные способы структурирования данных в файле, поэтому в тех ОС, в которых вообще существует поддержка логической структуризации файлов, она существует для небольшого числа широко распространенных схем логической организации файла.
К числу таких способов структуризации относится представление данных в виде записей, длина которых фиксирована в пределах файла (рис. 7.7, а). В таком случае доступ к n-й записи осуществляется либо путем последовательного чтения (n-1) предшествующих записей, либо прямо по адресу, вычисленному по ее порядковому номеру. Например, если L — длина записи, то начальный адрес n-й записи равен Lxn. Заметим, что при такой логической организации размер записи фиксирован в пределах файла, а записи в различных файлах, принадлежащих одной и той же файловой системе, могут иметь различный размер.
Другой способ структуризации состоит в представлении данных в виде последовательности записей, размер которых изменяется в пределах одного файла. Если расположить значения длин записей так, как это показано на рис. 7.7, б, то для поиска нужной записи система должна последовательно считать все предшествующие записи. Вычислить адрес нужной записи по ее номеру при такой логической организации файла невозможно, а следовательно, не может быть применен более эффективный метод прямого доступа.
Файлы, доступ к записям которых осуществляется последовательно, по номерам позиций, называются неиндексированными, или последовательными.
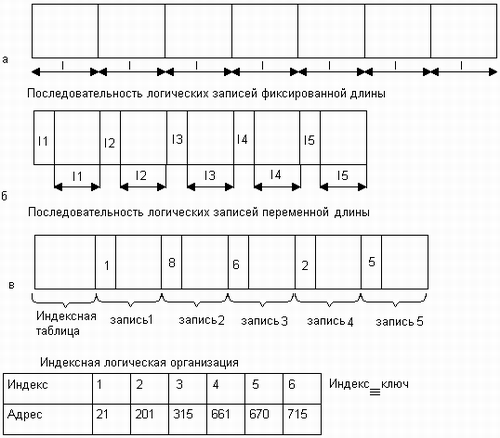
Рис. 7.7. Способы логической организации файлов
Другим типом файлов являются индексированные файлы, они допускают более быстрый прямой доступ к отдельной логической записи. В индексированном файле (рис. 7.7, в) записи имеют одно или более ключевых (индексных) полей и могут адресоваться путем указания значений этих полей. Для быстрого поиска данных в индексированном файле предусматривается специальная индексная таблица, в которой значениям- ключевых полей ставится в соответствие адрес внешней памяти. Этот адрес может указывать либо непосредственно на искомую запись, либо на некоторую область внешней памяти, занимаемую несколькими записями, в число которых входит искомая запись. В последнем случае говорят, что файл имеет индексно -последовательную организацию, так как поиск включает два этапа: прямой доступ по индексу к указанной области диска, а затем последовательный просмотр записей в указанной области. Ведение индексных таблиц берет на себя файловая система. Понятно, что записи в индексированных файлах могут иметь произвольную длину.
Все вышесказанное в большей степени относится к обычным файлам, которые могут быть как структурированными, так и неструктурированными. Что же касается других типов файлов, то они обладают определенной структурой, известной файловой системе. Например, файловая система должна понимать структуру данных, хранящихся в файле-каталоге или файле типа «символьная связь».
Физическая организация файловой системы
Представление пользователя о файловой системе как об иерархически организованном множестве информационных объектов имеет мало общего с порядком хранения файлов на диске. Файл, имеющий образ цельного, непрерывающегося набора байт, на самом деле очень часто разбросан «кусочками» по всему диску, причем это разбиение никак не связано с логической структурой файла, например, его отдельная логическая запись может быть расположена в несмежных секторах диска. Логически объединенные файлы из одного каталога совсем не обязаны соседствовать на диске. Принципы размещения файлов, каталогов и системной информации на реальном устройстве описываются
физической организацией файловой системы. Очевидно, что разные файловые системы имеют разную физическую организацию.
Диски, разделы, секторы, кластеры
Основным типом устройства, которое используется в современных вычислительных системах для хранения файлов, являются дисковые накопители. Эти устройства предназначены для считывания и записи данных на жесткие и гибкие магнитные диски. Жесткий диск состоит из одной или нескольких стеклянных или металлических пластин, каждая из которых покрыта с одной или двух сторон магнитным материалом. Таким образом, диск в общем случае состоит из пакета пластин (рис. 7.8).
На каждой стороне каждой пластины размечены тонкие концентрические кольца — дорожки (traks), на которых хранятся данные. Количество дорожек зависит от типа диска. Нумерация дорожек начинается с 0 от внешнего края к центру диска. Когда диск вращается, элемент, называемый головкой, считывает двоичные данные с магнитной дорожки или записывает их на магнитную дорожку.
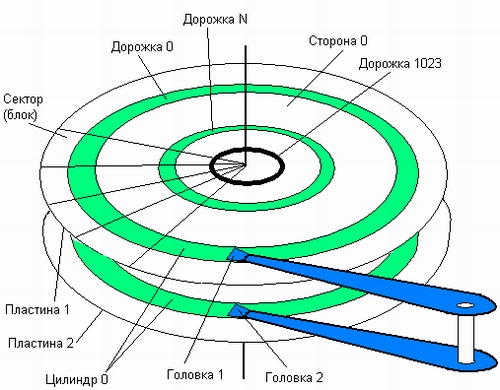
Рис. 7.8. Схема устройства жесткого диска
Головка может позиционироваться над заданной дорожкой. Головки перемещаются над поверхностью диска дискретными шагами, каждый шаг соответствует сдвигу на одну дорожку. Запись на диск осуществляется благодаря способности головки изменять магнитные свойства дорожки. В некоторых дисках вдоль каждой поверхности перемещается одна головка, а в других — имеется по головке на каждую дорожку. В первом случае для поиска информации головка должна перемещаться по радиусу диска. Обычно все головки закреплены на едином перемещающем механизме и двигаются синхронно. Поэтому, когда головка фиксируется на заданной дорожке одной поверхности, все остальные головки останавливаются над дорожками с такими же номерами. В тех же случаях, когда на каждой дорожке имеется отдельная головка, никакого перемещения головок с одной дорожки на другую не требуется, за счет этого экономится время, затрачиваемое на поиск данных.
Совокупность дорожек одного радиуса на всех поверхностях всех пластин пакета называется цилиндром {cylinder). Каждая дорожка разбивается на фрагменты, называемые секторами (sectors), или блоками (blocks), так что все дорожки имеют равное число секторов, в которые можно максимально записать одно и то же число байт1. Сектор имеет фиксированный для конкретной системы размер, выражающийся степенью двойки. Чаще всего размер сектора составляет 512 байт. Учитывая, что дорожки разного радиуса имеют одинаковое число секторов, плотность записи становится тем выше, чем ближе дорожка к центру.
1 Иногда внешняя дорожка имеет несколько дополнительных секторов, используемых для замены поврежденных секторов в режиме горячего резервирования.
Сектор — наименьшая адресуемая единица обмена данными дискового устройства с оперативной памятью. Для того чтобы контроллер мог найти на диске нужный сектор, необходимо задать ему все составляющие адреса сектора: номер цилиндра, номер поверхности и номер сектора. Так как прикладной программе в общем случае нужен не сектор, а некоторое количество байт, не обязательно кратное размеру сектора, то типичный запрос включает чтение нескольких секторов, содержащих требуемую информацию, и одного или двух секторов, содержащих наряду с требуемыми избыточные данные (рис. 7.9).
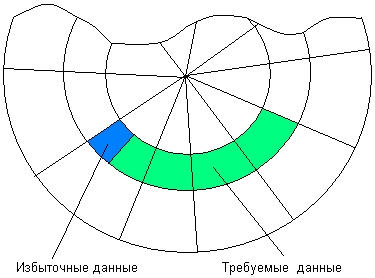
Рис. 7.9. Считывание избыточных данных при обмене с диском
Операционная система при работе с диском использует, как правило, собственную единицу дискового пространства, называемую кластером (cluster)1. При создании файла место на диске ему выделяется кластерами. Например, если файл имеет размер 2560 байт, а размер кластера в файловой системе определен в 1024 байта, то файлу будет выделено на диске 3 кластера.
1 Иногда кластер называют блоком (например, в ОС Unix), что может привести к терми нологической путанице. Вообще, терминология, используемая при описании форматов дисков и файловых систем, зависит от аппаратной платформы (RISC, Wintel и т. п.) и операционной системы. Это нужно учитывать и трактовать термины в зависимости от контекста.
Дорожки и секторы создаются в результате выполнения процедуры физического, или низкоуровневого, форматирования диска, предшествующей использованию диска. Для определения границ блоков на диск записывается идентификационная информация. Низкоуровневый формат диска не зависит от типа операционной системы, которая этот диск будет использовать.
Разметку диска под конкретный тип файловой системы выполняют процедуры высокоуровневого, или логического, форматирования. При высокоуровневом форматировании определяется размер кластера и на диск записывается информация, необходимая для работы файловой системы, в том числе информация о доступном и неиспользуемом пространстве, о границах областей, отведенных под файлы и каталоги, информация о поврежденных областях. Кроме того, на диск записывается загрузчик операционной системы — небольшая программа, которая начинает процесс инициализации операционной системы после включения питания или рестарта компьютера.
Прежде чем форматировать диск под определенную файловую систему, он может быть разбит на разделы. Раздел — это непрерывная часть физического диска, которую операционная система представляет пользователю как логическое устройство (используются также названия логический диск и логический раздел)1. Логическое устройство функционирует так, как если бы это был отдельный физический диск. Именно с логическими устройствами работает пользователь, обращаясь к ним по символьным именам, используя, например, обозначения А, В, С, SYS и т. п. Операционные системы разного типа используют единое для всех них представление о разделах, но создают на его основе логические устройства, специфические для каждого типа ОС. Так же как файловая система, с которой работает одна ОС, в общем случае не может интерпретироваться ОС другого типа, логические устройства не могут быть использованы операционными системами разного типа. На каждом логическом устройстве может создаваться только одна файловая система.
1Во многих операционных системах используется термин «том» {volume). В разных ОС толкование этого термина имеет свои нюансы, но чаще всего он обозначает логическое устройство, отформатированное под конкретную файловую систему.
В частном случае, когда все дисковое пространство охватывается одним разделом, логическое устройство представляет физическое устройство в целом. Если диск разбит на несколько разделов, то для каждого из этих разделов может быть создано отдельное логическое устройство. Логическое устройство может быть создано и на базе нескольких разделов, причем эти разделы не обязательно должны принадлежать одному физическому устройству. Объединение нескольких разделов в единое логическое устройство может выполняться разными способами и преследовать разные цели, основные из которых: увеличение общего объема логического раздела, повышение производительности и отказоустойчивости. Примерами организации совместной работы нескольких дисковых разделов являются так называемые RAID-массивы, подробнее о которых будет сказано далее.
На разных логических устройствах одного и того же физического диска могут располагаться файловые системы разного типа. На рис. 7.10 показан пример диска, разбитого на три раздела, в которых установлены две файловых системы NTFS (разделы С и Е) и одна файловая система FAT (раздел D).
Все разделы одного диска имеют одинаковый размер блока, определенный для данного диска в результате низкоуровневого форматирования. Однако в результате высокоуровневого форматирования в разных разделах одного и того же диска, представленных разными логическими устройствами, могут быть установлены файловые системы, в которых определены кластеры отличающихся размеров.
Операционная система может поддерживать разные статусы разделов, особым образом отмечая разделы, которые могут быть использованы для загрузки модулей операционной системы, и разделы, в которых можно устанавливать только приложения и хранить файлы данных. Один из разделов диска помечается как загружаемый (или активный). Именно из этого раздела считывается загрузчик операционной системы.
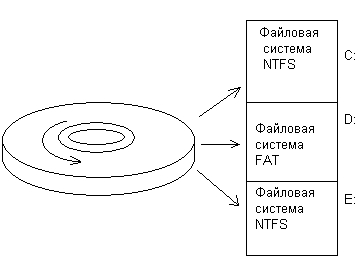
Рис. 7.10. Разбиение диска на разделы
Физическая организация и адресация файла
Важным компонентом физической организации файловой системы является физическая организация файла, то есть способ размещения файла на диске. Основными критериями эффективности физической организации файлов являются:
Непрерывное размещение — простейший вариант физической организации (рис. 7.11, а), при котором файлу предоставляется последовательность кластеров диска, образующих непрерывный участок дисковой памяти. Основным достоинством этого метода является высокая скорость доступа, так как затраты на поиск и считывание кластеров файла минимальны. Также минимален объем адресной информации — достаточно хранить только номер первого кластера и объем файла. Данная физическая организация максимально возможный размер файла не ограничивает. Однако этот вариант имеет существенные недостатки, которые затрудняют его применимость на практике, несмотря на всю его логическую простоту. При более пристальном рассмотрении оказывается, что реализовать эту схему не так уж просто. Действительно, какого размера должна быть непрерывная область, выделяемая файлу, если файл при каждой модификации может увеличить свой размер? Еще более серьезной проблемой является фрагментация. Спустя некоторое время после создания файловой системы в результате выполнения многочисленных операций создания и удаления файлов пространство диска неминуемо превращается в «лоскутное одеяло», включающее большое число свободных областей небольшого размера. Как всегда бывает при фрагментации, суммарный объем свободной памяти может быть очень большим, а выбрать место для размещения файла целиком невозможно. Поэтому на практике используются методы, в которых файл размещается в нескольких, в общем случае несмежных областях диска.
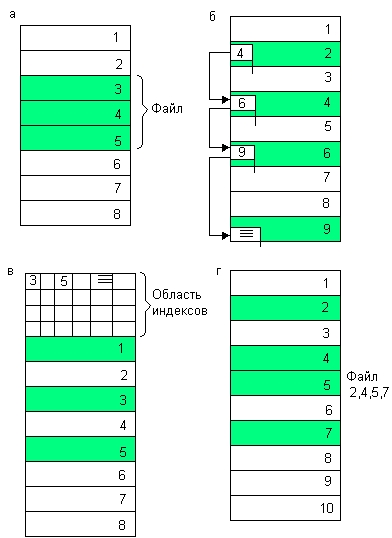
Рис. 7.11. Физическая организация файла: непрерывное размещение (а); связанный список кластеров (б); связанный список индексов (в); перечень номеров кластеров (г)
Следующий способ физической организации — размещение файла в виде связанного списка кластеров дисковой памяти (рис. 7.11, б). При таком способе в начале каждого кластера содержится указатель на следующий кластер. В этом случае адресная информация минимальна: расположение файла может быть задано одним числом — номером первого кластера. В отличие от предыдущего способа каждый кластер может быть присоединен к цепочке кластеров какого-либо файла, следовательно, фрагментация на уровне кластеров отсутствует. Файл может изменять свой размер во время своего существования, наращивая число кластеров. Недостатком является сложность реализации доступа к произвольно заданному месту файла — чтобы прочитать пятый по порядку кластер файла, необходимо последовательно прочитать четыре первых кластера, прослеживая цепочку номеров кластеров. Кроме того, при этом способе количество данных файла, содержащихся в одном кластере, не равно степени двойки (одно слово израсходовано на номер следующего кластера), а многие программы читают данные кластерами, размер которых равен степени двойки.
Популярным способом, применяемым, например, в файловой системе FAT, является использование связанного списка индексов (рис. 7.11, в). Этот способ является некоторой модификацией предыдущего. Файлу также выделяется память в виде связанного списка кластеров. Номер первого кластера запоминается в записи каталога, где хранятся характеристики этого файла. Остальная адресная информация отделена от кластеров файла. С каждым кластером диска связывается некоторый элемент — индекс. Индексы располагаются в отдельной области диска — в MS-DOS это таблица FAT (File Allocation Table), занимающая один кластер. Когда память свободна, все индексы имеют нулевое значение. Если некоторый кластер N назначен некоторому файлу, то индекс этого кластера становится равным либо номеру М следующего кластера данного файла, либо принимает специальное значение, являющееся признаком того, что этот кластер является для файла последним. Индекс же предыдущего кластера файла принимает значение N, указывая на вновь назначенный кластер.
При такой физической организации сохраняются все достоинства предыдущего способа: минимальность адресной информации, отсутствие фрагментации, отсутствие проблем при изменении размера. Кроме того, данный способ обладает дополнительными преимуществами. Во-первых, для доступа к произвольному кластеру файла не требуется последовательно считывать его кластеры, достаточно прочитать только секторы диска, содержащие таблицу индексов, отсчитать нужное количество кластеров файла по цепочке и определить номер нужного кластера. Во-вторых, данные файла заполняют кластер целиком, а значит, имеют объем, равный степени двойки.
ПРИМЕЧАНИЕ
Необходимо отметить, что при отсутствии фрагментации на уровне кластеров на диске все равно имеется определенное количество областей памяти небольшого размера, которые невозможно использовать, то есть фрагментация все же существует. Эти фрагменты представляют собой неиспользуемые части последних кластеров, назначенных файлам, поскольку объем файла в общем случае не кратен размеру кластера. На каждом файле в среднем теряется половина кластера. Это потери особенно велики, когда на диске имеется большое количество маленьких файлов, а кластер имеет большой размер. Размеры кластеров зависят от размера раздела и типа файловой системы. Примерный диапазон, в котором может меняться размер кластера, составляет от 512 байт до десятков килобайт.
Еще один способ задания физического расположения файла заключается в простом перечислении номеров кластеров, занимаемых этим файлом (рис. 7.11, г). Этот перечень и служит адресом файла. Недостаток данного способа очевиден: длина адреса зависит от размера файла и для большого файла может составить значительную величину. Достоинством же является высокая скорость доступа к произвольному кластеру файла, так как здесь применяется прямая адресация, которая исключает просмотр цепочки указателей при поиске адреса произвольного кластера файла. Фрагментация на уровне кластеров в этом способе также отсутствует.
Последний подход с некоторыми модификациями используется в традиционных файловых системах ОС UNIX s5 и ufs1. Для сокращения объема адресной информации прямой способ адресации сочетается с косвенным.
1 Современные версии UNIX поддерживают и другие типы файловых систем, в том числе и пришедшие из других ОС, как, например, FAT.
В стандартной на сегодняшний день для UNIX файловой системе ufs используется следующая схема адресации кластеров файла. Для хранения адреса файла выделено 15 полей, каждое из которых состоит из 4 байт (рис. 7.12). Если размер файла меньше или равен 12 кластерам, то номера этих кластеров непосредственно перечисляются в первых двенадцати полях адреса. Если кластер имеет размер 8 Кбайт (максимальный размер кластера, поддерживаемого в ufs), то таким образом можно адресовать файл размером до 8192x12 - 98 304 байт.
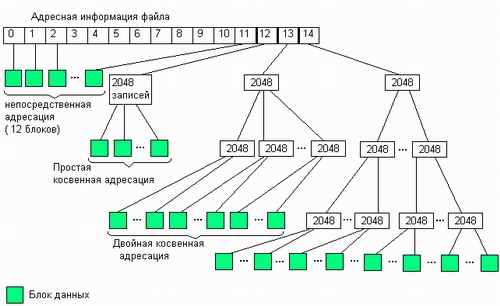
Рис. 7.12. Схема адресации файловой системы ufs
Если размер файла превышает 12 кластеров, то следующее 13-е поле содержит адрес кластера, в котором могут быть расположены номера следующих кластеров файла. Таким образом, 13-й элемент адреса используется для косвенной адресации. При размере в 8 Кбайт кластер, на который указывает 13-й элемент, может содержать 2048 номеров следующих кластеров данных файла и размер файла может возрасти до 8192х(12+2048)=16 875 520 байт.
Если размер файла превышает 12+2048— 2060 кластеров, то используется 14-е поле, в котором находится номер кластера, содержащего 2048 номеров кластеров, каждый из которых хранят 2048 номеров кластеров данных файла. Здесь применяется уже двойная косвенная адресация. С ее помощью можно адресовать кластеры в файлах, содержащих до 8192х(12+2048+20482) = 3,43766x10'° байт.
И наконец, если файл включает более 12+2048+20482 = 4 196 364 кластеров, то используется последнее 15-е поле для тройной косвенной адресации, что позволяет задать адрес файла, имеющего следующий максимальный размер:
8192х(12+2048+20482+20483)=7,0403х1013 байт.
Таким образом, файловая система ufs при размере кластера в 8 Кбайт поддерживает файлы, состоящие максимум из 70 триллионов байт данных, хранящихся в 8 миллиардах кластеров. Как видно на рис. 7.12, для задания адресной информации о максимально большом файле требуется: 15 элементов по 4 байта (60 байт) в центральной части адреса плюс 1+(1+2048)+(1+2048+20482) = 4 198403 кластера в косвенной части адреса. Несмотря на огромную величину, это число составляет всего около 0,05 % от объема адресуемых данных.
Файловая система ufs поддерживает дисковые кластеры и меньших размеров, при этом максимальный размер файла будет другим. Используемая в более ранних версиях UNIX файловая система s5 имеет аналогичную схему адресации, но она рассчитана на файлы меньших размеров, поэтому в ней используется 13 адресных элементов вместо 15.
Метод перечисления адресов кластеров файла задействован и в файловой системе NTFS, используемой в ОС Windows NT/2000. Здесь он дополнен достаточно естественным приемом, сокращающим объем адресной информации: адресуются не кластеры файла, а непрерывные области, состоящие из смежных кластеров диска. Каждая такая область, называемая отрезком (run), или экстентом (extent), описывается с помощью двух чисел: начального номера кластера и количества кластеров в отрезке. Так как для сокращения времени операции обмена ОС старается разместить файл в последовательных кластерах диска, то в большинстве случаев количество последовательных областей файла будет меньше количества кластеров файла и объем служебной адресной информации в NTFS сокращается по сравнению со схемой адресации файловых систем ufs/s5.
Для того чтобы корректно принимать решение о выделении файлу набора кластеров, файловая система должна отслеживать информацию о состоянии всех кластеров диска: свободен/занят. Эта информация может храниться как отдельно от адресной информации файлов, так и вместе с ней.
Логический раздел, отформатированный под файловую систему FAT, состоит из следующих областей (рис. 7.13).
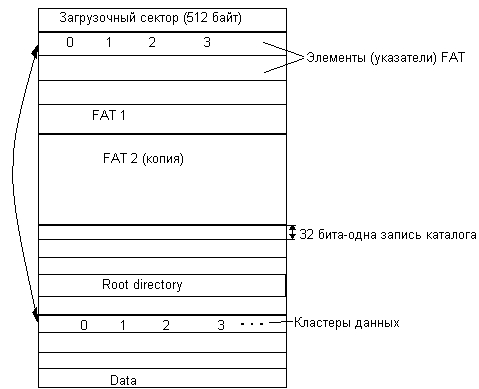
Рис. 7.13. Физическая структура файловой системы FAT
Файловая система FAT поддерживает всего два типа файлов: обычный файл и каталог. Файловая система распределяет память только из области данных, причем использует в качестве минимальной единицы дискового пространства кластер.
Таблица FAT (как основная копия, так и резервная) состоит из массива индексных указателей, количество которых равно количеству кластеров области данных. Между кластерами и индексными указателями имеется взаимно однозначное соответствие — нулевой указатель соответствует нулевому кластеру и т. д.
Индексный указатель может принимать следующие значения, характеризующие состояние связанного с ним кластера:
Таблица FAT является общей для всех файлов раздела. В исходном состоянии (после форматирования) все кластеры раздела свободны и все индексные указатели (кроме тех, которые соответствуют резервным и дефектным блокам) принимают значение «кластер свободен». При размещении файла ОС просматривает FAT, начиная с начала, и ищет первый свободный индексный указатель. После его обнаружения в поле записи каталога «номер первого кластера» (см. рис. 7.6, а) фиксируется номер этого указателя. В кластер с этим номером записываются данные файла, он становится первым кластером файла. Если файл умещается в одном кластере, то в указатель, соответствующий данному кластеру, заносится специальное значение «последний кластер файла». Если же размер файла больше одного кластера, то ОС продолжает просмотр FAT и ищет следующий указатель на свободный кластер. После его обнаружения в предыдущий указатель заносится номер этого кластера, который теперь становится следующим кластером файла. Процесс повторяется до тех пор, пока не будут размещены все данные файла. Таким образом создается связный список всех кластеров файла.
В начальный период после форматирования файлы будут размещаться в последовательных кластерах области данных, однако после определенного количества удалений файлов кластеры одного файла окажутся в произвольных местах области данных, чередуясь с кластерами других файлов (рис. 7.14).
Размер таблицы FAT и разрядность используемых в ней индексных указателей определяется количеством кластеров в области данных. Для уменьшения потерь из-за фрагментации желательно кластеры делать небольшими, а для сокращения объема адресной информации и повышения скорости обмена наоборот — чем больше, тем лучше. При форматировании диска под файловую систему FAT обычно выбирается компромиссное решение и размеры кластеров выбираются из диапазона от 1 до 128 секторов, или от 512 байт до 64 Кбайт.
Очевидно, что разрядность индексного указателя должна быть такой, чтобы в нем можно было задать максимальный номер кластера для диска определенного объема. Существует несколько разновидностей FAT, отличающихся разрядностью индексных указателей, которая и используется в качестве условного обозначения: FAT12, FAT16 и FAT32. В файловой системе FAT12 используются 12-разрядные указатели, что позволяет поддерживать до 4096 кластеров в области данных диска1, в FAT16 — 16-разрядные указатели для 65 536 кластеров и в FAT32 — 32-разрядные для более чем 4 миллиардов кластеров.
1 Реально это число немного меньше, так как несколько значений индексного указателя расходуется для идентификации специальных ситуаций, таких как «Последний кластер», «Неиспользуемый кластер», «Дефектный кластер» и «Резервный кластер».
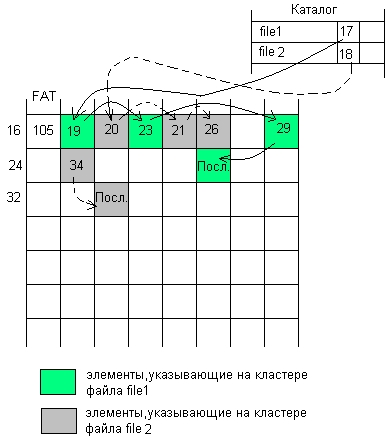
Рис. 7.14. Списки указателей файлов в FAT
Форматирование FAT 12 обычно характерно только для небольших дисков объемом не более 16 Мбайт, чтобы не использовать кластеры более 4 Кбайт. По этой же причине считается, что FAT 16 целесообразнее для дисков с объемом не более 512 Мбайт, а для больших дисков лучше подходит FAT32, которая способна использовать кластеры 4 Кбайт при работе с дисками объемом до 8 Гбайт и только для дисков большего объема начинает использовать 8, 16 и 32 Кбайт. Максимальный размер раздела FAT 16 ограничен 4 Гбайт, такой объем дает 65 536 кластеров по 64 Кбайт каждый, а максимальный размер раздела FAT32 практически не ограничен — 232 кластеров по 32 Кбайт.
Таблица FAT при фиксированной разрядности индексных указателей имеет переменный размер, зависящий от объема области данных диска.
При удалении файла из файловой системы FAT в первый байт соответствующей записи каталога заносится специальный признак, свидетельствующий о том, что эта запись свободна, а во все индексные указатели файла заносится признак «кластер свободен». Остальные данные в записи каталога, в том числе номер первого кластера файла, остаются нетронутыми, что оставляет шансы для восстановления ошибочно удаленного файла. Существует большое количество утилит для восстановления удаленных файлов FAT, выводящих пользователю список имен удаленных файлов с отсутствующим первым символом имени, затертым после освобождения записи. Очевидно, что надежно можно восстановить только файлы, которые были расположены в последовательных кластерах диска, так как при отсутствии связного списка выявить принадлежность произвольно расположенного кластера удаленному файлу невозможно (без анализа содержимого кластеров, выполняемого пользователем «вручную»).
Резервная копия FAT всегда синхронизируется с основной копией при любых операциях с файлами, поэтому резервную копию нельзя использовать для отмены ошибочных действий пользователя, выглядевших с точки зрения системы вполне корректными. Резервная копия может быть полезна только в том случае, когда секторы основной памяти оказываются физически поврежденными и не читаются.
Используемый в FAT метод хранения адресной информации о файлах не отличается большой надежностью — при разрыве списка индексных указателей в одном месте, например из-за сбоя в работе программного кода ОС по причине внешних электромагнитных помех, теряется информация обо всех последующих кластерах файла.
Файловые системы FAT12 и FAT16 оперировали с именами файлов, состоящими из 12 символов по схеме «8.3». В версии FAT16 операционной системы Windows NT был введен новый тип записи каталога — «длинное имя», что позволяет использовать имена длиной до 255 символов, причем каждый символ длинного имени хранится в двухбайтном формате Unicode. Имя по схеме «8.3», названное теперь коротким (не нужно путать его с простым именем файла, также называемого иногда коротким), по-прежнему хранится в 12-байтовом поле имени файла в записи каталога, а длинное имя помещается порциями по 13 символов в одну или несколько записей, следующих непосредственно за основной записью каталога. Каждый символ в формате Unicode кодируется двумя байтами, поэтому 13 символов занимают 26 байт, а оставшиеся 6 отведены под служебную информацию. Таким образом у файла появляются два имени — короткое, для совместимости со старыми приложениями, не понимающими длинных имен в Unicode, и длинное, удобное в использовании имя. Файловая система FAT32 также поддерживает короткие и длинные имена.
Файловые системы FAT12 и FAT16 получили большое распространение благодаря их применению в операционных системах MS-DOS и Windows 3.x — самых массовых операционных системах первого десятилетия эры персональных компьютеров. По этой причине эти файловые системы поддерживаются сегодня и другими ОС, такими как UNIX, OS/2, Windows NT/2000 и Windows 95/98. Однако из-за постоянно растущих объемов жестких дисков, а также возрастающих требований к надежности, эти файловые системы быстро вытесняются как системой FAT32, впервые появившейся в Windows 95 OSR2, так и файловыми системами других типов.
Физическая организация s5 и ufs
Файловые системы s5 (получившие название от System V, родового имени нескольких версий ОС UNIX, разработанных в Bell Labs компании AT&T) и ufs (UNIX File System) используют очень близкую физическую модель. Это не удивительно, так как система ufs является развитием системы s5. Файловая система ufs расширяет возможности s5 по поддержке больших дисков и файлов, а также повышает ее надежность.
ВНИМАНИЕ
В этом разделе вместо термина «кластер» будет использоваться термин «блок», как это принято в файловых системах UNIX.
Расположение файловой системы s5 на диске иллюстрирует рис. 7.15. Раздел диска, где размещается файловая система, делится на четыре области:
Рис. 7.15. Расположение файловой системы s5 на диске
Основной особенностью физической организации файловой системы s5 является отделение имени файла от его характеристик, хранящихся в отдельной структуре, называемой индексным дескриптором (inode). Индексный дескриптор в s5 имеет размер 64 байта и содержит данные о типе файла, адресную информацию, привилегии доступа к файлу и некоторую другую информацию:
Каждый индексный дескриптор имеет номер, который одновременно является уникальным именем файла. Индексные дескрипторы расположены в особой области диска в строгом соответствии со своими номерами. Соответствие между полными символьными именами файлов и их уникальными именами устанавливается с помощью иерархии каталогов. Система ведет список номеров свободных индексных дескрипторов. При создании файла ему выделяется номер из этого списка, а при уничтожении файла номер его индексного дескриптора возвращается в список.
Запись о файле в каталоге состоит всего из двух полей: символьного имени файла и номера индексного дескриптора. Например, на рис. 7.16 показана информация, содержащаяся в каталоге /user.
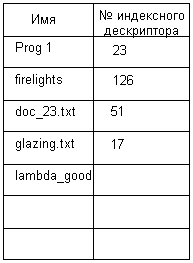
Рис. 7.16. Структура каталога в файловой системе s5
Файловая система не накладывает особых ограничений на размер корневого каталога, так как он расположен в области данных и может увеличиваться как обычный файл.
Доступ к файлу осуществляется путем последовательного просмотра всей цепочки каталогов, входящих в полное имя файла, и соответствующих им индексных дескрипторов. Поиск завершается после получения всех характеристик из индексного дескриптора заданного файла.
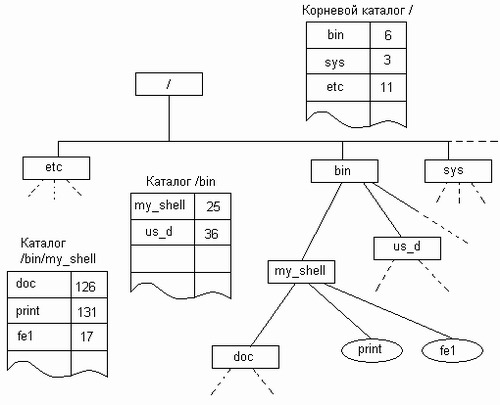
Рис. 7.17. Поиск адреса файла по его символьному имени
Рассмотрим эту процедуру на примере файла /bin/my_shell/print, входящего в состав файловой системы, изображенной на рис. 7.17. Определение физического адреса этого файла включает следующие этапы.
1. Прежде всего просматривается корневой каталог с целью поиска первой составляющей символьного имени — bin. Определяется номер (в данном примере — 6) индексного дескриптора каталога, входящего в корневой каталог. Адрес корневого каталога известен системе.
2. Из области индексных дескрипторов считывается дескриптор с номером 6. Начальный адрес дескриптора определяется на основании известных системе номера начального сектора области индексных дескрипторов и размера индексного дескриптора. Из индексного дескриптора 6 определяется физический адрес каталога /bin.
3. Просматривается каталог /bin с целью поиска второй составляющей символьного имени my_shell. Определяется номер индексного дескриптора каталога /bin/my_shell (в данном случае — 25).
4. Считывается индексный дескриптор 25, определяется физический адрес /bin/my_shell.
5. Просматривается каталог /bin/my_shell, определяется номер индексного дескриптора файла print (в данном случае — 131).
6. Из индексного дескриптора 131 определяются номера блоков данных, а также другие характеристики файла /bin/my_shell/print.
Эта процедура требует в общем случае нескольких обращений к диску, пропорционально числу составляющих в полном имени файла. Для уменьшения среднего времени доступа к файлу его дескриптор копируется в специальную системную область оперативной памяти. Копирование индексного дескриптора входит в процедуру открытия файла.
Физическая организация файловой системы ufs отличается от описанной физической организации файловой системы s5 тем, что раздел состоит из повторяющейся несколько раз последовательности областей «загрузчик—суперблок—блок группы цилиндров—область индексных дескрипторов» (рис. 7.18).

Рис. 7.18. Физическая организация файловой системы ufs
В этих повторяющихся последовательностях областей суперблок является резервной копией основной первой копии суперблока. При повреждении основной копии суперблока может быть использована резервная копия суперблока. Области же блока группы цилиндров и индексных дескрипторов содержат индивидуальные для каждой последовательности значения. Блок группы цилиндров описывает количество индексных дескрипторов и блоков данных, расположенных на данной группе цилиндров диска. Такая группировка делается для ускорения доступа, чтобы просмотр индексных дескрипторов и данных файлов, описываемых этими дескрипторами, не приводил к слишком большим перемещениям головок диска.
Кроме того, в ufs имена файлов могут иметь длину до 255 символов (кодировка ASCII, по одному байту на символ), в то время как в s5 длина имени не может превышать 14 символов.
Файловая система NTFS была разработана в качестве основной файловой системы для ОС Windows NT в начале 90-х годов с учетом опыта разработки файловых систем FAT и HPFS (основная файловая система для OS/2), а также других существовавших в то время файловых систем. Основными отличительными свойствами NTFS являются:
Структура тома NTFS
В отличие от разделов FAT и s5/ufs все пространство тома1 NTFS представляет собой либо файл, либо часть файла. Основой структуры тома NTFS является главная таблица файлов (Master File Table, MFT), которая содержит по крайней мере одну запись для каждого файла тома, включая одну запись для самой себя. Каждая запись MFT имеет фиксированную длину, зависящую от объема диска, — 1,2 или 4 Кбайт. Для большинства дисков, используемых сегодня, размер записи MFT равен 2 Кбайт, который мы далее будет считать размером записи по умолчанию.
Все файлы на томе NTFS идентифицируются номером файла, который определяется позицией файла в MFT. Этот способ идентификации файла близок к способу, используемому в файловых системах s5 и ufs, где файл однозначно идентифицируется номером его записи в области индексных дескрипторов.
Весь том NTFS состоит из последовательности кластеров, что отличает эту файловую систему от рассмотренных ранее, где на кластеры делилась только область данных. Порядковый номер кластера в томе NTFS называется логическим номером кластера {Logical Cluster Number, LCN). Файл NTFS также состоит из последовательности кластеров, при этом порядковый номер кластера внутри файла называется виртуальным номером кластера (Virtual Cluster Number, VCN).
1 В Windows NT логический раздел принято называть томом.
Базовая единица распределения дискового пространства для файловой системы NTFS — непрерывная область кластеров, называемая отрезком. В качестве адреса отрезка NTFS использует логический номер его первого кластера, а также количество кластеров в отрезке k, то есть пара (LCN, k). Таким образом, часть файла, помещенная в отрезок и начинающаяся с виртуального кластера VCN, характеризуется адресом, состоящим из трех чисел: (VCN, LCN, k).
Для хранения номера кластера в NTFS используются 64-разрядные указатели, что дает возможность поддерживать тома и файлы размером до 264 кластеров. При размере кластера в 4 Кбайт это позволяет использовать тома и файлы, состоящие из 64 миллиардов килобайт.
Структура тома NTFS показана на рис. 7.19. Загрузочный блок тома NTFS располагается в начале тома, а его копия — в середине тома. Загрузочный блок содержит стандартный блок параметров BIOS, количество блоков в томе, а также начальный логический номер кластера основной копии MFT и зеркальную копию MFT.
Рис. 7.19. Структура тома NTFS
Далее располагается первый отрезок MFT, содержащий 16 стандартных, создаваемых при форматировании записей о системных файлах NTFS. Назначение этих файлов описано в показанной ниже таблице MFT.
| Номер записи | Системный файл | Имя файла | Назначение файла |
|
0 |
Главная таблица файлов |
$Mft |
Содержит полный список файлов тома NTFS |
|
1 |
Копия главной таблицы файлов |
SMftMirr |
Зеркальная копия первых трех записей MFT |
|
2 |
Файл журнала |
SLogFile |
Список транзакций, который используется для восстановления файловой системы после сбоев |
|
3 |
Том |
SVolume |
Имя тома, версия NTFS и другая информация о томе |
|
4 |
Таблица определения атрибутов |
SAttrDef |
Таблица имен, номеров и описаний атрибутов |
|
5 |
Индекс корневого каталога |
$. |
Корневой каталог |
|
6 |
Битовая карта кластеров |
SBitmap |
Разметка использованных кластеров тома |
|
7 |
Загрузочный сектор раздела |
SBoot |
Адрес загрузочного сектора раздела |
|
8 |
Файл плохих кластеров |
SBadClus |
Файл, содержащий список всех обнаруженных на томе плохих кластеров |
|
9 |
Таблица квот |
SQuota |
Квоты используемого пространства на диске для каждого пользователя |
|
10 |
Таблица преобразования регистра символов |
SUpcase |
Используется для преобразования регистра символов для кодировки Unicode |
|
11-15 |
Зарезервированы для будущего использования |
В NTFS файл целиком размещается в записи таблицы MFT, если это позволяет сделать его размер. В том же случае, когда размер файла больше размера записи MFT, в запись помещаются только некоторые атрибуты файла, а остальная часть файла размещается в отдельном отрезке тома (или нескольких отрезках). Часть файла, размещаемая в записи MFT, называется резидентной частью, а остальные части — нерезидентными. Адресная информация об отрезках, содержащих нерезидентные части файла, размещается в атрибутах резидентной части.
Некоторые системные файлы являются полностью резидентными, а некоторые имеют и нерезидентные части, которые располагаются после первого отрезка MFT. Нулевая запись MFT содержит описание самой MFT, в том числе и такой ее важный атрибут, как адреса всех ее отрезков. После форматирования MFT состоит из одного отрезка, но после создания первого же несистемного файла для хранения его атрибутов требуется еще один отрезок, так как изначально непрерывная последовательность кластеров MFT уже завершена системными файлами.
Из приведенного описания видно, что сама таблица MFT рассматривается как файл, к которому применим метод размещения в томе в виде набора произвольно расположенных нескольких отрезков.
Структура файлов NTFS
Каждый файл и каталог на томе NTFS состоит из набора атрибутов. Важно отметить, что имя файла и его данные также рассматриваются как атрибуты файла, то есть в трактовке NTFS кроме атрибутов у файла нет никаких других компонентов.
Каждый атрибут файла NTFS состоит из полей: тип атрибута, длина атрибута, значение атрибута и, возможно, имя атрибута. Тип атрибута, длина и имя образуют заголовок атрибута.
Имеется системный набор атрибутов, определяемых структурой тома NTFS. Системные атрибуты имеют фиксированные имена и коды их типа, а также определенный формат. Могут применяться также атрибуты, определяемые пользователями. Их имена, типы и форматы задаются исключительно пользователем. Атрибуты файлов упорядочены по убыванию кода атрибута, причем атрибут одного и того же типа может повторяться несколько раз. Существуют два способа хранения атрибутов файла — резидентное хранение в записях таблицы MFT и нерезидентное хранение вне ее, во внешних отрезках. Таким образом, резидентная часть файла состоит из резидентных атрибутов, а нерезидентная — из нерезидентных атрибутов. Сортировка может осуществляться только по резидентным атрибутам.
Системный набор включает следующие атрибуты:
Файлы NTFS в зависимости от способа размещения делятся на небольшие, большие, очень большие и сверхбольшие.
Небольшие файлы (small). Если файл имеет небольшой размер, то он может целиком располагаться внутри одной записи MFT, имеющей, например, размер 2 Кбайт. Небольшие файлы NTFS состоят по крайней мере из следующих атрибутов (рис. 7.20):
Из-за того что файл может иметь переменное количество атрибутов, а также из-за переменного размера атрибутов нельзя наверняка утверждать, что файл уместится внутри записи. Однако обычно файлы размером менее 1500 байт помещаются внутри записи MFT (размером 2 Кбайт).
Рис. 7.20. Небольшой файл NTFS
Большие файлы (large). Если данные файла не помещаются в одну запись МЕТ, то этот факт отражается в заголовке атрибута Data, который содержит признак того, что этот атрибут является нерезидентным, то есть находится в отрезках вне таблицы MFT. В этом случае атрибут Data содержит адресную информацию (LCN, VCN, k) каждого отрезка данных (рис. 7.21).
Рис. 7.21. Большой файл
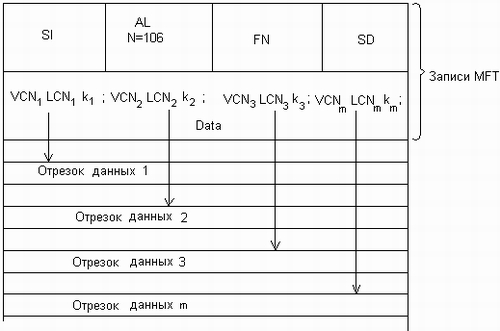
Рис. 7.22. Очень большой файл
Сверхбольшие файлы (extremely huge). Для сверхбольших файлов в атрибуте Attribute List можно указать несколько атрибутов, расположенных в дополнительных записях MFT (рис. 7.23). Кроме того, можно использовать двойную косвенную адресацию, когда нерезидентный атрибут будет ссылаться на другие нерезидентные атрибуты, поэтому в NTFS не может быть атрибутов слишком большой для системы длины.
Очень большие файлы (huge). Если файл настолько велик, что его атрибут данных, хранящий адреса нерезидентных отрезков данных, не помещается в одной записи, то этот атрибут помещается в другую запись MFT, а ссылка на такой атрибут помещается в основную запись файла (рис. 7.22). Эта ссылка содержится в атрибуте Attribute List. Сам атрибут данных по-прежнему содержит адреса нерезидентных отрезков данных.
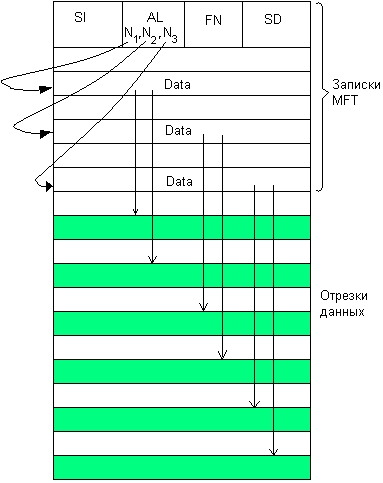
Рис. 7.23. Сверхбольшой файл
Каталоги NTFS
Каждый каталог NTFS представляет собой один вход в таблицу MFT, который содержит атрибут Index Root. Индекс содержит список файлов, входящих в каталог. Индексы позволяют сортировать файлы для ускорения поиска, основанного на значении определенного атрибута. Обычно в файловых системах файлы сортируются по имени. NTFS позволяет использовать для сортировки любой атрибут, если он хранится в резидентной форме.
Имеются две формы хранения списка файлов.
Небольшие каталоги (small indexes). Если количество файлов в каталоге невелико, то список файлов может быть резидентным в записи в MFT, являющейся каталогом (рис. 7.24). Для резидентного хранения списка используется единственный атрибут — Index Root. Список файлов содержит значения атрибутов файла. По умолчанию — это имя файла, а также номер записи MTF, содержащей начальную запись файла.
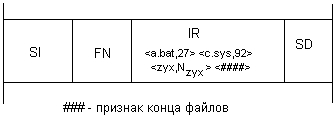
Рис. 7.24. Небольшой каталог
Большие каталоги (large indexes). По мере того как каталог растет, список файлов может потребовать нерезидентной формы хранения. Однако начальная часть списка всегда остается резидентной в корневой записи каталога в таблице MFT (рис. 7.25). Имена файлов резидентной части списка файлов являются узлами так называемого В-дерева (двоичного дерева). Остальные части списка файлов размещаются вне MFT. Для их поиска используется специальный атрибут Index Allocation, представляющий собой адреса отрезков, хранящих остальные части списка файлов каталога. Одни части списков являются листьями дерева, а другие являются промежуточными узлами, то есть содержат наряду с именами файлов атрибут Index Allocation, указывающий на списки файлов более низких уровней.
Узлы двоичного дерева делят весь список файлов на несколько групп. Имя каждого файла-узла является именем последнего файла в соответствующей группе. Считается, что имена файлов сравниваются лексикографически, то есть сначала принимаются во внимание коды первых символов двух сравниваемых имен, при этом имя считается меньшим, если код его первого символа имеет меньшее арифметическое значение, при равенстве кодов первых символов сравниваются коды вторых символов имен и т. д. Например, файл f 1 .ехе, являющийся первым узлом двоичного дерева, показанного на рис. 7.25, имеет имя, лексикографически большее имен avia.exe, az.exe,..., emax.exe, образующих первую группу списка имен каталога. Соответственно файл ltr.exe имеет наибольшее имя среди всех имен второй группы, а все файлы с именами, большими ltr.exe, образуют третью и последнюю группу.
Поиск в каталоге уникального имени файла, которым в NTFS является номер основной записи о файле в MFT, по его символьному имени происходит следующим образом. Сначала искомое символьное имя сравнивается с именем первого узла в резидентной части индекса. Если искомое имя меньше, то это означает, что его нужно искать в первой нерезидентной группе, для чего из атрибута
Index Allocation извлекается адрес отрезка (VCNj, LCN^ K!), хранящего имена файлов первой группы. Среди имен этой группы поиск осуществляется прямым перебором имен и сравнением до полного совпадения всех символов искомого имени с хранящимся в каталоге именем. При совпадении из каталога извлекается номер основной записи о файле в MFT и остальные характеристики файла берутся уже оттуда.
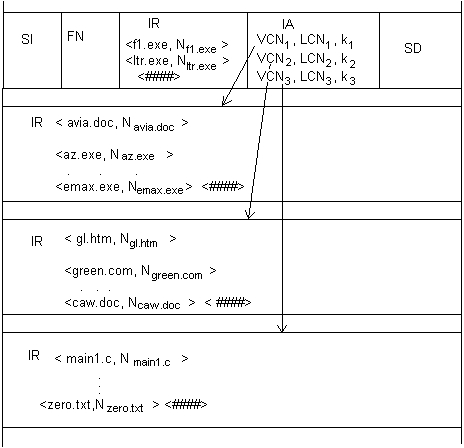
Рис. 7.25. Большой каталог
Если же искомое имя больше имени первого узла резидентной части индекса, то его сравнивают с именем второго узла, и если искомое имя меньше, то описанная процедура применяется ко второй нерезидентной группе имен, и т. д.
В результате вместо перебора большого количества имен (в худшем случае — всех имен каталога) выполняется сравнение с гораздо меньшим количеством имен узлов и имен в одной из групп каталога.
Если одна из групп каталога становится слишком большой, то ее также делят на группы, последние имена каждой новой группы оставляют в исходном нерезидентном атрибуте Index Root, а все остальные имена новых групп переносят в новые нерезидентные атрибуты типа Index Root (на рисунке этот случай не показан). К исходному нерезидентному атрибуту Index Root добавляется атрибут размещения индекса, указывающий на отрезки индекса новых групп. Если теперь при поиске искомого имени в нерезидентной части индекса первого уровня какое-либо сравнение показывает, что искомое имя оказывается меньше, чем одно из хранящихся там имен, то это говорит о том, что в данном атрибуте точного сравнения имени уже быть не может и нужно перейти к подгруппе имен следующего уровня дерева.
Два способа организации файловых операций
Файловая система ОС должна предоставлять пользователям набор операций работы с файлами, оформленный в виде системных вызовов. Этот набор обычно состоит из таких системных вызовов, как creat (создать файл), read (читать из файла), write (записать в файл) и некоторых других.
Чаще всего с одним и тем же файлом пользователь выполняет не одну операцию, а последовательность операций. Например, при работе текстового редактора с файлом, в котором содержится некоторый документ, пользователь обычно считывает несколько страниц текста, редактирует эти данные и записывает их на место считанных, а затем считывает страницы из другой области файла, и т. п. После большого количества операций чтения и записи пользователь завершает работу с данным файлом и переходит к другому.
Какие бы операции не выполнялись над файлом, ОС необходимо выполнить ряд универсальных для всех операций действий:
1. По символьному имени файла найти его характеристики, которые хранятся в файловой системе на диске.
2. Скопировать характеристики файла в оперативную память, так как только таким образом программный код может их использовать.
3. На основании характеристик файла проверить права пользователя на выполнение запрошенной операции (чтение, запись, удаление, просмотр атрибутов файла).
4. Очистить область памяти, отведенную под временное хранение характеристик файла.
Кроме того, каждая операция включает ряд уникальных для нее действий, например чтение определенного набора кластеров диска, удаление файла и т. п.
Операционная система может выполнять последовательность действий над файлом двумя способами (рис. 7.26):
Подавляющее большинство файловых систем поддерживает второй способ организации файловых операций как более экономичный и быстрый. Первый способ обладает одним преимуществом — он более устойчив к сбоям в работе системы, так как каждая операция является самодостаточной и не зависит от результата предыдущей. Поэтому первый способ иногда применяется в распределенных сетевых файловых системах (например, в Network File System, NFS компании Sun), когда сбои из-за потерь пакетов или отказов одного из сетевых узлов более вероятны, чем при локальном доступе к файлам.
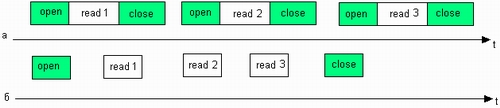
Рис. 7.26. Два способа выполнения файловых операций
При втором способе в файловой системе вводятся два специальных системных вызова: open — открытие файла, и close — закрытие файла.
Системный вызов открытия файла open выполняется перед началом любой последовательности операций с файлом, а вызов закрытия файла close — после окончания работы с файлом. Основной задачей вызова open является преобразование символьного имени файла в его уникальное числовое имя, копирование характеристик файла из дисковой области в буфер оперативной памяти и проверка прав пользователя на выполнение запрошенной операции. Вызов close освобождает буфер с характеристиками файла и делает невозможным продолжение операций с файлом без его повторного открытия.
Операции открытия и закрытия файла в той или иной форме утвердились в операционных системах очень давно. Даже в такой «старой» операционной системе, как OS/360, существовала макрокоманда OPEN, по которой в специальном буфере, называемом DCB (Data Control Block), собирались из различных источников все нужные характеристики набора данных (понятие, близкое к современному понятию файла), используемые затем при выполнении операций чтения и записи.
Далее основные системные вызовы файловых операций рассматриваются более детально на примере их реализации в ОС UNIX, в которой они приобрели тот вид, который сегодня поддерживается практически всеми операционными системами.
Системный вызов open в ОС UNIX работает с двумя аргументами: символьным именем открываемого файла и режимом открытия файла. Режим открытия говорит системе, какие операции будут выполняться над файлом в последовательности операций до закрытия файла по системному вызову close, например: только чтение, только запись или чтение и запись.
При открытии файла ОС сначала выполняет преобразование первого аргумента системного вызова, то есть символьного имени файла, в его уникальное числовое имя, которым в традиционных файловых системах UNIX является номер индексного дескриптора. Эта процедура была рассмотрена выше при описании файловой системы s5.
По номеру индексного дескриптора inode файловая система находит нужную запись на диске и копирует из нее характеристики файла в оперативную память.
Для хранения копии индексного дескриптора используются буферные области системного виртуального пространства. Характеристики индексного дескриптора, перенесенные в оперативную память, помещаются в структуру так называемого виртуального дескриптора vnode (virtual node). Структура vnode включает поля индексного дескриптора файла inode, а также несколько перечисленных ниже дополнительных полей, полезных при выполнении операций с файлом.
- заблокирован ли файл;
- ждет ли снятия блокировки с файла какой-либо процесс;
- отличается ли представление характеристик файла в памяти от своей дисковой копии в результате изменения содержимого индексного дескриптора;
- отличается ли представление файла в памяти от своей дисковой копии в результате изменения содержимого файла;
- является ли файл точкой монтирования.
С одним и тем же файлом в какой-то период времени могут работать различные процессы, но операционная система не создает для каждого процесса отдельную копию структуры vnode, а для каждого файла, с которым в данный момент работает хотя бы один процесс, хранит ровно одну копию виртуального дескриптора. При очередном открытии файла ОС проверяет, имеется ли в системной памяти структура vnode открываемого файла (по номеру логического устройства и номеру индексного дескриптора, которые определяются при преобразовании символьного имени), и если имеется, то счетчик ссылок на нее увеличивается на единицу. При очередном закрытии этого файла счетчик ссылок уменьшается на единицу, и если он становится равным О, то буфер, хранящий данный vnode, считается свободным.
Использование единственной копии характеристик файла и некоторых характеристик файловых операций (например, признака блокировки), общих для всех работающих с файлом процессов, экономит системную память. Тем не менее существуют характеристики, индивидуальные для каждого процесса, выполняющего некоторую последовательность операций с определенным файлом. Для их хранения в UNIX используется структура типа file, которая так же, как и vnode, хранится в системной области памяти.
При каждом открытии процессом файла ОС проверяет права пользовательского процесса на выполнение запрошенной операции с файлом и, если проверка прошла успешно, создает в системной области памяти новую структуру f i I e, которая описывает как открытый файл, так и операции, которые процесс собирается производить с файлом (например, чтение).
Структура file содержит такие поля, как:
Переменная offset, хранящаяся в структуре file, позволяет ОС запоминать текущее положение условного указателя в последовательности байт файла. При открытии файла эта переменная указывает на начальный или конечный байт файла в зависимости от заданного режима открытия. После выполнения операций чтения или записи указатель сдвигается на то количество байт, которое было прочитано или записано в результате операции. Следующая операция застает указатель в том состоянии, в котором его оставила предыдущая операция. Прикладной программист может явно управлять положением указателя с помощью системного вызова lseek, который будет рассмотрен ниже.
При каждом новом открытии какого-либо файла ОС создает новую структуру file и помещает ее в дважды связанный список (рис. 7.27). Обычно под хранение структур file в системной области отводится ограниченная область, поэтому общее количество открытых файлов всеми процессами в любой момент ограничено.
После создания структуры file операционная система помещает указатель на нее в таблицу открытых файлов процесса, которая находится в контексте процесса. Если процесс несколько раз открывает один и тот же файл, то структура file создается для каждой операции открытия. Так как контекст процесса-родителя в UNIX наследуется процессом-потомком, то потомок наследует и указатели на все открытые родителем файлы, получая возможность выполнять над ними операции.
Системный вызов open возвращает в пользовательский процесс дескриптор файла, который представляет собой номер записи в таблице открытых файлов процесса. Дескриптор файла имеет локальное значение только для того процесса, который открыл файл, для разных процессов одно и то же значение дескриптора указывает на разные операции, в общем случае над разными файлами.
После открытия файла его дескриптор используется во всех дальнейших операциях с файлом вплоть до явного закрытия файла. Таким образом, дескриптор файла является временным уникальным именем, но не файла, а определенной последовательности операций с этим файлом.
Для открытия файла /bin/prog1.ехе в режиме «только для чтения» прикладной программист может использовать следующее выражение на языке С:
fd =open("'/bin/progl.exe". 0_RDONLY):
Здесь fd — это целочисленная переменная, сохраняющая значение дескриптора открытого файла. Ее значение должно использоваться в операциях обмена данными с файлом /bin/prog1 .exe. При неудачной попытке открытия файла (нет прав для выполнения затребованной операции, неверное имя файла) переменной fd присваивается значение -1, которое является индикатором ошибки для всех системных вызовов UNIX.
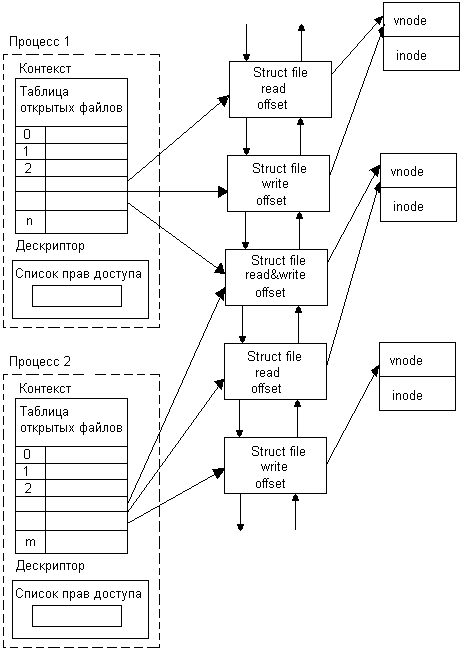
Рис. 7.27. Связь процесса с открытыми файлами
Для обмена данными с предварительно открытым файлом в ОС UNIX существуют системные вызовы read и write. В том случае, когда необходимо явным образом указать, с какого байта файла необходимо читать или записывать данные, используется также системный вызов lseek.
Системный вызов чтения данных из файла read имеет три аргумента:
read(fd,buffer,nbytes);
Первый аргумент fd является целочисленной переменной, имеющей значение дескриптора открытого файла. Второй аргумент buffer является указателем на область пользовательской памяти, в которую система должна поместить считанные данные. Количество байт этой области памяти задается третьим целочисленным аргументом nbytes. Функция read возвращает действительное количество считанных байт (оно может отличаться от заданного, если, например, была задана область чтения, выходящая за пределы файла) или же код ошибки -1.
Начало дисковой области, которую нужно прочитать с помощью вызова read, явно в этом системном вызове не указывается. Чтение начинается с того байта, на который указывает смещение offset в структуре file. На это смещение указывает запись с номером fd в таблице открытых файлов процесса. После выполнения вызова read смещение offset наращивается на количество прочитанных байт.
Вид системного вызова записи данных write аналогичен вызову read:
write(fd.buffer.nbytes):
Функция write записывает nbytes из буфера оперативной памяти buffer в файл, описываемый дескриптором fd. Функция write, так же как и read, возвращает вызвавшей ее программе значение реально переданных ею байт или код ошибки.
Рассмотрим пример, в котором прикладная программа работает с файлом, состоящем из записей фиксированной длины в 50 байт:
fd =open("/doc/qwery/basel2.txt". 0_RDWR):
readCfd.bufferl.50):
read(fd.buffer2.2500):
lseekCfd,150.0): write (fd.output. 300):
close(fd):
В приведенном фрагменте программы после открытия файла /doc/query/base12.txt для чтения и записи выполняется чтение первой записи файла, а затем читается область файла, включающая еще 50 записей, начиная со 2 по 51. После обработки считанных записей (эти инструкции опущены) производятся перемещение указателя смещения в файле на начало четвертой записи и запись результатов в шесть последовательных записей, начиная с четвертой. Завершается фрагмент закрытием файла с помощью системного вызова close.
Все описанные системные вызовы являются синхронными, то есть пользовательский процесс переводится в состояние ожидания до тех пор, пока операция ввода-вывода не завершится.
Описанный набор системных вызовов, появившийся в ОС UNIX еще в 70-х годах, стал стандартом де-факто для современных операционных систем. Эти традиционные системные вызовы часто в конкретных ОС дополняются оригинальными системными вызовами ввода-вывода, например операциями
асинхронного типа. На основе системных вызовов ввода-вывода обычно строятся более мощные библиотечные функции ввода-вывода, составляющие прикладной интерфейс ОС.
Блокировки файлов и отдельных записей в файлах являются средством синхронизации между работающими в кооперации процессами, пытающимися использовать один и тот же файл одновременно.
Процессы могут иметь соответствующие права доступа к файлу, но одновременное использование этих прав (в особенности права записи) может привести к некорректным результатам. Примером такой ситуации является одновременное редактирование одного и того же документа несколькими пользователями. Если доступ к файлу не управляется блокировками, то каждый пользователь, который имеет право записи в файл, работает со своей копией данных файла. Результат такого редактирования непредсказуем — он зависит от того, в какой последовательности записывали изменения в файл применяемые пользователями приложения-редакторы.
Многопользовательские операционные системы обычно поддерживают специальный системный вызов, позволяющий программисту установить и проверить блокировки на файл и его отдельные области. В UNIX такой системный вызов называется fcntl. В его аргументах указывается дескриптор файла, для которого нужно установить или проверить блокировки, тип операции (блокирование или проверка, блокирование доступа для чтения или для записи), а также область блокирования — смещение от начала файла и размер в байтах.
При проверке наличия блокировок, установленных другими процессами, вызов fcntl немедленно возвращает управление с сообщением результата. При установке блокировки можно задать два режима работы системного вызова: с переходом процесса в состояние ожидания в том случае, если блокировку установить невозможно (синхронный системный вызов), и с немедленным возвратом в такой ситуации с сообщением отрицательного результата (асинхронный вызов).
Запрошенная блокировка записи не может быть установлена в том случае, если другой процесс уже установил свою блокировку записи на тот же файл. То есть блокировка записи является исключительной. Блокировки чтения не являются исключительными и могут устанавливаться на файл в том случае, если их области действия не перекрываются. Если на какую-то область файла установлена блокировка чтения, то на эту область нельзя установить блокировку записи.
В UNIX существуют два режима действия блокировок — консультативный (advisory) и обязательный (mandatory). Основным рекомендуемым для использования режимом является консультативный. При нем операционная система не занимается блокированием операций с файлом, а только устанавливает признаки блокирования областей в структурах file, поддерживающих операции с файлами. Кооперирующиеся процессы обязательно должны проверять наличие блокировок на файл, чтобы синхронизировать свою работу. Если же блокировки установлены, но процесс не проверяет их, то операционная система не запрещает доступ процесса к файлу, когда процесс делает системные вызовы read или write.
В обязательном режиме запрет на выполнение операции с заблокированным файлом поддерживает операционная система, поэтому процесс в любом случае не получит доступа к такому файлу. Однако при работе в этом режиме операционная система тратит много усилий и времени на его поддержание, поэтому обычно он не рекомендуется.
Стандартные файлы ввода и вывода, перенаправление вывода
В ОС UNIX были введены в свое время такие понятия, как «стандартный файл ввода», «стандартный файл вывода» и «стандартный файл ошибок». Эти три уже открытых файла существуют у любого пользовательского процесса с момента его возникновения. Процесс в любое время может организовать ввод данных из стандартного файла ввода, выполнив следующий системный вызов:
read(stdio. bufer. nbytes);
Здесь stdio — предопределенное имя константы, обозначающей дескриптор стандартного файла ввода.
Аналогично, так как stdout — предопределенное имя дескриптора стандартного файла вывода, процесс может вывести данные в стандартный файл вывода, применив следующий системный вызов:
write(stout. buffer, nbytes):
За стандартным файлом ошибок закреплено имя stderr.
Фактически при создании нового процесса ОС помещает в его таблицу открытых файлов три записи: с номером 0 — для стандартного файла ввода (следовательно, stdin всегда имеет значение 0), с номером 1 — для стандартного файла вывода (stdout=l), и с номером 2 — для стандартного файла ошибок (stderr=2). Соответственно создаются и три структуры типа file, на которые указывают первые три записи таблицы открытых файлов процесса.
В начальный период существования процесса эти три структуры file связываются операционной системой с одним файлом. В качестве этого файла выступает специальный файл — терминал, с которого вошел в систему пользователь. Такое назначение стандартных файлов достаточно естественно. Прикладные программы, запускаемые пользователем в ходе сеанса работы, чаще всего выводят результаты и сообщения об ошибках на экран терминала, за которым работает пользователь, и с клавиатуры этого же терминала считывают команды и другие исходные данные.
Модель стандартных файлов ввода-вывода рассчитана в основном на алфавитно-цифровые терминалы, управление которыми хорошо описывается потоком выводимых байт, который отображается в виде строк символов на экране, а также потоком вводимых байт, порождаемым последовательными нажатиями клавиш.
Наиболее известной программой, широко использующей стандартные файлы ввода-вывода, является интерпретатор команд, называемый также оболочкой (shell) операционной системы. Интерпретатор постоянно читает вводимые пользователем с клавиатуры команды (из стандартного файла ввода) и либо выполняет их самостоятельно, с помощью своих внутренних функций (такие команды называются внутренними), либо интерпретирует команду как имя исполняемого файла на диске, который необходимо запустить на выполнение в качестве отдельного процесса (внешние команды). Сообщения интерпретатор выводит на экран терминала — стандартный файл вывода.
Стандартные файлы ввода и ввода широко используются не только интерпретатором команд; но и самими командами. Многие внутренние и внешние команды устроены так, что они либо читают свои исходные данные из стандартного файла ввода, либо выводят результаты в стандартный файл вывода. Если же команда делает то и другое, она называется фильтром.
Рассмотрим несколько примеров команд UNIX, работающих со стандартными файлами ввода и вывода:
Интерпретатор команд выполняет также такую важную функцию, как перенаправление стандартного ввода и вывода. Под этим понимается замена файла-терминала, используемого по умолчанию в качестве стандартных файлов ввода и вывода, на произвольный файл. Механизм перенаправления основан на том, что приложение не знает, какой именно файл является стандартным, а просто использует определенный дескриптор в качестве указателя на этот файл. Поэтому для перенаправления ввода-вывода достаточно создать процесс выполнения команды с нестандартной связью стандартной записи в таблице открытых файлов.
Перенаправление осуществляется с помощью специальных конструкций командного языка. Для указания интерпретатору о необходимости перенаправить стандартный ввод на файл file используется следующая конструкция:
< file
Для перенаправления стандартного вывода требуется следующая конструкция:
> file
Например, показанная ниже командная строка запишет данные о содержимом каталога dir2 в файл a.txt:
ls dir2 > a.txt
Механизм перенаправления ввода-вывода, введенный ОС UNIX, получил широкое распространение в интерпретаторах команд многих операционных систем, например MS-DOS, Windows, OS/2.
Доступ к файлам как частный случай доступа к разделяемым ресурсам
Файлы — это частный, хотя и самый популярный, вид разделяемых ресурсов, доступ к которым операционная система должна контролировать. Существуют и другие виды ресурсов, с которыми пользователи работают в режиме совместного использования. Прежде всего это различные внешние устройства: принтеры, модемы, графопостроители и т. п. Область памяти, используемая для обмена данными между процессами, также является примером разделяемого ресурса. Да и сами процессы в некоторых случаях выступают в этой роли, например, когда пользователи ОС посылают процессам сигналы, на которые процесс должен реагировать.
Во всех этих случаях действует общая схема: пользователи пытаются выполнить с разделяемым ресурсом определенные операции, а ОС должна решать, имеют ли пользователи на это право. Пользователи являются субъектами доступа, а разделяемые ресурсы — объектами. Пользователь осуществляет доступ к объектам операционной системы не непосредственно, а с помощью прикладных процессов, которые запускаются от его имени. Для каждого типа объектов существует набор операций, которые с ними можно выполнять. Например, для файлов это операции чтения, записи, удаления, выполнения; для принтера — перезапуск, очистка очереди документов, приостановка печати документа и т. д. Система контроля доступа ОС должна предоставлять средства для задания прав пользователей по отношению к объектам дифференцированно по операциям, например, пользователю может быть разрешена операция чтения и выполнения файла, а операция удаления — запрещена.
Во многих операционных системах реализованы механизмы, которые позволяют управлять доступом к объектам различного типа с единых позиций. Так, представление устройств ввода-вывода в виде специальных файлов в операционных системах UNIX является примером такого подхода: в этом случае при доступе к устройствам используются те же атрибуты безопасности и алгоритмы, что и при доступе к обычным файлам и каталогам. Еще дальше продвинулась в этом направлении операционная система Windows NT. В ней используется унифицированная структура — объект безопасности, — которая создается не только для файлов и внешних устройств, но и для любых разделяемых ресурсов: секций памяти, синхронизирующих примитивов типа семафоров и мьютексов и т. п. Это позволяет использовать в Windows NT для контроля доступа к ресурсам любого вида общий модуль ядра — менеджер безопасности.
В качестве субъектов доступа могут выступать как отдельные пользователи, так и группы пользователей. Определение индивидуальных прав доступа для каждого пользователя позволяет максимально гибко задать политику расходования разделяемых ресурсов в вычислительной системе. Однако этот способ приводит в больших системах к чрезмерной загрузке администратора рутинной работой по повторению одних и тех же операций для пользователей с одинаковыми правами. Объединение таких пользователей в группу и задание прав доступа в целом для группы является одним из основных приемов администрирования в больших системах.
У каждого объекта доступа существует владелец. Владельцем может быть как отдельный-' пользователь, так и группа пользователей. Владелец объекта имеет право выполнять с ним любые допустимые для данного объекта операции. Во многих операционных системах существует особый пользователь (superuser, root, administrator), который имеет все права по отношению к любым объектам системы, не обязательно являясь их владельцем. Под таким именем работает администратор системы, которому необходим полный доступ ко всем файлам и устройствам для управления политикой доступа.
Различают два основных подхода к определению прав доступа.
Мандатные системы доступа считаются более надежными, но менее гибкими, обычно они применяются в специализированных вычислительных системах с повышенными требованиями к защите информации. В универсальных системах используются, как правило, избирательные методы доступа, о которых и будет идти речь ниже.
Для определенности будем далее рассматривать механизмы контроля доступа к таким объектам, как файлы и каталоги, но необходимо понимать, что эти же механизмы могут использоваться в современных операционных системах для контроля доступа к объектам любого типа и отличия заключаются лишь в наборе операций, характерных для того или иного класса объектов.
Каждый пользователь и каждая группа пользователей обычно имеют символьное имя, а также уникальный числовой идентификатор. При выполнении процедуры логического входа в систему пользователь сообщает свое символьное имя и пароль, а операционная система определяет соответствующие числовые идентификаторы пользователя и групп, в которые он входит. Вся идентификационные данные, в том числе имена и идентификаторы пользователей и групп, пароли пользователей, а также сведения о вхождении пользователя в группы хранятся в специальном файле (файл /etc/passwd в UNIX) или специальной базе данных (в Windows NT).
Вход пользователя в систему порождает процесс-оболочку, который поддерживает диалог с пользователем и запускает для него другие процессы. Процесс-оболочка получает от пользователя символьное имя и пароль и находит по ним числовые идентификаторы пользователя и его групп. Эти идентификаторы связываются с каждым процессом, запущенным оболочкой для данного пользователя. Говорят, что процесс выступает от имени данного пользователя и данных групп пользователей. В наиболее типичном случае любой порождаемый процесс наследует идентификаторы пользователя и групп от процесса родителя.
Определить права доступа к ресурсу — значит определить для каждого пользователя набор операций, которые ему разрешено применять к данному ресурсу. В разных операционных системах для одних и тех же типов ресурсов может быть определен свой список дифференцируемых операций доступа. Для файловых объектов этот список может включать следующие операции:
Набор файловых операций ОС может состоять из большого количества элементарных операций, а может включать всего несколько укрупненных операций. Приведенный выше список является примером первого подхода, который позволяет весьма тонко управлять правами доступа пользователей, но создает значительную нагрузку на администратора. Пример укрупненного подхода демонстрируют операционные системы семейства UNIX, в которых существуют всего три операции с файлами и каталогами: читать (read, г), писать (write, w) и выполнить (execute, x). Хотя в UNIX для операций используется всего три названия, в действительности им соответствует гораздо больше операций. Например, содержание операции выполнить зависит от того, к какому объекту она применяется. Если операция выполнить файл интуитивно понятна, то операция выполнить каталог интерпретируется как поиск в каталоге определенной записи. Поэтому администратор UNIX, по сути, располагает большим списком операций, чем это кажется на первый взгляд.
В ОС Windows NT разработчики применили гибкий подход — они реализовали возможность работы с операциями над файлами на двух уровнях: по умолчанию администратор работает на укрупненном уровне (уровень стандартных операций), а при желании может перейти на элементарный уровень (уровень индивидуальных операций).
В самом общем случае права доступа могут быть описаны матрицей прав доступа, в которой столбцы соответствуют всем файлам системы, строки — всем пользователям, а на пересечении строк и столбцов указываются разрешенные операции (рис. 7.28).
Рис. 7.28. Матрица прав доступа
Практически во всех операционных системах матрица прав доступа хранится «по частям», то есть для каждого файла или каталога создается так называемый список управления доступом (Access Control List, ACL), в котором описываются права на выполнение операций пользователей и групп пользователей по отношению к этому файлу или каталогу. Список управления доступа является частью характеристик файла или каталога и хранится на диске в соответствующей области, например в индексном дескрипторе inode файловой системы ufs. He все файловые системы поддерживают списки управления доступом, например, его не поддерживает файловая система FAT, так как она разрабатывалась для однопользовательской однопрограммной операционной системы MS-DOS, для которой задача защиты от несанкционированного доступа не актуальна.
Обобщенно формат списка управления доступом можно представить в виде набора идентификаторов пользователей и групп пользователей, в котором для каждого идентификатора указывается набор разрешенных операций над объектом (рис. 7.29). Говорят, что список ACL состоит из элементов управления доступом (Access Control Element, АСЕ), при этом каждый элемент соответствует одному идентификатору. Список ACL с добавленным к нему идентификатором владельца называют характеристиками безопасности.
Рис. 7.29. Проверка прав доступа
В приведенном на рисунке примере процесс, который выступает от имени пользователя с идентификатором 3 и групп с идентификаторами 14, 52 и 72, пытается выполнить операцию записи (W) в файл. Файлом владеет пользователь с идентификатором 17. Операционная система, получив запрос на запись, находит характеристики безопасности файла (на диске или в буферной системной области) и последовательно сравнивает все идентификаторы процесса с идентификатором владельца файла и идентификаторами пользователей и групп в элементах АСЕ. В данном примере один из идентификаторов группы, от имени которой выступает процесс, а именно 52, совпадает с идентификатором одного из элементов АСЕ. Так как пользователю с идентификатором 52 разрешена операция чтения (признак W имеется в наборе операций этого элемента), то ОС разрешает процессу выполнение операции.
Описанная обобщенная схема хранения информации о правах доступа и процедуры проверки имеет в каждой операционной системе свои особенности, которые рассматриваются далее на примере операционных систем UNIX и Windows NT.
Организация контроля доступа в ОС UNIX
В ОС UNIX права доступа к файлу или каталогу определяются для трех субъектов:
С учетом того что в UNIX определены всего три операции над файлами и каталогами (чтение, запись, выполнение), характеристики безопасности файла включают девять признаков, задающих возможность выполнения каждой из трех операций для каждого из трех субъектов доступа. Например, если владелец файла разрешил себе выполнение всех трех операций, для членов группы — чтение и выполнение, а для всех остальных пользователей — только выполнение, то девять характеристик безопасности файла выглядят следующим образом:
rwx r-х r--
Здесь г, w и х обозначают операции чтения, записи и выполнения соответственно. Именно в таком виде выводит информацию о правах доступа к файлам команда просмотра содержимого каталога 1 s. Суперпользователю UNIX все виды доступа позволены всегда, поэтому его идентификатор (он имеет значение 0) не фигурирует в списках управления доступом.
С каждым процессом UNIX связаны два идентификатора: пользователя, от имени которого был создан этот процесс, и группы, к которой принадлежит данный пользователь. Эти идентификаторы носят название реальных идентификаторов пользователя: Real User ID, RUID и реальных идентификаторов группы: Real Group ID, RGID. Однако при проверке прав доступа к файлу используются не эти идентификаторы, а так называемые эффективные идентификаторы пользователя: Effective User ID, EUID и эффективные идентификаторы группы: Effective Group ID, EGID (рис. 7.30).
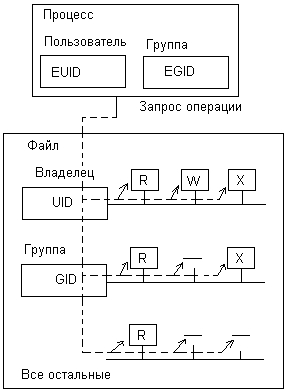
Рис. 7.30. Проверка прав доступа в UNIX
Введение эффективных идентификаторов позволяет процессу выступать в некоторых случаях от имени пользователя и группы, отличных от тех, которые ему достались при рождении. В исходном состоянии эффективные идентификаторы совпадают с реальными.
Случаи, когда процесс выполняет системный вызов ехес запуска приложения, хранящегося в некотором файле, в UNIX связаны со сменой процессом исполняемого кода. В рамках данного процесса начинает выполняться новый код, и если в характеристиках безопасности этого файла указаны признаки разрешения смены идентификаторов пользователя и группы, то происходит смена эффективных идентификаторов процесса. Файл имеет два признака разрешения смены идентификатора — Set User ID on execution (SUID) и Set Group ID on execution (SGID), которые разрешают смену идентификаторов пользователя и группы при выполнении данного файла.
Механизм эффективных идентификаторов позволяет пользователю получать некоторые виды доступа, которые ему явно не разрешены, но только с помощью вполне ограниченного набора приложений, хранящихся в файлах с установленными признаками смены идентификаторов. Пример такой ситуации приведен на рис. 7.31.
Первоначально процесс А имел эффективные идентификаторы пользователя и группы (12 и 23 соответственно), совпадающие с реальными. На каком-то этапе работы процесс запросил выполнение приложения из файла b.ехе. Процесс может выполнить файл b.ехе, хотя его эффективные идентификаторы не совпадают с идентификатором владельца и группы файла, так как выполнение разрешено всем пользователям.
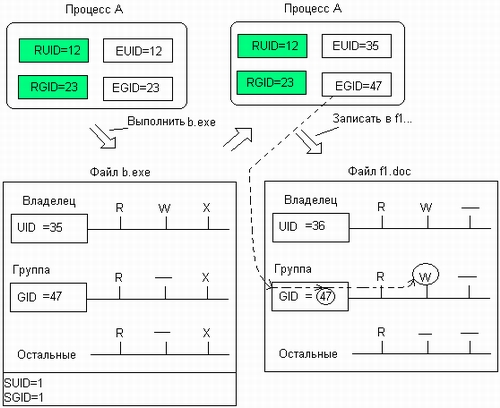
Рис. 7.31. Смена эффективных идентификаторов процесса
Файл Ь.ехе имеет установленные признаки смены идентификаторов SUID и SGID, поэтому одновременно со сменой кода процесс меняет и значения эффективных идентификаторов (35 и 47). Вследствие этого при последующей попытке записать данные в файл f 1 .doc процессу А это удается, так как его новый эффективный идентификатор группы совпадает с идентификатором группы файла f1.doc. Без смены идентификаторов эта операция для процесса А была бы запрещена.
Описанный механизм преследует те же цели, что и рассмотренный выше механизм подчиненных сегментов процессора Pentium.
Использование модели файла как универсальной модели разделяемого ресурса позволяет в UNIX применять одни и те же механизмы для контроля доступа к файлам, каталогам, принтерам, терминалам и разделяемым сегментам памяти.
Система управления доступом ОС UNIX была разработана в 70-е годы и с тех пор мало изменилась. Эта достаточно простая система позволяет во многих случаях решить поставленные перед администратором задачи по предотвращению несанкционированного доступа, однако такое решение иногда требует слишком больших ухищрений или же вовсе не может быть реализовано.
Организация контроля доступа в ОС Windows NT
Общая характеристика
Система управления доступом в ОС Windows NT отличается высокой степенью гибкости, которая достигается за счет большого разнообразия субъектов и объектов доступа, а также детализации операций доступа.
Для разделяемых ресурсов в Windows NT применяется общая модель объекта, который содержит такие характеристики безопасности, как набор допустимых операций, идентификатор владельца, список управления доступом. Объекты в Windows NT создаются для любых ресурсов в том случае, когда они являются или становятся разделяемыми — файлов, каталогов, устройств, секций памяти, процессов. Характеристики объектов в Windows NT делятся на две части — общую часть, состав которой не зависит от типа объекта, и индивидуальную, определяемую типом объекта.
Все объекты хранятся в древовидных иерархических структурах, элементами которых являются объекты-ветви (каталоги) и объекты-листья (файлы). Для объектов файловой системы такая схема отношений является прямым отражением иерархии каталогов и файлов. Для объектов других типов иерархическая схема отношений имеет свое содержание, например, для процессов она отражает связи «родитель-потомок», а для устройств отражает принадлежность к определенному типу устройств и связи устройства с другими устройствами, например SCSI-контроллера с дисками.
Проверка прав доступа для объектов любого типа выполняется централизованно с помощью монитора безопасности (Security Reference Monitor), работающего в привилегированном режиме. Централизация функций контроля доступа повышает надежность средств защиты информации операционной системы по сравнению с распределенной реализацией, когда в различных модулях ОС имеются свои процедуры проверки прав доступа и вероятность ошибки программиста от этого возрастает.
Для системы безопасности Windows NT характерно наличие большого количества различных предопределенных (встроенных) субъектов доступа — как отдельных пользователей, так и групп. Так, в системе всегда имеются такие пользователи, как Administrator, System и Guest, а также группы Users, Administrators, Account Operators, Server Operators, Everyone и другие. Смысл этих встроенных пользователей и групп состоит в том, что они наделены некоторыми правами, облегчая администратору работу по созданию эффективной системы разграничения доступа. При добавлении нового пользователя администратору остается только решить, к какой группе или группам отнести этого пользователя. Конечно, администратор может создавать новые группы, а также добавлять права к встроенным группам для реализации собственной политики безопасности, но во многих случаях встроенных групп оказывается вполне достаточно.
Windows NT поддерживает три класса операций доступа, которые отличаются типом субъектов и объектов, участвующих в этих операциях.
Права и разрешения, данные группе, автоматически предоставляются ее членам, позволяя администратору рассматривать большое количество пользователей как единицу учетной информации и минимизировать свои действия.
Проверка разрешений доступа процесса к объекту производится в Windows NT в основном в соответствии с общей схемой доступа, представленной на рис. 7.29.
При входе пользователя в систему для него создается так называемый токен доступа (access token), включающий идентификатор пользователя и идентификаторы всех групп, в которые входит пользователь. В токене также имеются: список управления доступом (ACL) по умолчанию, который состоит из разрешений и применяется к создаваемым процессом объектам; список прав пользователя на выполнение системных действий.
Все объекты, включая файлы, потоки, события, даже токены доступа, когда они создаются, снабжаются дескриптором безопасности. Дескриптор безопасности содержит список управления доступом — ACL. Владелец объекта, обычно пользователь, который его создал, обладает правом избирательного управления доступом к объекту и может изменять ACL объекта, чтобы позволить или не позволить другим осуществлять доступ к объекту. Встроенный администратор Windows NT в отличие от суперпользователя UNIX может не иметь некоторых разрешений на доступ к объекту. Для реализации этой возможности идентификаторы администратора и группы администраторов могут входить в ACL, как и идентификаторы рядовых пользователей. Однако администратор все же имеет возможность выполнить любые операции с любыми объектами, так как он всегда может стать владельцем объекта, а затем уже как владелец получить полный набор разрешений. Однако вернуть владение предыдущему владельцу объекта администратор не может, поэтому пользователь всегда может узнать о том, что с его файлом или принтером работал администратор.
При запросе процессом некоторой операции доступа к объекту в Windows NT управление всегда передается монитору безопасности, который сравнивает идентификаторы пользователя и групп пользователей из токена доступа с идентификаторами, хранящимися в элементах ACL объекта. В отличие от UNIX в элементах ACL Windows NT могут существовать как списки разрешенных, так и списки запрещенных для пользователя операций.
Система безопасности могла бы осуществлять проверку разрешений каждый раз, когда процесс использует объект. Но список ACL состоит из многих элементов, процесс в течение своего существования может иметь доступ ко многим объектам, и количество активных процессов в каждый момент времени также велико. Поэтому проверка выполняется только при каждом открытии, а не при каждом использовании объекта.
Для смены в некоторых ситуациях процессом своих идентификаторов в Windows NT используется механизм олицетворения (impersonation). В Windows NT существуют простые субъекты и субъекты-серверы. Простой субъект — это процесс, которому не разрешается смена токена доступа и соответственно смена идентификаторов. Субъект-сервер — это процесс, который работает в качестве сервера и обслуживает процессы своих клиентов (например, процесс файлового сервера). Поэтому такому процессу разрешается получить токен доступа у процесса-клиента, запросившего у сервера выполнения некоторого действия, и использовать его при доступе к объектам.
В Windows NT однозначно определены правила, по которым вновь создаваемому объекту назначается список ACL. Если вызывающий код во время создания объекта явно задает все права доступа к вновь создаваемому объекту, то система безопасности приписывает этот ACL объекту.
Если же вызывающий код не снабжает объект списком ACL, а объект имеет имя, то применяется принцип наследования разрешений. Система безопасности просматривает ACL того каталога объектов, в котором хранится имя нового объекта. Некоторые из входов ACL каталога объектов могут быть помечены как наследуемые. Это означает, что они могут быть приписаны новым объектам, создаваемым в этом каталоге.
В том случае, когда процесс не задал явно список ACL для создаваемого объекта и объект-каталог не имеет наследуемых элементов ACL, используется список ACL по умолчанию из токена доступа процесса.
Наследование разрешений употребляется наиболее часто при создании нового объекта. Особенно оно эффективно при создании файлов, так как эта операция выполняется в системе наиболее часто.
Разрешения на доступ к каталогам и файлам
В Windows NT администратор может управлять доступом пользователей к каталогам и файлам только в разделах диска, в которых установлена файловая система NTFS. Разделы FAT не поддерживаются средствами защиты Windows NT, так как в FAT у файлов и каталогов отсутствуют атрибуты для хранения списков управления доступом. Доступ к каталогам и файлам контролируется за счет установки соответствующих разрешений.
Разрешения в Windows NT бывают индивидуальные и стандартные. Индивидуальные разрешения относятся к элементарным операциям над каталогами и файлами, а стандартные разрешения являются объединением нескольких индивидуальных разрешений.
В представленной ниже таблице показано шесть индивидуальных разрешений (элементарных операций), смысл которых отличается для каталогов и файлов.
|
Разрешение |
Для каталога |
Для файла |
|
Read (R) |
Чтение имен файлов и каталогов, входящих в данный ка талог, а также атрибутов и владельца каталога |
Чтение данных, атрибутов, - имени владельца и разрешений файла |
|
Write (W) |
Добавление файлов и каталогов, изменение атрибутов каталога, чтение владельца и разрешений каталога |
• Чтение владельца и разрешений файла, изменение атрибутов файла, изменение и добавление данных файла |
|
Execute (X) |
Чтение атрибутов каталога, выполнение изменений в каталогах, входящих в данный каталог, чтение имени владельца и разрешений каталога |
Чтение атрибутов файла, имени владельца и разрешений. Выполнение файла, если он хранит код программы |
|
Delete (D) |
Удаление каталога |
Удаление файла |
|
Change Permission (P) |
Изменение разрешений каталога |
Изменение разрешений файла |
|
Take Ownership (O) |
Стать владельцем каталога |
Стать владельцем файла |
Для файлов в Windows NT определено четыре стандартных разрешения: No Access, Read, Change и Full Control, которые объединяют индивидуальные разрешения, перечисленные в следующей таблице.
|
Стандартное разрешение |
Индивидуальные разрешения |
|
No Access |
Ни одного |
|
Read |
RX |
|
Change |
RWXD |
|
Full Control |
Все |
Разрешение Full Control отличается от Change тем, что дает право на изменение разрешений (Change Permission) и вступление во владение файлом (Take Ownership).
Для каталогов в Windows NT определено семь стандартных разрешений: No Access, List, Read, Add, Add&Read, Change и Full Control. В следующей таблице показано соответствие стандартных разрешений индивидуальным разрешениям для каталогов, а также то, каким образом эти стандартные разрешения преобразуются в индивидуальные разрешения для файлов, входящих в каталог в том случае, если файлы наследуют разрешения каталога.
|
Стандартные разрешения |
Индивидуальные разрешения для каталога |
Индивидуальные разрешения для файлов каталога при наследовании |
|
No Access |
Ни одного |
Ни одного |
|
List |
RX |
Не определены |
|
Read |
RX |
RX |
|
Add |
WX |
Не определены |
|
Add & Read |
RWX |
RX |
|
Change |
RWXD |
RWXD |
|
Full Control |
Все |
Все |
При создании файла он наследует разрешения от каталога указанным способом только в том случае, если у каталога установлен признак наследования его разрешений. Стандартная оболочка Windows NT — Windows Explorer — не позволяет установить такой признак для каждого разрешения отдельно (то есть задать маску наследования), управляя наследованием по принципу «все или ничего».
Существует ряд правил, которые определяют действие разрешений.
По умолчанию в окнах Windows Explorer находят свое отражение стандартные права, а переход к отражению индивидуальных прав происходит только при выполнении некоторых действий. Это стимулирует администратора и пользователей к использованию тех наборов прав, которые разработчики ОС посчитали наиболее удобными.
Встроенные группы пользователей и их права
Мощность и гибкость системы безопасности Windows NT во многом определяется наличием в ней достаточно широкого набора прав групп пользователей на выполнение системных действий. Для иллюстрации этого утверждения в следующих двух таблицах приводятся списки изменяемых и встроенных прав для встроенных групп Windows NT.
Первой показана таблица изменяемых прав встроенных групп.
В следующей таблице представлены встроенные права встроенных групп.
| Права | Admini- strators | Server Opera- tors | Account Opera- tors | Print Opera- tors | Backup Opera- tors | Every- one | Users | Guests |
|
Log on locally (локаль- ный логиче- ский вход) |
Есть |
Есть |
Есть |
Есть |
Есть |
Нет |
Нет |
Нет |
|
Access this computer from network (доступ к данному компь-
ютеру через сеть) |
Есть |
Нет |
Нет |
Нет |
Нет |
Нет |
Нет |
Нет |
|
Take ownership of files (устано- вление прав собстве-
нности на файлы) |
Есть |
Нет |
Нет |
Нет |
Нет |
Нет |
Нет |
Нет |
|
Manage auditing and security log (управ- ление аудитом
и учетом событий, связан- ных с безопас-
ностью) |
Есть |
Нет |
Нет |
Нет |
Нет |
Есть |
Нет |
Есть |
|
Change the system time (изме- нение систе- много времени) |
Есть |
Есть |
Нет |
Нет |
Нет |
Нет |
Нет |
Есть |
|
Shutdown the system (оста- нов систе- мы) |
Есть |
Есть |
Нет |
Нет |
Есть |
Нет |
Нет |
Нет |
|
Force shutdown from remote system (иници- ирование останова с
удален- ной системы) |
Есть |
Есть |
Нет |
Нет |
Нет |
Нет |
Нет |
Нет |
|
Backup files and directories (резерв- ное копиро- вание файлов и
катало- гов) |
Есть |
Есть |
Есть |
Есть |
Есть |
Нет |
Нет |
Нет |
|
Restore files and directories (восста- новление файлов и
катало- гов со стримера) |
Есть |
Есть |
Нет |
Нет |
Есть |
Нет |
Нет |
Нет |
| Load and unload device drivers (загрузка и выгрузка драй- веров устр-в) | Есть | Нет | Нет | Нет | Нет | Нет | Нет | Нет |
| Add work- station to domain (добавле- ние рабочих станций к домену) | Есть | Нет | Нет | Нет | Нет | Нет | Нет | Нет |
|
Встроенные права |
Administ- rators | Server Opera- tors | Account Opera- tors | Print Opera- tors | Backup Opera- tors | Every- one | Users | Guests |
|
Create and manage user accounts (создание и управление
пользова- тельской учетной информа- цией) |
Нет |
Нет |
Нет |
Нет |
Нет |
Нет |
Нет |
Нет |
|
Create and manage global groups (создание и управление
глобаль- ными группами) |
Нет |
Нет |
Нет |
Нет |
Нет |
Нет |
Нет |
Нет |
|
Assign user rights (назначение прав для пользова-
телей) |
Нет |
Нет |
Нет |
Нет |
Нет |
Есть |
Нет |
Нет |
|
Manage auditing of system events (управление аудитом системных событий) |
Нет |
Нет |
Нет |
Нет |
Нет |
Нет |
Нет |
Нет |
|
Lock the server (блоки- рование сервера) |
Нет |
Нет |
Нет |
Нет |
Нет |
Нет |
Нет |
Нет |
|
Override the lock of the server (преодоле- ние блокировки сервера) |
Есть |
Есть |
Есть |
Нет |
Нет |
Нет |
Нет |
Нет |
|
Format server's hard disk (формати- рование жесткого диска сервера) |
Нет |
Нет |
Нет |
Нет |
Нет |
Есть |
Есть |
Есть |
|
Create common groups (создание общих групп) |
Есть |
Есть |
Есть |
Есть |
Есть |
Есть |
Есть |
Есть |
| Keep local profile (хранение локального профиля) | ||||||||
| Share and stop sharing directories (разделе- ние и прекра- щение разделения каталогов) | ||||||||
| Share and stop sharing printers (разделе- ние и прекра- щение разделения принтеров) |
При создании новых групп администратор может наделить их любым изменяемым правом, но распоряжаться встроенными правами он не может — они являются неотъемлемыми атрибутами встроенных и только встроенных групп.
- организация параллельной работы процессора и устройств ввода-вывода при обеспечении приемлемого уровня реакции каждого драйвера и минимизации общей загрузки процессора;
- согласование скоростей работы процессора, оперативной памяти и устройств ввода-вывода;
- разделение устройств ввода-вывода между процессами; О обеспечение удобного логического интерфейса к устройствам ввода-вывода. Q Подсистема ввода-вывода обычно имеет ярко выраженную многослойную структуру, которая помогает объединить большое количество разнотипных драйверов в систему с общим интерфейсом.
1. За счет каких устройств удается распараллелить ввод-вывод даже в однопроцессорных системах?
2. Какие функции выполняет менеджер ввода-вывода?
3. Какие из следующих утверждений правильны?
4. Какие два типа ресурсов, связанных с диском, требуется выделить процессу, чтобы он выполнил запись данных на диск?
5. Каким из двух типов драйверов — блок-ориентированным или байт-ориентированным — обслуживается диск?
6. С какой целью в некоторых файловых системах характеристики файла отделяются от его имени?
7. Какие программные компоненты поддерживают структуру файла в тех ОС, где файл представлен последовательносью байт?
8. С какого каталога начинается «раскрутка» полного имени файла?
9. Операционная система выделяет файлам пространство на диске:
10. Выберите размер кластера для файловой системы FAT16, устанавливаемой в разделе, который разделен на секторы размером 512 байт и имеет общий объем 272 Мбайт. Оцените, сколько в этом случае кластеров будет содержать область данных, а также какой размер необходимо отвести таблице FAT. Учтите, что размер кластера должен быть равен степени двойки. Примите во внимание также, что стандартным размером корневого каталога для жестких дисков является размер в 32 сектора.
11. При каких условиях можно автоматически гарантированно восстановить в файловой системе FAT удаленный файл?
12. Сформулируйте основную цель введения в ОС системного вызова open.
13. В какой из типов систем управления доступом — избирательной или мандатной — пользователю предоставляется большая свобода действий?
14. Какой смысл имеет операция «выполнить каталог» в ОС UNIX?
15. С помощью какого механизма пользовательский процесс может запускать на выполнение привилегированные утилиты операционной системы UNIX?
16. Чем отличается разрешение Full Control для файлов от разрешения Change в Windows NT?
17. Какие действия по отношению к файлу А разрешены пользователю ОС Windows NT, если он лично имеет разрешение Change, а для группы, в которую он входит, задано разрешение No Access?